

Процессоры (основные принципы и классы)
Архитектура фон Неймана
В 1945 г. в отчете по ЭВМ EDVAC Дж. фон Нейман сформулировал основные принципы построения ЭВМ. Вычислительная система, согласно фон Нейману, должна включать следующие компоненты: центральное арифметическое устройство; центральное устройство управления; главную память; устройства ввода-вывода.
По прошествии более полувека большинство компьютеров так и имеют «фон-неймановскую архитектуру».
Процессором является определенная функционально полная совокупность устройств, которая регулирует, управляет и контролирует соответствующий рабочий процесс. В ПК таким рабочим процессом является процесс обработки данных, а сама совокупность устройств называется процессором.
В состав микропроцессора входят несколько типовых компонентов.
Устройство управления (УУ) формирует и подает во все блоки машины в нужные моменты времени определенные сигналы управления (управляющие импульсы), обусловленные спецификой выполняемой операции и результатами предыдущих операций; формирует адреса слов (ячеек) памяти, используемых выполняемой операцией и передает эти адреса в соответствующие блоки компьютера; опорную последовательность импульсов устройство управления получает от генератора тактовых импульсов.
Арифметико-логическое устройство (АЛУ) предназначено для выполнения арифметических (обычно это короткие операции с фиксированной точкой, ФТ) и логических операций над числовой и символьной информацией.
Микропроцессорная память (МПП, или кэш-память 1-го уровня L1 cache) предназначена для кратковременного хранения, записи и выдачи информации, непосредственно используемой в ближайшие такты работы машины.
Интерфейсная система микропроцессора предназначена для сопряжения и связи с другими устройствами ПК.
Генератор тактовых импульсов (internal clock) генерирует последовательность электрических импульсов, частота которых определяет тактовую частоту микропроцессора электронные часы реального времени, обеспечивающие при необходимости автоматический съем текущего момента времени.
Перечислим далее основные понятия, связанные с работой процессора.
Команда, инструкция (instruction) описание операции, которую нужно выполнить. Каждая команда начинается с кода операции (КОП), содержит необходимые адреса, характеризуется форматом, который определяет структуру команды.
Команды подразделяются на арифметические, логические, ввода/вывода, передачи данных. Каждая команда выполняется в компьютере за один либо несколько тактов.
Цикл процессора период времени, за который осуществляется выполнение команды исходной программы в машинном виде; состоит из нескольких тактов.
Такт работы процессора промежуток времени между соседними импульсами (tick of the internal clock) генератора тактовых импульсов, частота которых есть тактовая частота процессора. Такт процессора (такт синхронизации) квант времени, в течение которого осуществляется элементарная операция выборка, сравнение, пересылка данных. Выполнение короткой команды арифметика с ФТ, логические операции, обычно занимает пять тактов:
выборка команды;
расшифровка кода операции (декодирование);
генерация адреса и выборка данных из памяти;
выполнение операции;
запись результата в память.
Процедура, соответствующая такту, реализуется определенной логической цепью (схемой) процессора, обычно именуемой микропрограммой.
Регистры. Регистры устройства, предназначенные для временного хранения данных ограниченного размера. Важной характеристикой регистра является высокая скорость приема и выдачи данных. Регистр, обладающий способностью перемещать содержимое своих разрядов, называют сдвиговым. Некоторые регистры служат счетчиками. Счетчик является устройством, которое на своих выходах выдает (в двоичной форме) сумму числа импульсов, подаваемых на его единственный вход. Максимальное число импульсов, которое счетчик может подсчитать, называется его емкостью.
Регистры общего назначения (РОН, General Purpose Registers) общее название для регистров, которые временно содержат данные, передаваемые или принимаемые из памяти.
Регистр команды (РК, Instruction Register IR) служит для размещения текущей команды, которая находится в нем в течение текущего цикла процессора.
Регистр- (РАК) счетчик (СчАК) адреса команды (program counter, PC) регистр, содержащий адрес текущей команды.
Сумматор регистр, осуществляющий операции сложения (логического и арифметического двоичного) чисел или битовых строк, представленных в прямом или обратном коде. (Иногда РЧ и РР включают в состав сумматора).
Существуют и другие регистры, например, регистр состояния Status Register (SR). Типичным содержанием SR является информация о результатах завершения команды (ноль, переполнение, деление на ноль, перенос и пр.). УУ использует информацию из SR для исполнения условных переходов (например, «в случае переполнения перейти по адресу 4170»).
Цикл команды. Цикл выполнения короткой команды может выглядеть следующим образом.
В соответствии с содержимым СчАК (адрес очередной команды) УУ извлекает из ОП очередную команду и помещает ее в РК. Некоторые команды УУ обрабатывает самостоятельно, без привлечения АЛУ (например, по команде «перейти по адресу 2478» величина 2478 сразу заносится в СчАК, и процессор переходит к выполнению следующей команды).
