

Не делайте вложенных агрегатов
В строгой интерпретации ANSI SQL, вы не можете использовать агрегат агрегата. Предположим что вы хотите выяснить, в какой день имелась наибольшая сумма приобретений. Если вы попробуете сделать это,
SELECT odate, MAX ( SUM (amt) )
FROM Orders
GROUP BY odate;
то ваша команда будет вероятно отклонена. ( Некоторые реализации не предписывают этого ограничения, которое является выгодным, потому что вложенные агрегаты могут быть очень полезны, даже если они и несколько проблематичны.) В вышеупомянутой команде, например, SUM должен применяться к каждой группе пол odate, а MAX ко всем группам, производящим одиночное значение для всех групп. Однако предложение GROUP BY подразумевает что должна иметься одна строка вывода для каждой группы пол odate.
РЕЗЮМЕ
Теперь вы используете запросы несколько по-другому. Способность получать, а не просто размещать значения, очень мощна. Это означает что вы не обязательно должны следить за определенной информацией если вы можете сформулировать запрос так чтобы ее получить. Запрос будет давать вам поминутные результаты, в то врем как таблица общего или среднего значений будет хороша только некоторое врем после ее модификации. Это не должно наводить на мысль, что агрегатные функции могут полностью вытеснить потребность в отслеживании информации такой например как эта. Вы можете применять эти агрегаты для групп значений определенных предложением GROUP BY. Эти группы имеют значение поля в целом, и могут постоянно находиться внутри других групп которые имеют значение поля в целом. В то же время, предикаты еще используются чтобы определять какие строки агрегатной функции применяются. Объединенные вместе, эти особенности делают возможным, производить агрегаты основанные на сильно определенных подмножествах значений в поле. Затем вы можете определять другое условие для исключения определенных результатов групп с предложением HAVING. Теперь , когда вы стали знатоком большого количества того как запрос производит значения, мы покажем вам, в Главе 7, некоторые вещи которые вы можете делать со значениями которые он производит.
22
Ключи и индексы
Как было отмечено выше при описании отношений между таблицами, в реляционных базах данных таблицы связываются друг с другом посредством совпадающих значений ключевых полей. Ключевым полем может быть практически любое поле в таблице. Ключ может быть первичным (primary) или внешним (foreign).
Первичный ключ однозначно определяет запись в таблице. В примере с базой данных BIBLIO.MDB таблицыPUBLISHERS, AUTHORS и TITLES имеют первичные ключи PubID, Au_ID иISBN соответственно. Таблица TITLES также имеет два внешних ключа PubID и Au_ID для связи с таблицамиPUBLISHERS и AUTHORS. Таким образом, первичный ключ однозначно определяет запись в таблице, в то время как внешний ключ используется для связи с первичным ключом другой таблицы.
Ключевой поле может иметь определенный смысл,как например ключ ISBN в таблице TITLES. Однако, очень часто ключевое поле не несет никакой смысловой нагрузки и является просто идентификатором объекта в таблице. Во многих случаях удобно использовать в качестве ключа поле счетчика (Counter field). При этом вся ответственность по поддержанию уникальности ключевого поля снимается с пользователя и перекладывается на процессор баз данных. Поле счетчика представляет собой четырехбайтовое целое число (Long) и автоматически увеличивается на единицу при добавлении пользователем новой записи в таблицу.
Данные запоминаются в таблице в том порядке, в котором они вводятся пользователем. Это, так называемый, физический порядок следования записей. Однако, часто требуется представить данные в другом, отличном от физического,порядке. Например может потребоваться просмотреть данные об авторах книг,упорядоченные по алфавиту. Кроме того, часто необходимо найти в большом объеме информации запись, удовлетворяющую определенному критерию.Простой перебор записей при поиске в большой таблице может потребовать достаточно много времени и поэтому будет неэффективным.
Одними из основных требований, предъявляемым к системам управления базами данных, являются возможность представления данных в определенном, отличном от физического, порядке и возможность быстрого поиска определенной записи. Эффективным средством решения этих задач является использование индексов.
Индекс представляет собой таблицу, которая содержит ключевые значения для каждой записи в таблице данных и записанные в порядке, требуемом для пользователя. Ключевые значения определяются на основе одного или нескольких полей таблицы. Кроме того, индекс содержит уникальные ссылки на соответствующие записи в таблице. На рис.1.12 показан фрагмент таблицы CUSTOMERS,содержащей информацию о покупателях, и индексIDX_NAME, построенный на основе поля Name таблицы CUSTOMERS.Индекс IDX_NAME содержит значения ключевого поля Name,упорядоченные в алфавитном порядке, и ссылки на соответствующие записи в таблице CUSTOMERS.
