

Міністерство охорони здоровя України
львівський Національний медичний університет
Імені данила галицького
« Затверджено »
на методичній нараді
кафедри медичної інформатики .
Завідувач кафедри
професор Готра О.З._____________
«___»_____________ 200 р.
Методичні рекомендації
для самостійної роботи студентів
при підготовці до практичного заняття
Навчальна дисципліна |
Медична інформатика |
Модуль №3 |
Основи інформаційних технологій в системі охорони здоров’я. Обробка та аналіз медико-біологічних даних |
Змістовий модуль №4 |
Основні поняття медичної інформатики. Комп’ютер у діяльності майбутнього лікаря |
Тема заняття 16: |
Передача інформації. Мережеві технології. Основи телемедицини |
Курс: |
ІІ |
Факультет: |
Медичний |
Львів - 2009
Актуальність теми.
Мета заняття: ознайомитися з призначенням всесвітньої мережі Internet, оволодіти принципами пошуку інформації в Internet, ознайомитися з основними серверами медичних ресурсів; демонструвати навички використання основних медичних ресурсів Internet
Базовий рівень підготовки
Назви попередніх дисциплін |
Отримані навики |
Елективний курс «Європейський стандарт комп’ютерної грамотності» |
Володіти навичками роботи з основними складовими програмного забезпечення комп’ютера; запускати на виконання програми, що працюють під управлінням операційної системи і коректно завершувати їх роботу |
Перелік основних термінів:
Інформація - це відображене знання і зареєстровані стани навколишнього середовища. Відображення (уявлення) знань виконується людиною засобами будь-якої знакової системи (формальні і природні мови, малюнки, мови жестів, ноти ...). У свою чергу реєстрація станів навколишнього середовища проводиться технічними засобами і генерує технічну інформацію (числа, сигнали, зображення, звуки ..., їх поєднання і тимчасові ряди ...).
Метадані - інформація про інформацію. Метадані про об'єкт (текст...) можна умовно розділити на атрибути об'єкту в цілому (реквізит) і, можливо, змістовні ознаки його структурних одиниць (якщо такі можна виділити). Якщо не вирішена проблема автоматизації формування метаданих - реальна колекція документів не може бути впорядкована і втрачає одну з критичних корисних функцій - можливість оперативного доступу. Вручну вводити метадані з урахуванням об'ємів архівів (сотні тисяч / мільйонів документів) і нових надходжень (сотні / тисячі документів щодня) нереально. На довершення до повнотекстового індексу бази даних в базі знань формується метаіндекс, де об'єктом зберігання є метадані - інформація про те, в яких документах або фрагментах їх тексту згадується лексика конкретного поняття з класифікатора або реєстру.
Інформаційний пошук (ІП) (англ. Information retrieval) — наука про пошук неструктурованої документальної інформації. Особливо це відноситься до пошуку інформації в документах, пошук самих документів, здобуття метаданих з документів, пошуку тексту, зображень, відео та звуку у локальних реляційних базах даних, у гіпертекстових базах даних таких, як Інтернет та локальні інтранет. Для інформаційного пошуку розробляють: алгоритми інформаційного пошуку; підходи інформаційного пошуку; стратегії інформаційного пошуку. Для його здійснення створюють: методи інформаційного пошуку; засоби інформаційного пошуку; комп’ютерні пошукові програми. До проблем інформаційного пошуку належать питання: представлення даних, інформації, знань; представлення інформації в сучасних інформаційних сховищах; багатомовний інформаційний пошук; одночасний інформаційний пошук; розподілений інформаційний пошук.
Реквізит документа (requisit) - вид метаданих, атрибут документа, який характеризує його як єдине ціле (запис в базі даних). Сукупність реквізитів документа утворює його бібліографічний опис. Традиційно до реквізитів відносять вид об'єкту, формат даних, автора, дати публікації, написання, мова тексту.