Типичная команда содержит:
код операции (КОП), характеризующий тип выполняемого действия;
номера индексного (ИР) и базисного (БР) регистров;
адреса операндов Al, A2 и т. д.
Осуществляется расшифровка (декодирование) команды.
Адреса Al, A2 и пр. помещаются в регистры адреса.
Если в команде указаны ИР или БР, то их содержимое используется для модификации РА фактически выбираются числа или команды, смещенные в ту или иную сторону по отношению к адресу, указанному в команде.
По значениям РА осуществляется чтение чисел (строк) и помещение их в РЧ.
Выполнение операции и помещение результата в PP.
Запись результата по одному из адресов (если необходимо).
Увеличение содержимого СчАК на единицу (переход к следующей команде).
Очевидно, что за счет увеличения числа регистров возможно распараллеливание, перекрытие операций. Например, при считывании команды СчАК можно автоматически увеличить на 1, подготовив выборку следующей команды. После расшифровки текущей команды РК освобождается и в него может быть прочитана следующая команда. При выполнении операции возможна расшифровка следующей команды и т. д. Все это является предпосылкой построения так называемых конвейерных структур (pipeline). Однако все это хорошо только при последовательном (естественном) порядке выполнения команд. Появление переходов (особенно по не определенному заранее условию) нарушает эту картину. Поэтому современные процессоры пытаются предсказывать переходы и программе (branch prediction).
Системы команд и соответствующие классы процессоров
Основные команды ЭВМ классифицируются вкратце следующим образом: по функциям (выполняемым операциям), направлению приема-передачи информации, адресности.
Классы команд.
Команды обработки данных, в том числе (О1 первый операнд, О2 второй):
Короткие операции (один такт).
Логические:
логическое сложение (для каждого бита О1 и О2 осуществляется операция ИЛИ;
логическое умножение (для каждого бита О1 и О2 осуществляется операция И;
инверсия (в О1 все единицы заменяются на нули, и наоборот);
сравнение логическое (если О1 = О2, то некий регистр устанавливается в 1, иначе в 0).
Арифметические:
сложение или вычитание операндов;
сравнение арифметическое (если О1 > О2, или О1 = О2, или О1 < О2, то некий регистр устанавливается в 1, иначе в 0).
Длинные операции (несколько тактов):
сложение/вычитание с фиксированной точкой;
умножение/деление с фиксированной точкой.
Операции управления:
безусловный переход (ветвление, branch);
условный переход (по условию, результатам вычислений (conditional branch)).
Операции обращения к внешним устройствам (требование на запись или считывание информации).
Естественно, могут существовать и другие операции десятичная арифметика, обработка символьной информации, работа с числами половинной (полуслово, например 16 бит) или двойной (двойное слово, например 64 бит) длины.
Кроме того, команды различаются по типу выборки и пересылок данных: регистррегистр; памятьрегистр (регистрпамять); памятьпамять.
Далее, известны одно-, двух- и трехадресные машины (системы команд). Очевидна связь таких параметров ЦУ, как длина адресного пространства, адресность, разрядность. Увеличение разрядности позволяет увеличить адресность команды и длину адреса (т. е. объем памяти, доступной данной команде). Увеличение адресности, в свою очередь, приводит к повышению быстродействия обработки (за счет снижения числа требуемых команд).
В трехадресной машине, например, сложение двух чисел требует одной команды (извлечь число по А1, число по А2, сложить и записать результат по A3). В двухадресной необходимы две команды (первая извлечь число по А1 и поместить в РЧ (или сумматор), вторая извлечь число по A1, сложить с содержимым РЧ и результат записать по А2). Легко видеть, что одноадресная машина потребует три команды. Поэтому неудивительно, что основная тенденция в развитии ЦУ ЭВМ состоит в увеличении разрядности.
Наибольшее применение нашли двухадресные системы команд.
Классы процессоров. В зависимости от набора и порядка выполнения команд процессоры подразделяются на два основных класса, отражающих также последовательность развития ЭВМ. Ранее других появились процессоры CISC. Затем с целью повышения быстродействия процессоров были разработаны процессоры RISC, которые характеризуются сокращенным набором быстровыполняемых команд. Ряд редко встречающихся команд процессора CISC выполняется последовательностями команд процессора RISC.
CISC (complex instruction set computer) есть традиционная архитектура, в которой ЦП использует микропрограммы для выполнения исчерпывающего набора команд. В течение долгих лет производители компьютеров разрабатывали и воплощали в изделиях все более сложные и полные системы команд. Однако анализ работы процессоров показал, что примерно 80% времени выполняется лишь 20% большого набора команд. Поэтому была поставлена задача оптимизации выполнения небольшого по числу, но часто используемых команд.