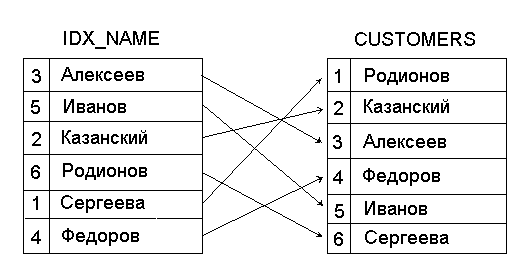 Рис.1.12.
Связь между таблицей и индексом.
Рис.1.12.
Связь между таблицей и индексом.
Каждая таблица может иметь несколько различных индексов, каждый из которых определяет свой собственный порядок следования записей.Например, таблица AUTHORS может иметь индексы для представления данных об авторах, упорядоченные по дате рождения или по алфавиту. Таким образом,каждый индекс используется для представления одних и тех же данных, но упорядоченных различным образом.
Вообще говоря, таблицы в базе данных могут и не иметь индексов. В этом случае для большой таблицы время поиска определенной записи может быть весьма значительным и использование индекса становиться необходимым. С другой стороны, не следует увлекаться созданием слишком большого количества индексов, так как это может заметно увеличить время необходимое для обновления базы данных и значительно увеличить размер файла базы данных.
При разработке приложений, работающих с базами данных, наиболее широко используются простые индексы. Простые индексы используют значения одного поля таблицы. Примером простого индекса в базе данных BIBLIO.MDB может служить код ISBN,идентификатор автора Au_ID или идентификатор издательства PubID.
Хотя в большинстве случаев для представления данных в определенном порядке достаточно использовать простой индекс, часто возникают ситуации, где не обойтись без использования составных индексов. Составной индекс строится на основе значений двух или более полей таблицы.Хорошей иллюстрацией использования составных индексов может служить база данных родственников при генеалогических исследованиях какой-либо фамилии. Понятно, что использование в качестве простого индекса фамилии человека в данном случае недопустимо.Даже использование составного индекса,основанного на полях имени, фамилии и отчества может быть неэффективным, так как и в этом случае все равно возможно существование достаточно большого числа однофамильцев. Выходом из положения может быть использование составного индекса, основанного, например, на следующих полях таблицы: имя, фамилия, отчество, город и номер телефона.
23
Отношения между таблицами
Отношения между таблицами устанавливают связь между данными находящимися в разных таблицах базы данных.
Отношения между таблицами определяются отношением между группами объектов соответствующего типа. Например, один автор может написать несколько книг и издать их в разных издательствах. Или издательство может опубликовать несколько книг разных авторов.Таким образом, между авторами и названиями книг существует отношение один-ко-многим, а между издательствами и авторами существует отношение много-ко-многим.
Отношения между таблицами базы данных BIBLIO.MDBпоказаны на рис.1.9.
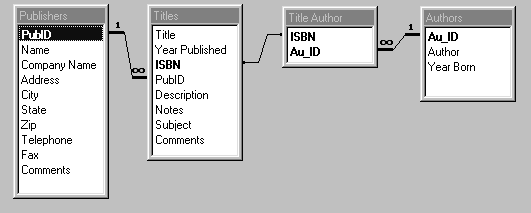 Рис.1.9.
Отношения между таблицами базы данных
BIBLIO.MDB.
Рис.1.9.
Отношения между таблицами базы данных
BIBLIO.MDB.
Отношение один-к-одному
Если между двумя таблицами существует отношение один-к-одному, то это означает, что каждая запись в одной таблице соответствует только одной записи в другой таблице.
Примером такого отношения может служить отношение между таблицами. Таблица AUTHORS (Авторы)рассмотрена выше (рис. 1.5 и 1.6) и содержит краткую информацию о авторах (ФИО и год рождения). ТаблицаPERSON (Личность) содержит персональную информацию о авторах (домашний адрес, телефон, образование и др.) Структура таблицы PERSON показана на рис.1.10.Следует отметить, что в базе данных BIBLIO.MDB никакой таблицы PERSON нет и мы упоминаем о ней только как о иллюстрации отношения между таблицами -один-к-одному.
