

Обработка аудиоинформации
Профессиональные звуковые платы позволяют выполнять сложную обработку звука, обеспечивают стереозвучание, имеют собственное ПЗУ с хранящимися в нем сотнями тембров звучаний различных музыкальных инструментов. Звуковые файлы обычно имеют очень большие размеры. Так, трехминутный звуковой файл со стереозвучанием занимает примерно 30 Мбайт памяти. Поэтому платы Sound Blaster, помимо своих основных функций, обеспечивают автоматическое сжатие файлов.
Компоненты платы
Звуковая плата ПК содержит несколько аппаратных систем, связанных с производством и сбором аудиоданных, две основные аудиоподсистемы, предназначенные для цифрового «аудиозахвата», синтеза и воспроизведения музыки (рис. 6.6). Исторически подсистема синтеза и воспроизведения музыки генерирует звуковые волны одним из двух способов:
через внутренний ЧМ-синтезатор (FM-синтезатор);
проигрывая оцифрованный (sampled) звук.
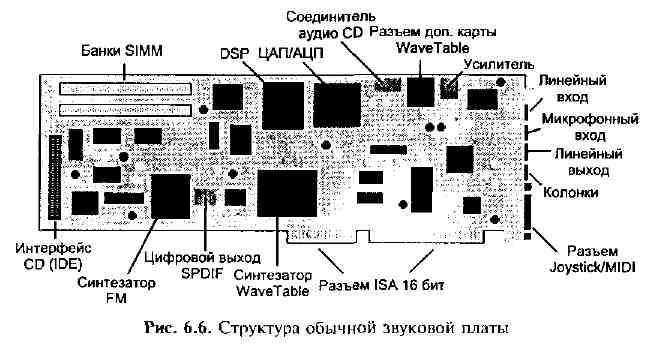
Секция цифровой звукозаписи звуковой платы включает пару 16-разрядных преобразователей цифроаналоговый (ЦАП) и аналого-цифровой (АЦП) и программируемый генератор частоты выборки, синхронизирующий преобразователи и управляемый ЦП. Компьютер передает оцифрованные звуковые данные к преобразователям или обратно. Частота преобразования обычно кратна (или часть от) 44,1 кГц.
Большинство плат использует один или более каналов прямого доступа к памяти, некоторые платы также обеспечивают прямой цифровой вывод, используя оптическое или коаксиальное подключение S/PD1F (цифровой звук в стандарте Sony/Philips Digital Interface).
Генератор звука, установленный на плате, использует процессор цифровых сигналов (Digital Signal Processor DSP), который проигрывает требуемые музыкальные ноты, объединяя их считывание из различных областей звуковой таблицы с различными скоростями, чтобы получить требуемую высоту тона. Максимальное количество доступных нот связано с мощностью DSP-процессора и называется «полифонией» платы.
DSP-процессоры используют сложные алгоритмы, чтобы создать эффекты типа реверберации, хорового звучания и запаздывания. Реверберация создает впечатление, что инструменты играют в больших концертных залах. Хор используется, чтобы создать впечатление, что несколько инструментов играют совместно, тогда как фактически есть только один. Добавление запаздывания к партии гитары, например, может дать эффект пространства и стереозвучания.
Частотная модуляция. Первой широко распространенной технологией, которая используется в звуковых платах, является частотная модуляция (ЧМ), которая была разработана в начале 1970-х гг. Дж. Чоунингом (Стэнфордский университет). ЧМ-синтезатор (FM-синтезатор) производит звук, генерируя чистую синусоидальную волну (несущая) и смешивая ее со вторым сигналом (модулятор). Когда эти две формы волны близки в частоте, создается волна сложной формы. Управляя несущей и модулятором, можно создавать различные тембры, или инструменты.
Каждый голос ЧМ-синтезатора требует минимум двух генераторов сигнала, обычно называемых «операторами». Разные конструкции ЧМ-синтезатора имеют различные степени управления параметрами оператора. Сложные системы ЧМ могут использовать четыре или шесть операторов на каждый голос, и операторы могут иметь корректируемые параметры, которые позволяют настроить скорости нарастания и угасания сигнала.