RISC (Red used Instuction Set Computer) процессор, функционирующий с сокращенным набором команд. Так, в процессоре CISC для выполнения одной команды необходимо в большинстве случаев 10 и более тактов. Что же касается процессоров RISC, то они близки к тому, чтобы выполнять по одной команде в каждом такте. Первый процессор RISC был создан корпорацией IBM в 1979 г. и имел шифр IBM 801. В настоящее время процессоры RISC получили широкое распространение. Современные процессоры RISC имеют следующие характеристики:
упрощенный набор команд, имеющих одинаковую длину;
большинство команд выполняются за один такт процессора;
отсутствуют макрокоманды, усложняющие структуру процессора и уменьшающие скорость его работы;
взаимодействие с оперативной памятью ограничивается операциями пересылки данных;
уменьшено число способов адресации памяти (не используется косвенная адресация);
создан конвейер команд, позволяющий обрабатывать несколько из них одновременно;
используется высокоскоростная память.
Новый подход к архитектуре процессора значительно сократил площадь, требуемую для него на чипе. Это позволило резко увеличить число регистров. В современном процессоре RISC уже используется более 100 регистров. В результате процессор на 2030% реже обращается к оперативной памяти, что также повысило скорость обработки данных.
Начиная с процессора Pentium, корпорация Intel начала внедрять элементы RISC-технологий в свои изделия.
Кроме того, известны процессоры MISC (работающие с минимальным набором длинных команд) и VLIW (с системой команд сверхбольшой разрядности).
Процессор VLIW процессор, работающий с системой команд сверхбольшой разрядности.
Идея технологии VLIW (Very large instruction word) заключается в том, что создается специальный компилятор планирования, который перед выполнением прикладной программы проводит ее анализ и по множеству ветвей последовательности операций определяет группу команд, которые могут выполняться параллельно. Каждая такая группа образует одну сверхдлинную команду. Это позволяет решать две важные задачи: во-первых, в течение одного такта выполнять группу коротких («обычных») команд, во-вторых, упростить структуру процессора. Этим технология VL1W отличается от суперскалярности. В последнем случае отбор групп одновременно выполняемых команд происходит непосредственно в ходе выполнения прикладной программы (а не заранее), что усложняет структуру процессора и замедляет его скорость.
Процессор MISC MISC processor, работающий с минимальным набором длинных команд.
Увеличение разрядности процессоров привело к идее укладки нескольких команд в одно слово (связку, bound) размером 128 бит. Оперируя с одним словом, процессор получил возможность обрабатывать сразу несколько команд. Это позволило использовать возросшую производительность компьютера и его возможность обрабатывать одновременно несколько потоков данных.
Технологии повышения производительности процессоров
Конвейерная обработка команд (pipelining). Суперскаляризация. Рассмотрим процесс выполнения процессором команды для коротких (с ФТ или логические) операций. Как об этом говорилось ранее, обработка команды, или цикл процессора, может быть разделена на несколько основных этапов, которые можно назвать микрокомандами, которых известно пять основных типов.
Каждая операция требует для своего выполнения времени, равного такту генератора процессора. Отметим, что к длинным операциям (ПТ) это не имеет отношения там другая арифметика. Очевидно, что при тактовой частоте в 100 МГц быстродействие составит 20 млн. операций в секунду.
Все этапы команды задействуются только 1 раз и всегда в одном и том же порядке: одна за другой. Это, в частности, означает, что если первая микрокоманда выполнила свою работу и передала результаты второй, то для выполнения текущей команды она больше не понадобится и, следовательно, может приступить к выполнению следующей команды.
Конвейеризация осуществляет многопоточную параллельную обработку команд, так что в каждый момент одна из команд считывается, другая декодируется и т. д., и всего в обработке одновременно находится пять команд. Таким образом, на выходе конвейера на каждом такте процессора появляется результат обработки одной команды (одна команда в один такт). Первая инструкция может считаться выполненной, когда завершат работу все пять микрокоманд.
Такая технология обработки команд носит название конвейерной (pipeline) обработки. Каждая часть устройства называется ступенью конвейера, а общее число ступеней длиной линии конвейера.
С ростом числа линий конвейера и увеличением числа ступеней на линии (табл. 1.2) увеличивается пропускная способность процессора при неизменной тактовой частоте. Процессоры с несколькими линиями конвейера получили название суперскалярных. Pentium первый суперскалярный процессор Intel. Здесь две линии, что позволяет ему при одинаковых частотах быть вдвое производительней i80486, выполняя сразу две команды за такт.
