

Лекция №4 Статистические дискриминантные функции
4.1 Введение
Использование статистических дискиминантных функций для классификации имеет преимущество потому что (1) существует значительный объем знаний в таких областях как статистическая теория связи , теория обнаружения , теория решений и эти знания напрямую могут быть применены к распознаванию образов ; (2) статистическая формулировка очень хорошо подходит для проблемы распознавания образов, так как многие процессы распознавания имеют статистическую модель. В распознавании образов желательно использовать всю априорную информацию и характеристики системы часто вычисляются статистически.
В обучаемых статистических системах предполагаются в качестве основных такие функции плотности вероятностей как гауссово распределение или другие функции . Однако при неизвестных распределениях предполагается непараметрические методы обучения , которые мы обсуждали в частях 2 и3 .
Формулировка проблемы с точки зрения теории статистических решений
4.2.1. Функция потерь
Прежде, чем мы определим функцию потерь , полезно сделать следующие предположения.
p(i) известно или может быть оценено .
p(x/i) известно или может быть непосредственно оценено из обучающей последовательности.
p(i/x) обычно неизвестно.
Здесь p(I) – априорная вероятность классаI иp(X/I) – функция правдоподобия классаI или условная плотность вероятностейx.
Более подробно – это функция плотности вероятностей x при заданном состоянии природы i и p(i/x) – это вероятность того , что x получено из i . Обычно это называется постериорной вероятностью.
Функция потерь Lij может быть определена как потери , стоимость принятия решения , что xj , когда в действительности xi. Далее мы можем минимизировать средние потери. Условные средние потери или условный средний риск rk(x) могут быть определены как
rk(x)=![]() (4.1),
(4.1),
То-есть средние или ожидаемые потери ошибочной классификации x из класса k , при отнесении его к некоторым другим классам i , i=1, 2,….M и
i k.
Задачей классификатора тогда является найти оптимальное решение которое минимизирует средний риск или стоимость . Решающее правило тогда состоит из следующих шагов :
Вычислить ожидаемые потери ri(x) решения , что xi i, i=1,2, . . , M.
2. Решить , что xk если rk(x) ri(x) i k.
Соответствующая дискриминантная функция тогда имеет вид
dk(x) = - rk(x) (4.2)
Отрицательный знак перед rk(x) выбирается так чтобыdk(x) представляла наиболее правдоподобный класс . То-есть чемь меньшеrk(x) тем более правдоподобно , чтоxk .
Матрица потерь может быть представлена как
L=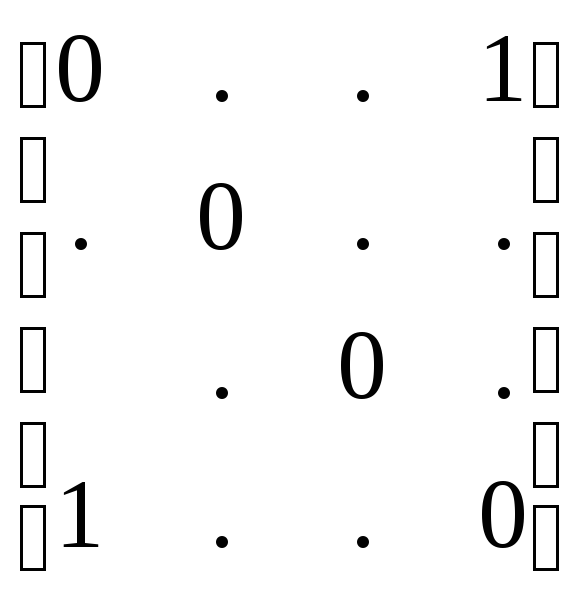 ,
,
где Lij=0, i=1,2,……M , так как неправильная классификация в этом случае отсутствует; в то время как Lij=1 соответствует неправильной классификации xk, когда в действительности xi , i=1,2,….,M, i k. Это симметрическая функция потерь с
Lik = 1- (k-i) , (4.4)
Где (k-i) -кронекеровская функция и
(k-i)=![]() (4.5)
(4.5)
Если величина Lik такова, что
Lik=![]() (4.6)
(4.6)
Матрица потерь становится отрицательной функциональной матрицей
Lneg
=![]()
 (4.7)
(4.7)
Значение этой отрицательной функциональной матрицы потерь состоит в том , что отрицательные потери (т.е. положительный выйгрыш ) соответствует правильному решению и нет потерь ссответствующих ошибочному решению .
Отметим, что hi не должны быть равны. Они могут быть различными для того указывать относительную важность принятия решения в пользу одного класса по сравнению с другим . Для двух классовой проблемы Lik = L21, где i=2, k=1.
Это означает , что x может принадлежать 2 , но неправильно классифицируется как 1. Lik = L12 , когда i=1, k=2, означает что x может принадлежать 1 , но будет классифицироваться как 2. Lik =0 когда i=k.