

3.3. Доступ к ячейкам памяти
Как уже отмечалось, в состав любой микропроцессорной системы обязательно должна входить память, в которой располагаются программы и необходимые для их работы данные. Физическая и логическая организации памяти могут существенно отличаться. При программировании на языке ассемблера память можно рассматривать как массив ячеек, каждая из которых имеет размерность, равную одному байту. При выполнении некоторых команд микропроцессора некоторые участки памяти можно рассматривать как массив из слов, двойных слов и т.п.
В отличии от регистров микропроцессора доступ к ячейкам памяти осуществляется с помощью чисел (адресов), а не имен. В программах языка ассемблера оперирует с адресом, состоящим из адреса начала сегмента и смещения относительно начала этого сегмента. Смещение называется исполнительным адресом (effective address). По определенным правилам адрес преобразуется. к логическому адресу. Правила преобразование зависят от режима работы микропроцессора – реального и защищенного. В реальном режиме работы микропроцессора логический адрес непосредственно подается на шину адреса т.е. совпадает с физическим адресом. В защищенном режиме правила получения логического адреса отличаются от реального режима, а при использовании страничной организации логические адреса могут отличаются от физического.
В микропроцессоре i8086 шина адреса состоит из 20 линий, следовательно этот микропроцессор может адресовать 220 байт. Однако размерности регистров, с помощью которых они адресуются, ограничена 16 битами. Поэтому при формировании адреса из двух частей (сегмента и смещения внутри этого сегмента) используется следующая формула:
ЕА = As * 16 + Ао,
где ЕА – логический адрес ячейки памяти, As – адрес начала сегмента (содержимое одного из сегментных регистров – с для сегмента кода, SS для сегмента стека, DS и ES для сегментов данных), Ао – смещение относительно начала сегмента ( содержимое регистра IP для сегмента кода, SP для сегмента стека и смещение адреса переменной, расположенной в сегменте данных).
Умножение 16-разрядного регистра на.16 означает его сдвиг на 4 разряда влево, причем 4 младшие разряда получающегося 20-разрядного числа заполняются нулями. Тогда эту формулу можно проиллюстрировать на рис. 33.
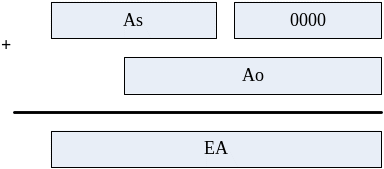
Рис. 33. Формирование исполнительного адреса в реальном режиме.
Так как при вычислении адреса к сегментному адресу добавляется 4 нулевых разряда, это значит, что начало любого сегмента (т.е. при нулевом смещении) может находится только по адресу, кратному 24 = 16 байт. Область памяти в 16 байт называется параграфом поэтому, сегменты в программе всегда начинаются с начала (выровнены на границе) параграфа.
Исходя из того, что адрес образуется из двух компонент, для записи его будет использоваться следующая форма – As:Ao – сегментный адрес и смешение, разделенные двоеточием. Например, запись 400:20 определяет следующий логический адрес (As = 400h, Ао = 20h):
EA = 400h * 16 + 20h = 4000h+ 20h =4020h.
В подавляющем большинстве случаев число всегда можно представить в виде суммы разных пар чисел, поэтому возможно несколько вариантов определения одного и того же адреса. Например, адрес 4020h соответствует вариантам 401:10, 402:0 и т.д.
Так как в программах начальный адрес сегмента всегда определяется содержимым одного из сегментных регистров, то в некоторых случая адреса будут записываться в виде, например, DS:10. В этом случае адрес составляют текучее значение регистра сегмента данных DS и смещение в 10h байт по отношению к началу сегмента данных. Кроме того, так как в программах на языке ассемблера может использоваться косвенная адресация, то допустима также и запись адреса, например, в таком вида – SS:BP (содержимое сегментного регистра SS определяет компоненту As, а регистра ВР – компоненту Ао адреса).
Так как при определении адреса используются две компоненты, то при определении некоторого адреса в программе можно использовать или одну часть адреса (оставляя другую неизменной – обычно используется смещение внутри сегмента), или обе компоненты. В первом случае адрес называется ближним (near adress), во втором – дальним (far address)..
При определении ближнего адреса удобно использовать компоненту адреса, задаваемую смещением, оставляя сегментный адрес неизменным. В этом случае можно легко организовать доступ к любой ячейке памяти, лежащей внутри соответствующего сегмента (например, использовать все переменные, находящиеся в сегменте данных, зная только смещения этих переменных). Так как максимальное значение смещения может быть 216 = 65536 = 64 Кбайт, то именно эта величина и определяет максимальную длину любого сегмента в реальном режиме работы микропроцессора. При дальнейшем увеличении смещения значение этой компоненты станет равной 0 (0FFFFh + 1 = 10000h, но переполнение не сохраняется в шестнадцатиразрядном регистре, поэтому результат будет равен 0000h) и, следовательно, с помощью ближнего адреса невозможно получить доступ к элементу памяти, лежащему за пределами 64 Кбайт от начала сегмента (с помощью ближней адресации невозможно работать с массивом данных, превышающим 64 Кбайт).
При адресации с помощью дальнего адреса изменяются обе компоненты адреса сегмент и смещение, поэтому с помощью такой адресации принципиально можно обратиться к любой ячейке памяти во всем диапазоне адресов микропроцессорной системы.
Дальний адрес, у которого смещение не превышает 15 байт (т.е. находится в пределах одного параграфа), называется "громадным" адресом (huge address). Такая нормализация дальнего адреса при которой может измениться и значение начала сегмента, позволяет организовать доступ к элементам памяти, занимающим размер более 64 Кбайт.
Следует отметить, что использование ближнего адреса для доступа к некоторой ячейке памяти происходит быстрее, чем с помощью дальней адресации, так как изменяется только одна из компонент адреса.