Таблица 1.2. Характеристики конвейеров процессоров Intel
Характеристика |
Процессор |
||||||
|
i80496 |
Pentium |
Pentium Pro |
Pentium MMX |
Pentium II |
Pentium III |
Pentium IV |
Число линий |
1 |
2 |
3 |
2 |
3 |
3 |
3 |
Длина линии |
5 |
5 |
14 |
6 |
14 |
20 |
31 HyperPipeline) |
Операции над вещественными числами
(с плавающей запятой)
Сопроцессоры. Для расширения вычислительных возможностей центрального процессора выполнения арифметических операций, вычисления основных математических функции (тригонометрических, показательных, логарифмических) и т. д. в состав ЭВМ добавляется математический сопроцессор. Применение сопроцессора повышает производительность вычислений в сотни раз. В разных поколениях процессоров он назывался по-разному FPU (Floating Point Unit блок чисел/операций с плавающей точкой БПЗ) или NPX (Numeric Processor extension числовое расширение процессора).
Блоки операций с плавающей запятой. Начиная с 80486 восемь регистров для ПЗ (именуемых ST (0) ST (7)) встраивают в центральный процессор (рис. 1.18). Каждый регистр имеет ширину 80 бит и хранит числа в формате стандарта ПЗ расширенной точности (IEEE floating-point standard).
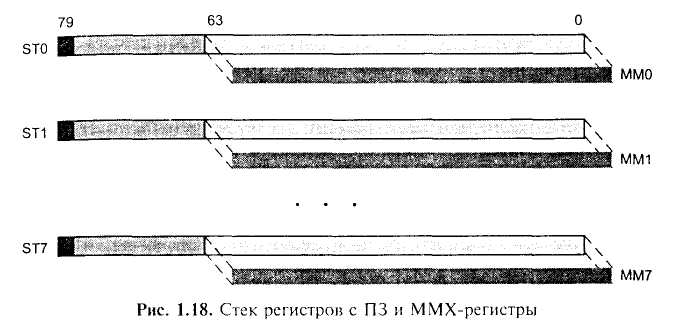
Эти регистры доступны в стековом порядке. Имена (номера) регистров устанавливаются относительно вершины стека (ST (0) вершина стека, ST (1) следующий регистр ниже вершины стека, ST(2) второй после вершины стека и т. д.). Вводимые данные таким образом всегда сдвигаются «вниз» от вершины стека, а текущая операция совершается с содержимым вершины стека.
Увеличение разрядности систем
В «романтические» 1980-е годы соответствие между типом ЭВМ и ее разрядностью имело простейший вид:
микроЭВМ 8 разрядов;
мини-ЭВМ 16 разрядов;
большие ЭВМ 32 разряда;
сверхбольшие (супер) ЭВМ 64 разряда.
В процессе развития микропроцессоров Intel рубежи в 16 и 32 разряда (IА-32) были преодолены довольно быстро, а примерно в 2004 г. произошел переход и на 64-разрядные архитектуры в процессорах Intel и AMD.
Преимущества 64-битовой архитектуры микропроцессоров главным образом относятся к памяти. Если взять два идентичных микропроцессора, то если один из них будет 32-битовым, а другой 64-битовым, то последний сможет адресовать намного больший объем памяти, чем 32-битовый (264 против 232). Известны следующие архитектуры на 64 разряда (64-bit architecture).
IA-64. Спецификация IA-64 означает «Архитектура Intel, 64 бита», но связь с IA-32 только по названию. Архитектура IA-64 несовместима непосредственно с набором команд IА-32. Здесь появляется полностью отличный набор команд, а также используются принципы VLIW. IA-64 архитектура, используемая линией процессоров Itanium.
Усовершенствования:
в 16 раз увеличено количество РОН и ПЗ (теперь по 128);
механизм переименования/ротации регистров, чтобы сохранять значения в регистрах при вызове функций.
AMD64. Набор команд AMD64, первоначально названный х86-64, в значительной степени построен на основе IА-32 и таким образом обеспечивает наследственность семейства х86. При расширении набора команд AMD воспользовался возможностью, чтобы очистить часть его от ряда «устаревших» команд наследия «16-разрядных времен».
Усовершенствования:
в 2 раза увеличено количество РОН и SSE (теперь по 16);
РОН теперь действительно регистры общего назначения и ни чем больше не ограничены.
Архитектура использована в ЦП Athlon 64, Athlon 64 Х2, Athlon 64 FX, Opteron, Turion 64, Turion 64 X2, Sempron («Palermo», «Manila»).
EM64T (Extended Memory 64-bit Technology, или Intel 64) набор команд (ранее известный как Yamhill), объявленный Intel в феврале 2004 г., в подражание AMD64. ЕМ64Т в целом совместим с кодами, написанными для AMD64, хотя и имеет ряд недостатков сравнительно с AMD64.
Intel начал использовать набор ЕМ64Т, начиная с ЦП Xeon (ядро Nocona) в конце 2004 г., а затем вышел с ним на рынок настольных ПК в начале 2005 г. (Pentium IV, версия Е0).
EMT/Intel 64 используется в ЦП архитектуры Intel NetBurst Xeon («Nocona»), Celeron D («Prescott» и далее), Pentium 4 («Prescott» и далее), Pentium D, Pentium Extreme Edition и архитектуры Intel Core Xeon («Woodcrest»), Intel Core 2.