Yamaha была первой компанией, которая вложила капитал в исследования по теории Чоунинга, что привело к разработке легендарного синтезатора DX7. Специалисты Yamaha скоро поняли, что смешивание более широкого диапазона несущих и модуляторов позволяет создать более сложные тембры, приводя к реалистически звучащим инструментам.
Хотя системы ЧМ были осуществлены в аналоговом исполнении на ранних клавиатурных синтезаторах, в дальнейшем выполнение синтеза ЧМ было сделано в цифровой форме. Методы синтеза ЧМ очень полезны для того, чтобы создать выразительные новые звуки. Однако если цель синтезирующей системы состоит в том, чтобы воспроизвести звук некоторого существующего инструмента, это лучше делать в цифровой форме на основе выборок сигналов, как при синтезе с использованием звуковых таблиц (WaveTable synthesis).
Табличный синтез (WaveTable synthesis). Чтобы создать звук, звуковая таблица использует не несущие и модуляторы, а выборки звуков реальных инструментов. Выборка цифровое представление формы звука, произведенного инструментом. Платы, использующие ISA, обычно сохраняют выборки в ROM, хотя более новые PCf-изделия используют основную оперативную память ПК, которая загружается при запуске ОС (например, Windows) и может включать новые звуки.
В то время как все звуковые платы ЧМ звучат аналогично, платы звуковых таблиц значительно отличаются по качеству. Качество звучания инструментов включает факторы:
качество первоначальной записи;
частота, на которой выборки были записаны;
количество выборок, использованных для каждого инструмента;
методы сжатия, использованные для сохранения выборки.
Большинство инструментальных выборок записаны в стандарте 16 бит и 44,1 кГц, но многие изготовители сжимают данные так, чтобы больше выборок или инструментов можно было записать в ограниченный объем памяти. Однако сжатие часто приводит к потере динамического диапазона или качества.
Когда аудиокассета воспроизводится слишком быстро или слишком медленно, ее высота звучания меняется, и это справедливо также для цифровой звукозаписи. Проигрывание выборки на более высокой скорости, чем ее оригинал, приводит к более высокому воспроизводимому звуку, позволяя инструментам играть более нескольких октав. Однако если некоторые тембры воспроизводятся быстро, они звучат слишком слабо и тонко; аналогично, когда выборка проигрывается слишком медленно, она звучит мрачно и неестественно. Чтобы преодолеть эти эффекты, изготовители разбивают клавиатуру на несколько областей и применяют соответствующие выборки звуков инструментов в каждой из них.
Каждый инструмент звучит с различным тембром в зависимости от стиля игры. Например, при мягкой игре на фортепьяно не слышен звук молоточков, бьющих по струнам. При более интенсивной игре мало того что звук становится более очевидным, но можно заметить также и изменения тона.
Для каждого инструмента должно быть записано много выборок и их разновидностей, чтобы синтезатор точно воспроизвел этот диапазон звука, а это неизбежно требует большего количества памяти. Типичная звуковая плата может содержать до 700 инструментальных выборок в пределах ROM 4 Мбайт. Точное воспроизведение фортепьяно соло, однако, требует от 6 до 10 Мбайт данных, вот почему нет никакого сравнения между синтезируемым и реальным звуком.
Обновление звуковой таблицы не всегда означает необходимость покупать новую звуковую плату. Большинство 16-разрядных звуковых плат имеет разъем, который может соединиться с дополнительной платой звуковой таблицы (daughterboard) рис. 6.6. Качество звучания инструментов, которые такие платы обеспечивают, значительно различается, и это обычно зависит от того, какой объем памяти расположен на плате. Большинство плат содержит от 1 до 4 Мбайт выборок и предлагает целый ряд цифровых звуковых эффектов.
Коннекторы звуковой платы. В 1998 г. Creative Technology был выпущен очень успешный образец звуковой платы SoundBlaster Live!, ставший в дальнейшем стандартом де-факто.