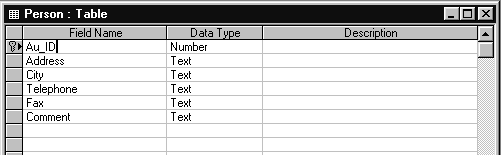 Рис.1.10.
Структура таблицы PERSON
Рис.1.10.
Структура таблицы PERSON
Между таблицами AUTHORS и PERSON существует отношение один-к-одному, так как одна запись,идентифицирующая автора, однозначно соответствует только одной записи в таблице PERSON,содержащей персональные данные об авторе.
Связь между таблицами определяется с помощью совпадающих полей: Au_ID в таблице AUTHORS и в таблицеPERSON.
Отношение один-ко-многим
Хорошим примером отношения между таблицами один-ко-многим является отношение между авторами и названиями книг (таблицы AUTHORS и TITLES), так как каждый автор может иметь отношение к созданию нескольких книг. Связь между таблицами AUTHORS и TITLESосуществляется с помощью совпадающих полей Au_ID в обеих таблицах.
Аналогичное отношение существует между издательствами и названиями изданных книг,организацией и работающими в ней сотрудниками,автомобилем и деталями, из которых он состоит и т.п. Понятно, что подобный тип отношения между таблицами наиболее часто встречается при проектировании структуры баз данных.
Отношение много-к-одному
Отношение много-к-одному полностью аналогично рассмотренному выше отношению один-ко-многим.
Отношение много-ко-многим
При отношении между двумя таблицами много-ко-многим каждая запись в одной таблице связана с несколькими записями в другой таблице и наоборот. Иллюстрацией такого отношения может служить отношение между таблицами PUBLISHERS и AUTHORS. С одной стороны, каждое издательство может публиковать книги разных авторов и с другой стороны - каждый автор может публиковаться в разных издательствах.
Для удобства работы с таблицами, имеющими отношение много-ко-многим, обычно в базу данных добавляют еще одну таблицу, которая находится в отношении один-ко-многим и много-к-одному к соответствующим таблицам. В случае базы данныхBIBLIO.MDB такой таблицей является TITLE AUTHOR.
24
Основной формой организации информационных массивов в ИС являются базы данных. Базу данных можно определить как совокупность взаимосвязанных хранящихся вместе данных при наличии такой минимальной избыточности, которая допускает их использование оптимальным образом для одного или нескольких приложений. В отличие от файловой системы организации и использования информации , БД существует независимо от конкретной программы и предназначена для совместного использования многими пользователями. Такая централизация и независимость данных в технологии БД потребовали создания соответствующих СУБД - сложных комплексов программ, которые обеспечивают выполнение операций корректного размещения данных, надежного их хранения, поиска, модификации и удаления.
Основные требования по безопасности данных, предъявляемые к БД и СУБД, во многом совпадают с требованиями, предъявляемыми к безопасности данных в компьютерных системах – контроль доступа, криптозащита, проверка целостности, протоколирование и т.д.
Под управлением целостностью в БД понимается защита данных в БД от неверных (в отличие от несанкционированных) изменений и разрушений . Поддержание целостности БД состоит в том, чтобы обеспечить в каждый момент времени корректность (правильность) как самих значений всех элементов данных, так и взаимосвязей между элементами данных в БД . С поддержанием целостности связаны следующие основные требования.
Обеспечение достоверности. В каждый элемент данных информация заносится точно в соответствии с описанием этого элемента .Должны быть предусмотрены механизмы обеспечения устойчивости элементов данных и их логических взаимосвязей к ошибкам или неквалифицированным действиям пользователей.
Управление параллелизмом. Нарушение целостности БД может возникнуть при одновременном выполнении операций над данными, каждая из которых в отдельности не нарушает целостности БД . Поэтому должны быть предусмотрены механизмы управления данными, обеспечивающие поддержание целостности БД при одновременном выполнении нескольких операций.
Восстановление. Хранимые в БД данные должны быть устойчивы по отношению к неблагоприятным физическим воздействиям (аппаратные ошибки, сбои питания и т .п .) и ошибкам в программном обеспечении . Поэтому должны быть предусмотрены механизмы восстановления за предельно короткое время того состояния БД, которое было перед появлением неисправности.
Вопросы управления доступом и поддержания целостности БД тесно соприкасаются между собой, и во многих случаях для их решения используются одни и те же механизмы. Различие между этими аспектами обеспечения безопасности данных в БД состоит в том, что управление доступом связано с предотвращением преднамеренного разрушения БД, а управление целостностью - с предотвращением непреднамеренного внесения ошибки.