Поскольку AMD64 и ЕМТ64 почти не различаются, для ссылки на них используются нейтральные названия х86-64, х86_64 (Linux и Apple's Mac OS X), х64 (Microsoft и Sun Microsystems).
SIMD процессы (команды)
Г. Флинном [16] в 1966 г. была предложена классификация ЭВМ и вычислительных систем (в основном суперкомпьютеров), основанная на совместном рассмотрении потоков команд и данных (табл. 1.3). В процессорах таких известных производителей как Intel и AMD все более полно используются некоторые из этих архитектурных наработок.
Таблица 1.3. Классификация Флинна
Поток данных |
Поток команд |
|
Одиночный |
Множественный |
|
Одиночный |
SISD - Single Instruction stream/ Single Data stream (Одиночный поток Команд и Одиночный поток Данных - ОКОД) |
MISD - Multiple Instruction stream/ Single Data stream (Множественный поток Команд и Одиночный поток Данных - МКОД) |
Множественный |
SIMD - Single Instruction stream/ Multiple Data stream (Одиночный поток Команд и Множественный поток Данных - ОКМД) |
MIMD - Multiple Instruction stream/ Multiple Data stream (Множественный поток Команд и Множественный поток Данных - МКМД) |
Например, в общем случае архитектура SIMD (ОКМД) предполагает создание структур векторной или матричной обработки. Под эту схему хорошо подходят задачи обработки матриц или векторов (массивов), задачи решения систем линейных и нелинейных, алгебраических и дифференциальных уравнений, задачи теории поля и др.
В микропроцессорах массового выпуска при обработке мультимедийных данных также целесообразно применять подобные решения.
ММХ (MultiMedia eXtension) архитектура системы команд (57 команд для ФЗ), непосредственно предназначенных для задач мультимедиа, связи и графических приложений, которые часто используют сложные алгоритмы, исполняющие одинаковые операции на большом количестве типов данных (байты, слова и двойные слова). Анализ участков таких программ с большим объемом вычислений показал, что такие приложения имеют следующие общие свойства, определившие выбор системы команд и структуры данных:
небольшая разрядность целочисленных данных (например, 8-разрядные пиксели для графики или 16-разрядное представление речевых сигналов);
небольшая длина циклов, но большое число их повторений;
большой объем вычислений и значительный удельный вес операций умножения и накопления;
существенный параллелизм операций в программах.
Это и определило новую структуру данных и расширение системы команд. При этом было достигнуто общее повышение производительности на 1020%, а в программах обработки мультимедиа до 60%.
В процессоре Pentium MMX (1996 г.) появляются 8 новых 64-разрядных «регистров» с именами MM0MM7 (или же MMn), в действительности эти новые «регистры» были только псевдонимами для регистров стека ПЗ х87 (см. рис. 1.19). В связи с тем, что каждый из регистров стека содержит 80 бит, старшие 16 бит регистров стека оказываются неиспользованными в ММХ (рис. 1.18). Поэтому в режиме ММХ они заполняются всеми единицами, что позволяет отличать данные формата плавающей запятой от ММХ-данных.
Каждый из регистров MMn предназначен для целых чисел на 64 бита. Однако главным понятием набора команд ММХ является концепция упакованных типов данных (несколько коротких чисел, размещенных в одном регистре или машинном слове).
ММХ-команды используются в ЦП, начиная с Pentium ММХ (AMD Кб).
Архитектура 3DNow! впервые реализована в процессорах AMD К6-2 (май 1998 г.). Технология 3DNow! включает 21 дополнительную команду, новые типы данных и использует регистры MMn (MM0MM7) для поддержки высокопроизводительной обработки ЗD-графики и звука.
В то время как архитектура ММХ предполагает целочисленную арифметику, векторные команды 3DNow! параллельно обрабатывают две пары 32-разрядных вещественных операндов одинарной точности.
Процессор может выполнять две 3DNow! команды за такт и, следовательно, 4 операции над числами с ПЗ одновременно. Технология 3DNow! предполагает наличие в ЦП для выполнения векторных ММХ и 3DNow! операций нескольких устройств (пара умножителей, сумматоров и т. д.). Все команды 3DNow! имеют длительность исполнения 2 такта и полностью конвейеризированы.
SSE (или SIMD-FP) система команд Streaming SIMD Extensions SIMD-расширение, предложенное Intel в 1999 г. в Pentium III (ядро Katmai), отсюда вариант названия KNI (Katmai New Instructions). Это 70 новых команд, в том числе:
50 команд предназначаются для повышения эффективности операций с ПЗ, с этой целью в ЦП встроены 128-битовые регистры восемь регистров, названные XMM0XMM7 (в AMD64 число SSE/XMM регистров было увеличено от 8 до 16.). В результате операции с ПЗ могут совершаться за один цикл процессора;
12 команд (New Media) дополняют ранее введенные 57 команд ММХ для ФЗ;
оставшиеся 8 команд (New Cacheability) повышают производительность кэш-памяти L1 при работе с мультимедийными данными.