Версия Platinum 5.1 карты Creative SoundBlaster Live!, которая появилась к концу 2000 г., имела следующие гнезда и соединители (рис. 6.7):
аналого-цифровой выход: либо сжатый сигнал в формате Dolby АС-3 SPDIF с 6 каналами для подключения внешних цифровых устройств или динамиков цифровых систем, либо аналоговая система громкоговорителей 5.1;
линейный вход соединяется с внешним устройством типа кассетного, цифрового магнитофона, плеера и пр.;
микрофонное гнездо соединяется с внешним микрофоном для ввода голоса;
линейный выход соединяется с динамиками или внешним усилителем для аудиовывода или наушниками;
соединитель джойстика/MlDl соединяется с джойстиком или устройством MIDI и может быть настроен так, чтобы соединяться с обоими одновременно;
CD/SPDIF соединитель соединяется с выводом SPDIF (цифровое аудио), расположенном на дисководе DVD или CD-ROM;
дополнительный аудиовход соединяется с внутренними аудиоисточниками типа тюнера, MPEG или других подобных плат;
соединитель аудиоСО соединяется с аналоговым аудиовыво-дом на CD-ROM или DVD-ROM, используя кабель аудиоСО;
соединитель автоответчика обеспечивает монофоническую связь со стандартным голосовым модемом и передает сигналы микрофона к модему.
Аудиорасширение (цифровой ввод-вывод) соединяется с цифровой платой ввода-вывода (располагается в свободной нише накопителя на 5,25", выходящей на переднюю панель компьютера), иногда называемой Live'Drive. Обеспечивает следующие соединения:
гнездо RCA SPDIF соединяется с устройствами цифровой звукозаписи типа цифровой ленты и мини-дисков;
гнездо наушников соединяется с парой высококачественных наушников, вывод динамика отключается;
регулировка уровня наушников управляет громкостью сигнала наушников;
второй вход (линейный/микрофонный) соединяется с высококачественным динамическим микрофоном или аудиоисточником (электрическая гитара, цифровое аудио или мини-диск);
переключатель второго входа (линейный/микрофон);
соединители MIDI соединяются с устройствами MIDI через кабель Mini DIN-Standard DIN;
инфракрасный порт (сенсор) позволяет организовать дистанционное управление ПК;
вспомогательные гнезда RCA соединяются с оборудованием бытовой электроники (видеомагнитофон, телевизор или проигрыватель компакт-дисков);
оптический вход-выход SPD1F соединяется с устройствами цифровой звукозаписи типа цифровой ленты или минидисков.

Современные аудиокарты поддерживают также ряд стандартных возможностей моделирования, генерации и обработки звукового сигнала:
DirectX предложенная Microsoft система команд управления позиционированием виртуального звукового источника (модификации DirectX 3, 5, 6);
A3D разработанный в 1997 г. NASA (National Aeronautics and Space Administration) и Aureal для использования в летных тренажерах стандарт генерации таких эффектов, как густой туман или подводные звуки. A3D2 позволяет моделировать конфигурацию помещения, в котором раздаются и распространяются звуки, вычисляя до 60 звуковых отражений (как в ангаре, так и в колодце);
ЕАХ (Environmental Audio Extensions), предложенная Creative Technology в 1998 г. модель добавления реверберации в A3D с учетом звуковых препятствий и поглощения звуков;
MIDI (Musical Instrument Digital Interface), разработанный в 1980-х гг. Команды по стандартному интерфейсу передаются в соответствии с MIDI-протоколом. MIDI-сообщение содержит не запись музыки как таковой, а ссылки на ноты. В частности, когда звуковая карта получает подобное сообщение, оно расшифровывается (какие ноты каких инструментов должны звучать) и отрабатывается в синтезаторе. В свою очередь, ПК может через интерфейс MIDI управлять различными «интерактивными» инструментами. В Windows MIDI-файлы могут воспроизводиться специальной программой-проигрывателем MIDI-Sequencer. В этой области синтеза звука также имеется свой стандарт. Основным является стандарт МТ-32, разработанный фирмой Roland и названный в соответствии с одноименным модулем генерации звуков. Этот стандарт также применяется в звуковых картах LAPC и определяет основные средства для управления расположением инструментов, голосов, а также для деления на инструментальные группы (клавишные, ударные и т. д.).