Змістовна ознака структурної одиниці документа, дескриптор (descriptor) поняття - вид метаданих, що відноситься до фрагмента документа. Це може бути поняття (елемент ситуації або проблеми) або ситуація (сукупність понять), лексичний образ яких міститься в структурній одиниці документа (група слів, пропозиція). Змістовні ознаки структурних частин документів дозволяють забезпечити доступ до фрагментів документів корпоративного сховища, що вирішують проблему користувача по аналогії від супротивного або з використанням іншого правила вибірки Крім того, важливою особливістю корпоративних сховищ, що підтримують маніпуляції із змістовними ознаками частин документів, є можливість формувати компактний звіт про можливі методи дозволу проблеми з відповідних фрагментів потрібних документів.
Індексація сайту — процес аналізу пошуковим роботом змісту веб-сайту для внесення його в базу пошуковика. Правила індексації різні для кожної пошукової системи, вони зберігаються у таємниці. В подальшому результати індексації використовуються пошуковою системою для виявлення відповідності (релевантності) змісту сайту даному запиту.
Запит - слово або словосполучення, яке вводить користувач в пошуковій системі для отримання необхідної інформації. У відповідь система видає список сайтів, відсортованих по релевантності даному запиту.
Контент - інформаційне наповнення інтернет-сайтів.
Портал - багатофункціональний сервер зі зручним інтерфейсом і системою засобів, що полегшують користувачам навігацію в глобальній мережі, який надає велику сукупність послуг, наприклад, пошук у www-системі, архівах новин, на FTP-серверах, перегляд стислих новин, біржових котирувань, результати спортивних змагань, відкриття безплатної електронної адреси, розташування Web-сторінок користувачів, участь в чатах тощо.
Хост - IP-адреса відвідувача, вперше зафіксована веб-сервером або сервісом статистики протягом певного періоду часу (доби, години). Один унікальний відвідувач може зарахуватися як один хост (якщо він має виділений тільки для нього IP-адреса), не вважатися хостом взагалі (якщо IP-адреса закріплена за групою користувачів, наприклад, за проксі сервером, за допомогою якого декілька користувачів здійснюють доступ в інтернет, і з цієї адреси вже були зафіксовані відвідини) або вважатися за декілька хостов (якщо IP виділяється користувачу динамічно, скажімо, при доступі через dialup connection)
Хостинг - фізичне розміщення сайту на дисковому просторі специалізірованого комп'ютера. До цього комп'ютера поступатимуть запити браузерів, в адресному рядку яких вказана IP-адреса або доменне ім'я цього сайту..
Дорвей (Doorway) - вхідні сторінки (дорвеі) - це сторінки, спеціально оптимізовані під конкретний пошуковий запит до конкретної пошукової системи. Даних сторінок може бути дуже багато. Для кожного ключового слова (словосполучення) і пошукача власна сторінка. А також, сторінка, основний зміст якої відшуковувати відвідувачів пошукових систем для того, щоб перенаправити трафік на головний сайт веб-майстер, замовника або власника дорвея шляхом перенаправлення.
Контекст (context) - загальна зупинка, ситуація, оточення події, дії, твердження, роботи і тому подібне Рішення приймаються людиною в контексті її інтуїції, знань, досвіду, загальної життєвої стратегії, рівня сприйняття фактів, настрою, самопочуття і інших виключно суб'єктивних чинників. Лексичний (лінгвістичний) контекст (словесне оточення) - лексична позиція слова в рамках тексту (документа) уточнює значення слова. Вузький контекст - лінгвістичний контекст, що знаходиться в межах групи слів або пропозиції. Широкий контекст - лінгвістичний контекст, що виходить за межі пропозиції, в якій спожита мовна одиниця. Відповідно, під об'ємом контексту розуміється число структурних одиниць тексту (слово, пропозиція, абзац), наприклад, "в групі з 10 суміжних слів". Розмовний або екстралінгвістичний контекст - обстановка, час і місце, до яких відноситься вислів, а також факти реальної дійсності, знання яких допомагає правильно зрозуміти значення слів (вчинків). Фундаментальним пороком пошукових систем і баз даних є неможливість виконувати логічні умови, що виходять за рамки одного документа.