SSE набор команд, которые обрабатывают только значения с ПЗ, подобно 3DNow!. Поскольку здесь используются более длинные регистры, чем в 3DNow!, SSE может упаковать два числа ПЗ в каждый регистр. Первоначальная версия SSE была ограничена только числами одинарной точности, подобно 3DNow!.
SSE2 введенный с Pentium IV набор команд является существенным развитием SSE, оперирует с теми же самыми регистрами и обратно совместим с SSE процессора Pentium III. В расширении SSE2 операции со 128-битовыми регистрами могут выполняться не только как с четверками вещественных чисел двойной точности, но и как с парами вещественных чисел двойной точности, с шестнадцатью однобайтовыми целыми и пр. SSE2 представляет собой симбиоз ММХ и SSE и позволяет работать с любыми типами данных, вмещающимися в 128-битовые регистры.
SSE3 набор команд, также известный как Prescott New Instructions (PNI), является третьей версией команд SSE для IA-32. Intel использует SSE3 с начала 2004 г. в ЦП Pentium IV Prescott. В апреле 2005 г. AMD также включает SSE3 в ЦП Athlon 64 (версия Е ядра Venice и San Diego). SSE3 содержит 13 дополнительных по отношению к SSE2 команд. Самое существенное новшество «горизонтальная арифметика» (операции над несколькими числами, размещенными в одном длинном регистре).
Динамическое исполнение (dynamic execution technology)
Динамическое исполнение технология обработки данных процессором, обеспечивающая более эффективную работу процессора за счет манипулирования данными, а не просто линейного исполнения списка инструкций.
Предсказание ветвлений. С большой точностью (более 90%) процессор предсказывает, в какой области памяти можно найти следующие инструкции. Это оказывается возможным, поскольку в процессе исполнения инструкции процессор просматривает программу на несколько шагов вперед.
Внеочередное выполнение (выполнение вне естественного порядка out-of-order execution). Процессор анализирует поток команд и составляет график исполнения инструкций в оптимальной последовательности независимо от порядка их следования в тексте программы, просматривая декодированные инструкции и определяя, готовы ли они к непосредственному исполнению или зависят от результата других инструкций. Далее процессор определяет оптимальную последовательность выполнения и исполняет инструкции наиболее эффективным образом.
Переименование (ротация) регистров (register rename). Чтобы избежать пересылок данных между регистрами в соответствующей команде изменяется адрес регистра, содержащего данные, участвующие в следующей операции. Поэтому вместо пересылки данных в регистр-источник осуществляется трактовка регистра с данными как источника.
Выполнение по предположению (спекулятивное speculative) процессор выполняет инструкции (до пяти инструкций одновременно) по мере их поступления в оптимизированной последовательности (спекулятивно). Поскольку выполнение инструкций происходит на основе предсказания ветвлений, результаты сохраняются как предположительные («спекулятивные»). На конечном этапе порядок инструкций восстанавливается.
Существуют следующие варианты спекулятивного выполнения:
предикация (predication) одновременное исполнение нескольких ветвей программы вместо предсказания переходов (выполнения наиболее вероятного);
опережающее чтение данных (speculative loading), т. е. загрузка данных в регистры с опережением, до того, как определилось реальное ветвление программы (переход управления).
Эти возможности осуществляются комбинированно при компиляции и выполнении программы.
Предикация. Обычный компилятор транслирует оператор ветвления (например, if-then-else) в блоки машинного кода, расположенные последовательно в потоке. Обычный процессор в зависимости от исхода условия исполняет один из этих базовых блоков, пропуская все другие. Более развитые процессоры пытаются прогнозировать исход операции и предварительно выполняют предсказанный блок. При этом в случае ошибки много тактов тратится впустую. Сами блоки зачастую весьма малы две или три команды, а ветвления встречаются в коде в среднем каждые шесть команд. Такая структура кода делает крайне сложным его параллельное выполнение.
При использовании предикации компилятор, обнаружив оператор ветвления в исходной программе, анализирует все возможные ветви (блоки) и помечает их метками или предикатами (predicate). После этого он определяет, какие из них могут быть выполнены параллельно (из соседних, независимых ветвей).
В процессе выполнения программы ЦП выбирает команды, которые взаимно независимы и распределяет их на параллельную обработку. Если ЦП обнаруживает оператор ветвления, он не пытается предсказать переход, а начинает выполнять все возможные ветви программы.
Таким образом, могут быть обработаны все ветви программы, но без записи полученного результата. В определенный момент процессор наконец «узнает» о реальном исходе условного оператора, записывает в память результат «правильной ветви» и отменяет остальные результаты.