Формат сжатия звука МРЗ. Разработанный на основе исходного MPEG-1 стандарт МРЗ (сокращение от аудиоМРЕG, уровень 3) является одной из трех схем кодирования (Layer (уровень) I, Layer II и Layer III) для сжатия аудиосигналов. Общая структура процесса кодирования одинакова для всех уровней. Для каждого уровня определен свой формат записи битового потока и свой алгоритм декодирования. Алгоритмы MPEG основаны в целом на изученных свойствах восприятия звуковых сигналов слуховым аппаратом человека (т. е. кодирование производится с использованием так называемой «психоакустической модели»). Поскольку человеческий слух не идеален и восприимчивость слуха на разных частотах, в разных композициях различная, этим пользуются при построении психоакустической модели, которая учитывает, какие звуки, частоты, можно исключить, не нанося ущерба слушателю композиции.
Входной цифровой сигнал сначала раскладывается на частотные составляющие спектра. МРЗ-стандарт делит спектр частоты на 576 полос частоты и сжимает каждую полосу независимо. Затем этот спектр очищается от заведомо неслышных составляющих низкочастотных шумов и наивысших гармоник, т. е. фильтруется. На следующем этапе производится значительно более сложный психоакустический анализ слышимого спектра частот. Это делается в том числе с целью выявления и удаления «замаскированных» частот (частот, которые не воспринимаются слухом ввиду их приглушения другими частотами). Если два звука происходят в одно и то же время, МРЗ делает запись только того, который будет фактически воспринят. Тихий звук немедленно после громкого также может быть удален, так как ухо адаптируется к громкости. Если звук идентичен на обоих каналах стерео, этот сигнал сохраняется 1 раз, но воспроизводится на обоих каналах, когда МРЗ-файл декомпрессирован и озвучивается.
Затем, в зависимости от уровня сложности используемого алгоритма, может быть также произведен анализ предсказуемости сигнала. В довершение ко всему проводится сжатие уже готового битового потока упрощенным аналогом алгоритма Хаффмана (Huffman), что позволяет также значительно уменьшить занимаемый потоком объем.
Как было указано выше, стандарт MPEG-I имеет три уровня (Layer I, II и III). Эти уровни различаются по обеспечиваемому коэффициенту сжатия и качеству звучания получаемых потоков. Layer I позволяет сигналы 44,1 кГц/16 бит хранить без ощутимых потерь качества при скорости потока 384 Кбит/с, что составляет 4-кратный выигрыш в занимаемом объеме; Layer II обеспечивает такое же качество при 194 Кбит/с, a Layer III при 128. Выигрыш Layer III очевиден, но скорость компрессии при его использовании самая низкая (надо отметить, что при современных скоростях процессоров это ограничение уже незаметно).
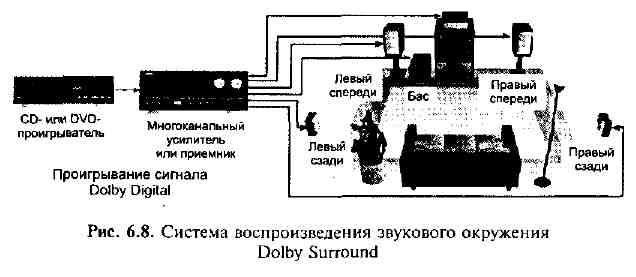
Системы воспроизведения звукового окружения. Воспроизведение звукового окружения начиналось со стереозаписей и УКВ ЧМ-радио. Широко использовались магнитофоны и FM-стереотюнеры с высококачественным двухканальным звуком. В кинотеатрах зрители могли оценить звук в формате Dolby Stereo Optical. Первые видеокассеты предполагали только монофонический звук посредственного качества, однако вскоре начали тиражироваться кассеты с двухканальным звуком. Сначала использовались просто раздельные звуковые дорожки, затем технология Hi-Fi. Лазерные диски с самого начала выпускались с двухканальным стереозвуком высокого качества. Вскоре и большинство стандартов вещательного телевидения были адаптированы для передачи видео с двухканальным звуковым сопровождением в эфире и в кабеле. Так популярный двухканальный формат звука стал тривиальной опцией домашнего видео. Первыми на рынке появились простые декодеры Dolby Surround, которые позволяли на домашней аппаратуре выделить и прослушать третий, пространственный канал surround channel. Впоследствии был разработан более интеллектуальный декодер, Dolby Surround Pro Logic, который выделял и центральный канал center channel. Получился «домашний кинотеатр» комплекс аппаратуры для высококачественного воспроизведения звука и видео с декодером Dolby Pro Logic Surround Sound (рис. 6.8).
