

16 Суперскалярный параллелизм. Суперскалярная обработка.
Параллелизм на уровне команд имеет место, когда обработка нескольких команд или выполнение различных этапов одной и той же команды может перекрываться во времени. Разработчики вычислительной техники издавна прибегали к методам, известным под общим названием «совмещения операций*-, при котором аппаратура ВМ в любой момент времени выполняет одновременно более одной операции. Этот общий принцип включает в себя два понятия: параллелизм и конвейеризацию. Хотя у них много общего и их зачастую трудно различать на практике, термины эти отражают два принципиально различных подхода.
В первом варианте совмещение операций достигается за счет того, что в составе вычислительной системы отдельные устройства присутствуют в нескольких копиях Так, в состав процессора может входить несколько АЛУ, и высокая производительность обеспечивается за счет одновременной работы всех этих АЛУ. Второй подход был описан ранее.
Термин скалярный параллелизм соответствует параллелизму операций внутри тела цикла или отдельного выражения. Вместо термина “скалярный” часто используется термин “локальный параллелизм”, чтобы отличить его от “глобального параллелизма”, соответствующего параллелизму итераций цикла или независимых ветвей программы.
Скалярный параллелизм определяется в границах базового блока (ББ), под которым понимают отрезок программы, не содержащий условных или безусловных переходов. ББ обычно содержит одно или несколько выражений ЯВУ.
Из закона Амдала:
с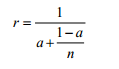 ледует,
что значение ускорения r
весьма чувствительно к удельной величине
скалярной части вычислений a,
поэтому в быстродействующих ЭВМ
прикладывают значительные усилия для
распараллеливания скалярных участков.
Результаты анализа программ показывают,
что в одном такте можно выполнить 1,5...2
операции или команды. Комплексную
команду, содержащую больше одной
параллельной команды, называют длинной
командой (ДК). Если число параллельных
операций превышает 2, то такой параллелизм
называется суперскалярным, а команда
— сверхдлинной (СДК).
ледует,
что значение ускорения r
весьма чувствительно к удельной величине
скалярной части вычислений a,
поэтому в быстродействующих ЭВМ
прикладывают значительные усилия для
распараллеливания скалярных участков.
Результаты анализа программ показывают,
что в одном такте можно выполнить 1,5...2
операции или команды. Комплексную
команду, содержащую больше одной
параллельной команды, называют длинной
командой (ДК). Если число параллельных
операций превышает 2, то такой параллелизм
называется суперскалярным, а команда
— сверхдлинной (СДК).
Аппаратная реализация суперскалярной обработки применяется как в CISC, так и в RISC - процессорах и заключается в чисто аппаратном механизме выборки из буфера инструкций (или кэша инструкций) несвязанных команд и параллельном запуске их на исполнение. Этот метод хорош тем, что он «прозрачен» для программиста, составление программ для подобных процессоров не требует никаких специальных усилий, ответственность за параллельное выполнение операций возлагается в основном на аппаратные средства.
VLIW-архитектуры суперскалярной обработки. Второй способ реализации суперскалярной обработки заключается в кардинальной перестройке всего процесса трансляции и исполнения программ. Уже на этапе подготовки программы компилятор группирует несвязанные операции в пакеты, содержимое которых строго соответствует структуре процессора. Например, если процессор содержит функционально независимые устройства (сложения, умножения, сдвига и деления), то максимум, что компилятор может «уложить» в один пакет - это четыре разнотипные операции; (сложение, умножение, сдвиг и деление). Сформированные пакеты операций преобразуются компилятором в командные слова, которые по сравнению с обычными инструкциями выглядят очень большими. Отсюда и название этих суперкоманд и соответствующей им архитектуры - VLIW (Very Large Instruction Word - очень широкое командное слово). По идее, затраты на формирование суперкоманд должны окупаться скоростью их выполнения и простотой аппаратуры процессора, с которого снята вся «интеллектуальная» работа по поиску параллелизма несвязанных операций. Однако практическое внедрение VLIW-архитектуры затрудняется значительными проблемами эффективной компиляции.
Архитектуры класса SISD охватывают те уровни программного параллелизма, которые связаны с одиночным потоком данных. Они реализуются многофункциональной обработкой и конвейером команд.
Параллелизм циклов и итераций тесно связан с понятием множественности потоков данных и реализуется векторной обработкой. В таксономии компьютерных архитектур М. Флина выделена специальная группа однопроцессорных систем с параллельной обработкой потоков данных — SIMD.