В то же время, если компилятор не «отметил» ветвление, процессор действует как обычно пытается предсказать путь ветвления и т. д. Испытания показали, что описанная технология позволяет устранить более половины ветвлений в типичной программе, и, следовательно, уменьшить более чем в 2 раза число возможных ошибок в предсказаниях.
Опережающее чтение (предварительная загрузка данных, чтение по предположению) разделяет загрузку данных в регистры и их реальное использование, избегая ситуации, когда процессору приходится ожидать прихода данных, чтобы начать их обработку.
Прежде всего, компилятор анализирует программу, определяя команды, которые требуют приема данных из оперативной памяти. Там, где это возможно, он вставляет команды опережающего чтения и парную команду контроля опережающего чтения (speculative check). В то же время компилятор переставляет команды таким образом, чтобы ЦП мог их обрабатывать параллельно.
В процессе работы ЦП встречает команду опережающего чтения и пытается выбрать данные из памяти. Может оказаться, что они еще не готовы (результат работы блока команд, который еще не выполнился). Обычный процессор в этой ситуации выдает сообщение об ошибке, однако система откладывает «сигнал тревоги» до момента прихода процесса в точку «команда проверки опережающего чтения». Если к этому моменту все предшествующие подпроцессы завершены и данные считаны, то обработка продолжается, в противном случае вырабатывается сигнал прерывания.
Многократное декодирование команд
В то время как традиционный процессор линейно переводит команды в тактовые микрокоманды и последовательно их выполняет, ЦП с многократным декодированием сначала преобразует коды исходных команд программы в некоторые вторичные псевдокоды (предварительное декодирование, или предекодирование), которые затем более эффективно исполняет ядро процессора. Эти преобразования могут содержать несколько этапов. В качестве примеров рассмотрим 23-ступенчатые декодеры (рис. 1.19).
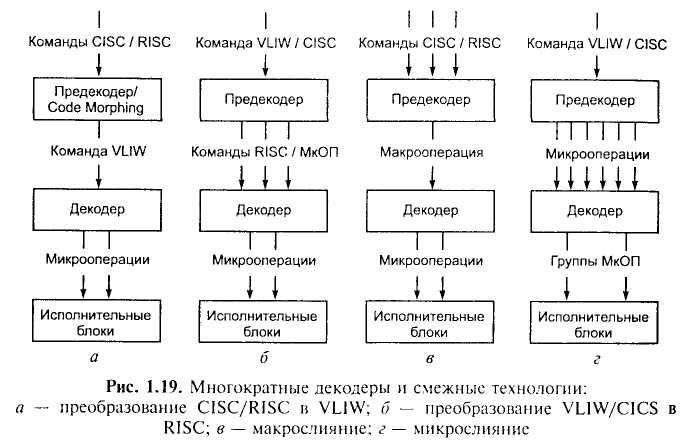
Декодирование команд CISC/RISC в VLIW (рис. 1.19, а). Эти технологии использованы в мобильных процессорах Crusoe (фирма Transmeta) и некоторых ЦП Intel архитектуры 1А-64 и EPIC (Explicitly Parallel Instruction Computing вычисления с явной параллельностью инструкций).
В частности, в Crusoe на входе процессора программы, подготовленные в системе команд Intel x86, однако внутренняя система команд VLIW не имеет ничего общего с командами х86 и разработана для быстрого выполнения при малой мощности, используя обычную CMOS-технологию. Окружающий уровень программного называют программным обеспечением модификации кодов (Code Morphing software CMS, или CM), здесь осуществляется динамический перевод команд х86 в команды VLIW.
Аналогичные приемы используются в процессорах Intel Itanium здесь при компиляции готовятся пакеты (связки, bundles) команд (по 3 команды в 128-битовом пакете). Тем самым, компилятор выполняет в данном случае функции СМ.
Декодирование команд CISC VLIW в RISC. Указанные выше достоинства RISC-архитектуры привели к тому, что во многих современных CISC-процессорах используется RISC-ядро, выполняющее обработку данных. При этом поступающие сложные и разноформатные команды предварительно преобразуются в последовательность простых RISC-операций, быстро выполняемых этим процессорным ядром (рис. 1.19, б). Таким образом, работают, например, современные модели процессоров Pentium и К7, которые по внешним показателям относятся к CISC-процессорам. Использование RISC-архитектуры является характерной чертой многих современных процессоров.
Макрослияние (macrofusion). В процессорах предыдущих поколений каждая выбранная команда отдельно декодируется и выполняется. Макрослияние позволяет объединять типичные пары последовательных команд (например, сравнение, сопровождающееся условным переходом) в единственную внутреннюю команду-микрооперацию (МкОП, micro-op) в процессе декодирования (рис. 1.19, в). В дальнейшем две команды выполняются как одна МкОП, сокращая полный объем работы процессора.