Тезаурус (thesaurus) - сукупність одиниць деякої мови, що виражають сенс, із заданою системою смислових (семантичних) і асоціативних стосунків. До звичайних одиниць тезауруса можна віднести схожість - синоніми, зіставлення - антоніми, супідрядність - "рід-вигляд", укорочення - скорочення, розчленовування - "частина - ціле", причина - слідство і ін. Тезаурус може описувати сенс (семантику) конкретної природної мови або термінологію конкретної галузі знань. Через асоціативні стосунки, специфічні для даної тематичної сфери: хвороба - збудник, прилад - призначення (або вимірювана величина) і т. п., тезаурус може використовуватися для опису системи знань про дійсність. Залежно від призначення тезаурус близький до бази даних пошукових слів (у інформаційних технологіях - інформаційно-пошуковий тезаурус) і таксономії (штучний інтелект. Приклади: багатомовний тезаурус Европарламенту Eurodicautom <<http://europa.eu.int/eurodicautom/Controller>> або Тезаурус ділової лексики на Яндекс http://www.onlineci.ru/yandexcd.htm.
Класифікатор - система рубрик (основ) і зв'язків між ними, яка в сукупності є базовою для впорядкування (систематизації) всіх варіантів понять (а не термінів), що класифікуються, розподіли їх по рубриках. Класифікація - класифікатор, рубрики нижнього рівня якого наповнені описами конкретних понять. Поняття "класифікація" використовується з обов'язковим другим поняттям - підставою класифікації (наприклад, "класифікація галузей знання", "класифікація товарів", "класифікація конкурентів").
Таксономія (taxonomy) - ієрархічна класифікація понять або принципи побудови класифікацій. У математиці таксономія - деревовидна класифікація об'єктів вибраного типу.
РageRank — це числова величина, що характеризує «важливість» сторінки. Чим більше посилань на сторінку, тим вона стає «важливішf». Крім того, «вага» сторінки A
визначається вагою посилання, передаваною сторінкою B. Отже, PageRank| — це метод обчислення ваги сторінки шляхом підсумку важливості посилань на неї.
Семантичний Інтернет - напрям розвитку інформаційних технологій, головне завдання якого - удосконалення проблемно-орієнтованого пошуку інформації через Інтернет. За задумом автора (Тім Бернерс-Лі / Tim Berners-lee) цього можна добитися включенням в документи додаткової змістовної розмітки (метаданих), зрозумілої роботам пошукових систем, розробкою уніфікованих онтологій загального призначення для стандартизації кодування метаданих, розробкою і використанням нових форматів представлення даних в Інтернет, спеціалізованих роботів, web-сервісів і тому подібне
Онтологія — це загальноприйнята і загальнодоступна концептуалізація певної області знань (світу, середовища), яка містить базис для моделювання цієї області знань і визначає протоколи для взаємодії між агентами, які використовують знання з цієї області, і, нарешті, включає домовленості про представлення теоретичних основ даної області знань.
Адресація в Internet
В основу маршрутизації в Інтернет покладено IP-адресу. IP-адреси — це 32-бітові числа, що розбиваються на октети (восьми бітові числа), які записують у вигляді послiдовностi з чотирьох чисел, розділених крапками, наприклад 124.44.186.11. Кожне число може бути в інтервалі від 0 до 255, що відповідає інформаційному обсязі в 1 байт або 8 біт. Таким чином, IP-адреса – це 4 байти або 32 біта. Перші три частини адреси позначають належність до певного класу мереж, а остання є унікальною для окремого комп’ютера. Коли формується мережа, їй присвоюється номер, який визначає кількість машин у межах цієї мережі. IP-адреси окремим машинам призначають із заданого так діапазону. Інформація, що передається, розбивається на пакети, у кожному з яких вказується адреса. Пакети доставляються незалежно один від одного і збираються у вузлі-одержувачі.
