

7.9. Статические оперативные запоминающие устройства
Напомним, что роль запоминающего элемента в статическом ОЗУ исполняет триггер. Статические ОЗУ на настоящий момент – наиболее быстрый, правда, и наиболее дорогостоящий вид оперативной памяти. Известно достаточно много раз личных вариантов реализации SRAM, отличающихся по технологии, способа: организации и сфере применения (рис. 71).
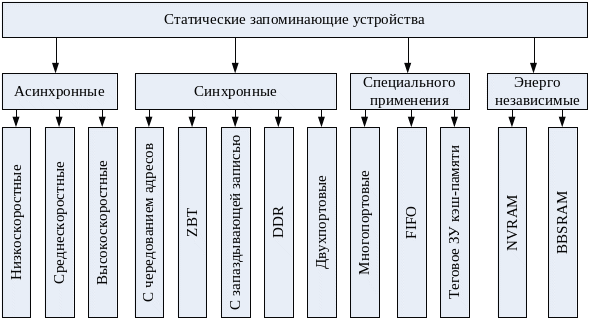
Рис. 71. Виды статических ОЗУ.
Асинхронные статические ОЗУ. Асинхронные статические ОЗУ применялись в кэш-памяти второго уровня в течение многих лет, еще с момента появления микропроцессора i80386. Для таких ИМС время доступа составляло 15-20 нс (в лучшем случае – 12 нс), что не позволяло кэш-памяти второго уровня работать в темпе процессора.
Синхронные статические ОЗУ. В рамках данной группы статических ОЗУ выделяют ИМС типа SSRAM и более совершенные РВ SRAM.
Значительно лучшие показатели по сравнению с асинхронными статическими ОЗУ достигнуты в синхронных SRAM (SSRAM). Как и в любой синхронной памяти, все события в SSRAM происходят с поступлением внешних тактовых импульсов. Отличительная особенность SSRAM – входные регистры, где фиксируется входная информация. Рассматриваемый вид памяти обеспечивает работу в пакетном режиме с формулой 3-1-1-1, но лишь до определенных значений тактовой частоты шины. При более высоких частотах формула изменяется на 3-2-2-2.
Последние модификации микропроцессоров Pentium, начиная с Pentium II, взамен SSRAM оснащаются статической оперативной памятью с пакетным конвейерным доступом (РВ SRAM – Pipelined Burst SRAM). В этой разновидности SRAM реализована внутренняя конвейеризация, за счет которой скорость обмена пакетами данных возрастает примерно вдвое. Память данного типа хорошо работает при повышенных частотах системной шины. Время доступа к РВ SRAM составляет от 4,5 до 8 нс, при этом формула 3-1-1-1 сохраняется даже при частоте системной шины 133 МГц.
Особенности записи в статических ОЗУ. Важным моментом, характеризующим SRAM, является технология записи. Известны два варианта записи: стандартная и запаздывающая. В стандартном режиме адрес и данные выставляются на соответствующие шины в одном и том же такте. В режиме запаздывающей записи данные для нее передаются в следующем такте после выбора адреса нужной ячейки, что напоминает режим конвейерного чтения, когда данные появляются на шине в следующем такте. Оба рассматриваемых варианта позволяют производить запись данных с частотой системной шины. Различия сказываются только при переключении между операциями чтения и записи.
Более детально различия режимов записи в SRAM рассмотрим на примере выполнения конвейерного чтения из ячеек с адресами А0, А1 и А2 с последующей записью в ячейку с адресом A3.
В режиме стандартной записи перед выработкой первого импульса синхронизации (ИС) на шину адреса выдается адрес первой ячейки для чтения А0. С приходом первого ИС этот адрес записывается во внутренний регистр микросхемы, и начинается цикл чтения. Перед началом второго ИС на шину адреса выставляется адрес следующей ячейки А1, и начинается второй цикл чтения. В это время данные из ячейки А0 поступают на шину данных. На третьем этапе выставляется адрес А2, а данные из ячейки А1 приходят на шину. В четвертом тактовом периоде предполагается запись, перед началом которой информационные выходы ИМС должны быть переведены в третье (высокоимпедансное) состояние. В результате данные из ячейки А1, появившиеся на шине только в конце третьего тактового периода, будут находиться там недостаточно долго, чтобы их можно было использовать. Таким образом, в третьем тактовом периоде данные не считываются и не записываются, и этот период называют холостым циклом. С началом четвертого такта данные, выставленные на шине данных, записываются в ячейку с адресом A3. Адрес следующей ячейки для чтения можно выставить только в пятом тактовом периоде, а соответствующие данные будут получены в шестом, то есть происходит еще один холостой цикл. В итоге за четыре такта произведены считывание из ячейки А0 и запись в ячейку A3. Как видно из описания, режим стандартной записи предусматривает потерю нескольких тактов шины при переключении между циклами чтения и записи. Если такая память используется в качестве кэш-памяти, то это не слишком влияет на производительность ВМ, так как запись в кэш-память происходит гораздо реже, чем чтение, и переключения «чтение/запись» и «запись/чтение» возникают относительно редко.
В режиме запаздывающей записи данные, которые должны быть занесены в ячейку, выставляются на шину лишь в следующем тактовом периоде. При этом данные, которые считываются из ячейки А1 в третьем такте, находятся в активном состоянии на протяжении всего тактового периода и могут быть беспрепятственно считаны в то время, когда выставляется адрес A3. Сами данные для записи передаются в четвертом такте, где в режиме стандартной записи имеет место холостой цикл. Как следствие, здесь за те же четыре такта считано содержимое двух ячеек (А0 и А1) и записаны данные по адресу A3.
Как видно из вышеизложенного, в обоих случаях адрес А2 игнорируется. Реально никакой потери адресов и данных не происходит. Контроллер памяти непосредственно перед переключением из режима чтения в режим записи просто не передает адрес на шину, так как «знает», какой тип памяти используется и сколько тактов ожидания нужно ввести перед переходом «чтение/запись» и обратно.
Компания IDT (Integrated Device Technology) в развитие идеи записи с запаздыванием предложила новую технологию, получившую название ZBT SRAM (Zero Bus Turnaround) — нулевое время переключения шины. Идея ее состоит в том, чтобы запись с запаздыванием производить с таким же интервалом, какой требуется для чтения. Так, если SRAM с конвейерным чтением требует три тактовых периода для чтения данных из ячейки, то данные для записи нужно передавать с таким же промедлением относительно адреса. В результате перекрывающиеся циклы чтения и записи идут один за другим, позволяя выполнять операции чтения/записи в каждом такте без каких-либо задержек.