Микрослияние (micro-op fusion). В современных доминирующих процессорах команды х86 (macro-ops) обычно расчленяются на МкОП прежде, чем передаются на конвейер процессора. Микрослияние группирует и соединяет МкОП, уменьшая их число (рис. 1.19, г). Исследования показали, что слияние МкОП вкупе с выполнением команд в измененном порядке может уменьшить число МкОП более чем на 10%. Данная технология использована в системах Intel Core, а ранее апробировалась в ПЦ мобильных систем Pentium M.
В процессорах AMD K8 конвейер строится на том, что работа с потоком МкОП происходит тройками инструкций (AMD называет их линиями line). Конвейер К8 обрабатывает именно линии, а не х86-инструкции или отдельные микрооперации.
Технология Hyper-Threading (HT)
Здесь реализуется разделение времени на аппаратном уровне, разбивая физический процессор на два логических процессора, каждый из которых использует ресурсы чипа ядро, кэш-память, шины, исполнительное устройство (рис. 1.20). Благодаря НТ многопроцессная операционная система использует один процессор как два и выдает одновременно два потока команд. Смысл технологии заключается в том, что в большинстве случаев исполнительные устройства процессора далеки от полной загруженности. От передачи на выполнение вдвое большего потока команд повышается загрузка исполнительных устройств.

Многоядерные процессоры
В октябре 1989 г., рассматривая будущее через «призму Закона Мура», специалисты Intel в статье «Microprocessors Circa 2000» («Процессоры 2000-х гг.») предсказали, что многоядерные процессоры могут выйти на рынок в начале столетия. Пятнадцать лет спустя их предсказания оправдались развитие процессоров в этом направлении стало приоритетной задачей как для Intel, так и для конкурирующей AMD.
Многоядерная архитектура предполагает размещение двух или более основных вычислительных агрегатов в пределах единственного процессора. Этот многоядерный процессор имеет единственный интерфейс с системной платой, но операционные системы «видят» каждое из его ядер как дискретный логический процессор со всеми связанными ресурсами. Это отличает их от технологии Hyper-Threading (где отдельные процессы выполняются единственным ядром) и существующие ресурсы используются более эффективно.
Разделяя вычислительную нагрузку, выполняемую единственным ядром в традиционных процессорах между многими ядрами, многоядерный процессор может выполнить большую работу в пределах отдельного цикла ЭВМ. Чтобы реализовать это увеличение эффективности, соответствующее программное обеспечение должно поддерживать это распараллеливание. Эти функциональные возможности называют «параллелизмом уровня подпроцесса (нити)» или «threading». Приложения и операционные системы, которые поддерживают это, упоминаются как мультиподпроцессные или «multi-threaded».
Процессор, оборудованный параллелизмом уровня подпроцесса, может выполнить полностью отдельные «нити» кода. Это может означать или один подпроцесс, выполняемый из приложения, и второй подпроцесс, выполняемый из операционной системы, или параллельные подпроцессы, выполняемые из единственного приложения. Параллелизм уровня подпроцесса приносит особенный выигрыш для многих мультимедийных приложений, потому что многие из их операций способны к выполнению параллельно.
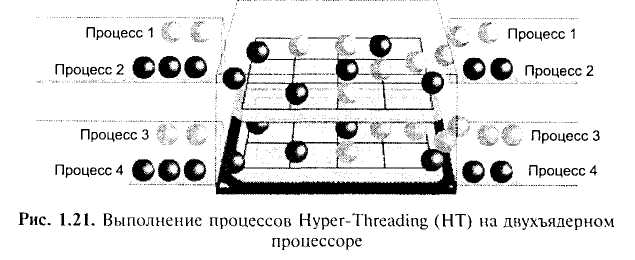
Если при этом используется режим Hyper-Threading, процессоры двойного ядра будут способны обработать четыре программных подпроцесса одновременно более эффективно имеющимися ресурсами, которые иначе, возможно, остались бы незанятыми (рис. 1.21).
Другие технологии
Технологии «невыполнимых битов» (No-eXecute bit). Бит «NX» (63-й бит адреса) позволяет операционной системе определить, какие страницы адреса могут содержать исполняемые коды, а какие нет. Попытка обратиться к NX-адресу как к исполняемой программе вызывает событие «нарушение защиты памяти», подобное попытке обратиться к памяти «только для чтения» или к области размещения ОС. Этим может быть запрещено выполнение программного кода, находящегося в некоторых страницах памяти, таким образом предотвращая вирусные или хакерские атаки. С теоретической точки зрения, здесь осуществляется виртуальное назначение «Гарвардской архитектуры» разделение памяти для команд и для данных. Обозначение «NX-bit» используется AMD, Intel использует выражение «XD-bit» (eXecute Disable bit).