Існує 5 класів IP| – адрес – A, B, C, D, E|. Приналежність IP| – адреси до того або іншого класу, визначається значенням першого октету.
Клас |
Перше число в адресі |
Можлива кількість мереж
|
Можлива кількість комп’ютерів в однієї мережі
|
Вид адреси
|
A |
0-127 |
126 |
16 777 216 |
sss.xxx.xxx.xxx |
B |
128-191 |
16 382 |
65 536 |
sss.sss.xxx.xxx |
C |
192-223 |
2 097 150 |
256 |
sss.sss.sss.xxx |
D |
224-239 |
|
застосовують для багатоадресних розсилок |
где sss- номер сети |
E |
240-255 |
|
зареєстровані для експериментальних цілей |
xxx - номер хосту |
IP| – адреси перших трьох класів призначені для адресації окремих вузлів і окремих мереж. Такі адреси складаються з двох частин|часток| – номер мережі і номер вузла. Адреси різних класів відрізняються розрядністю їх номерів, що визначає можливий їх діапазон значень. Адреси D використовуються для адресації груп комп'ютерів, а діапазон адрес E зарезервований і в даний час|нині| не використовується. IP-адреса можуть бути статичними і динамічними. Для сервера, на якому зберігається інформація, необхідна постійна IP-адрес|, інакше дані не будуть знайдені. Для користувача, що входить в Інтернет на декілька годинників, IP-адрес| може бути виділений динамічно з|із| деякої кількості вільних номерів.
Для адміністрування (керування) мережею така система адресації зручна, а ось для користувачів - ні. Не зручно постійно пам'ятати набори цифр, їх можна легко переплутати, крім того, вони можуть змінюватися. Тому поряд з ІР- адресацією була введена доменна система імен. Кожен рівень в такій системі називається доменом. Типове ім'я домену складається з декількох частин, розташованих в певному порядку і розділених крапками. Домени відділяються один від одного крапками, наприклад: fizmat.tnpu.edu.ua
Доменна структура Інтернет є ієрархічною. Найвищий (кореневий) рівень не має назви. Далі йде обмежена кількість доменів верхнього рівня, в яких може бути практично необмежена кількість доменів 2-го рівня і т. д. Імена доменів верхнього рівня (Top Level Domains, TLDs) стандартизовані. Їх можна поділити на два типи: описові імена родових доменів (generic Top Level Domains, gTLDs) та імена, які визначають розміщення домену. Адреса комп’ютера може мати ім’я одного з цих типів (але не обидва разом).
Найпоширенішими є родові домени, які визначають прикладний напрямок мережі: .com — комерційні організації, .edu — освітні установи, .gov — урядові установи, .int — міжнародні організації, .mil — військові установи, .net — мережні організації, .org — організації, які не належать жодній іншій категорії.
З 1997 року було впроваджено нові домени верхнього рівня, серед яких: .aero — авіатранспорт, .arts — культура і розваги, .biz — бізнес, .coop — кооперативи, .firm — бізнес , .info — інформаційні послуги, .museum — музеї, .name — приватні особи, .nom — персональні, .pro — професіонали (юристи, економісти і т. п.), .rec — відпочинок і розваги, .shop — магазини, .web — WWW-діяльність, store - для торгівлі.
Імена географічних доменів завжди подаються як двобуквене скорочення назви країни, зазвичай, згідно зі стандартом ISO-3166-1 (звідси їх позначення — ccTLDs, country-code Top Level Domains, домени верхнього рівня з кодами країн). Приклади: uа — Україна, ca — Канада, eu — Європейський Союз, uk — Великобританія, us — США, fr- Франція, jp – Японія, It – Італія, ru - Росія.