В отличие от аппаратуры квадро, аппаратура Dolby Surround производилась и производится в массовых масштабах и постоянно совершенствуется. Во-первых, технология Dolby Pro Logic удачно совмещает оптимальную конфигурацию пространственных каналов (R, L, С, S) с возможностями записи и передачи (два физических канала), которыми обладает практически вся бытовая аппаратура. Во-вторых, возможности и качество Dolby Pro Logic отвечают актуальным требованиям современного пользователя. И, в-третьих, используются единые стандарты на аппаратные и программные средства.
Кодер Dolby Surround не предназначен для передачи четырех независимых сигналов звука, каждый из которых надо прослушивать раздельно (например, звука одной ТВ-программы на разных языках). В этом случае развязка между двумя любыми каналами должна была бы быть максимальной, а амплитуды и фазы сигналов могли бы быть совершенно не связаны между собой. Напротив, задача Dolby Surround передать четыре канала звука (soundtrack), которые будут прослушиваться одновременно и при этом воссоздавать в сознании слушателя пространственную звуковую картину (soundfield). Эта картина составляется из нескольких звуковых образов (sound images) звуков, которые слушатель воспринимает связанными со зрительными образами на экране. Звуковой образ характеризуется не только содержанием и мощностью звука, но и направлением в пространстве.
На входе кодера Dolby Surround присутствуют сигналы четырех каналов L, С, R и S, а на выходах два канала Lt (left total) и Rt (right total). Слово «total» (общий) означает, что каналы содержат не только «свой» сигнал (левый и правый), но и кодированные сигналы других каналов С и S. Функциональная схема кодера показана на рис. 6.9.
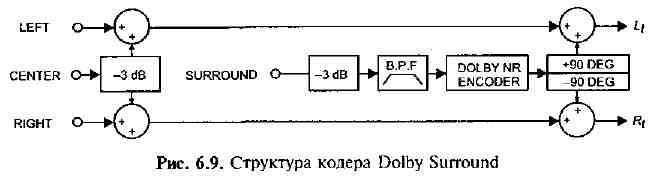
Сигналы каналов L и R передаются на выходы Lt и Rt без каких-либо изменений. Сигнал канала С делится поровну и складывается с сигналами каналов Lt и Rt. Предварительно сигнал С ослабляется на 3 дБ (чтобы сохранить неизменной акустическую мощность сигнала после сложения его «половинок» в матрице декодера). Сигнал канала S также ослабляется на 3 дБ, но, кроме того, перед сложением с сигналами Lt и Rt он подвергается следующим преобразованиям:
полоса частот ограничивается полосовым фильтром (BPF) от 100 Гц до 7 кГц;
сигнал обрабатывается шумоподавителем процессором Dolby B-type Noise Reduction;
сигнал S сдвигается по фазе на +90 и - 90 град., таким образом, составляющие сигнала S, предназначенные для сложения с Lt и Rt оказываются в противофазе друг с другом.
Совершенно ясно, что сигналы L и R не влияют друг на друга, они совершенно независимы. На первый взгляд не столь очевидно, но факт между сигналами С и S развязка теоретически также идеальная. Действительно: в декодере сигнал S получается как разность сигналов Lt и Rt. Но в этих сигналах присутствуют совершенно одинаковые компоненты сигнала С, которые при вычитании взаимно компенсируются. Напротив, сигнал С выделяется декодером, как сумма Lt и Rt. Так как компоненты сигнала S, присутствующие в этих сигналах, находятся в противофазе, при сложении они также взаимно компенсируются.
Такое кодирование позволяет передать сигналы S и С с высокой степенью развязки при одном условии: если амплитудные и фазовые характеристики физических каналов, по которым передаются сигналы Lt и Rt абсолютно идентичны. Если имеется некоторый дисбаланс между каналами, развязка уменьшается. Например, если компоненты сигнала С в каналах Rt и Lt из-за разных характеристик каналов передачи окажутся неодинаковыми, произойдет нежелательное проникновение (crosstalk) части сигнала С в канал S.