За призначенням домени поділяють на публічні (спільного користування) — такі, що адмініструються в інтересах певної спільноти, та приватні, що адмініструються певною фізичної або юридичною особою у своїх власних інтересах. Так, домен .UA адмініструється в інтересах української Інтернет-спільноти — спільноти всіх громадян і/або резидентів України, фізичних та юридичних осіб, органів державної влади та управління України, органів місцевого самоврядування, які використовують мережу Інтернет та Інтернет-технології, незалежно від мети та способів такого використання.
У публічному домені можуть бути як публічні, так і приватні піддомени згідно з правилами публічного домену попереднього рівня, а у приватному домені публічні доменні імена неможливі.
Localhost (127.0.0.1—127.255.255.254) — IP-адреса спеціального мережевого інтерфейсу внутрішньої петлі («loopback») у мережевому протоколі TCP/IP. В юніксоподібних операційних системах цей інтерфейс іменується «lo». Означає той самий мережевий пристрій (комп'ютер, мережевий принтер тощо), з якого відсилається мережевий пакет або встановлюється зв'язок. Використання адреси 127.0.0.1 дозволяє встановлювати зв'язок та передавати інформацію для програм-серверів, що працюють на тому самому комп'ютері, що й програма-клієнт, незалежно від конфігурації апаратних мережевих засобів комп'ютера. Це знімає необхідність використання додаткових протоколів для роботи клієнт-серверних програм на одному комп'ютері. Як правило, інтерфейс, відповідний до адресу 127.0.0.1, існує виключно як програмна абстракція на рівні ядра операційної системи. Зазвичай до адреси 127.0.0.1 однозначно відповідає мнемонічне ім'я комп'ютера «localhost» або «localhost.localdomain».
Універсальний покажчик ресурсу
IP-адреса або відповідне йому доменне ім'я дозволяють однозначно ідентифікувати комп'ютер у мережі Internet, але справа в тому, що на комп'ютері може міститися безліч різної інформації в різних форматах, наприклад, у вигляді файлів, електронних повідомлень, сторінок і т.п.
Для популярних, добре відомих, протоколів, номер порту може не приводитись, тоді використовується стандартний порт (наприклад, порт номер 80 для HTTP).
Універсальний покажчик ресурсу складається з:
<протокол>://<сервер>[:<порт>][/<шлях>][/<файл>[#<розділ>]]
Протокол – це набір правил, за якими відбувається обмін інформацією. Наприклад, протокол http:// – протокол передачі гіпертексту.
Доменне ім'я або IP-адреса, що дозволяє однозначно ідентифікувати комп'ютер (сервер) у мережі Internet, що містить потрібну інформацію.
Шлях складається з імен папок, розділених символом / (слеш), послідовно в які можна «добратися» до потрібної інформації. Наприклад, products/medic/library, тут шукана інформація знаходиться в папці library, що знаходиться в папці medic, що у свою чергу розташовується в середині папки products.
Ім'я файлу – файл, що містить потрібну інформацію.
Загальнf схему інформаційно-пошукової системи (ІПС) Internet .
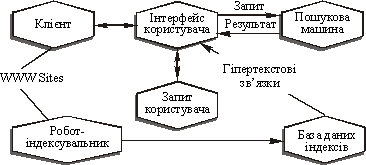
Рис. Типова схема інформаційно-пошукової системи
Клієнт — це програма перегляду конкретного інформаційного ресурсу. Програма забезпечує перегляд документів WWW, Gopher, Wais, FTP-архівів, поштових списків розсилки і груп новин Usenet. У свою чергу всі ці інформаційні ресурси є об’єктом пошуку інформаційно-пошукової системи.
Інтерфейс користувача — це не просто програма перегляду, у разі інформаційно-пошукової системи під цим словосполученням розуміють також спосіб спілкування користувача з пошуковим апаратом, системою формування запитів і перегляду результатів пошуку.
Пошукова машина — застосовується для трансляції запиту на інформаційно-пошукову мову (ІПМ), у формальний запит системи, пошуку посилань на інформаційні ресурси мережі і видачі результатів цього пошуку користувачеві.
Бази даних індексів — це основний масив даних ІПС, використовуваних для пошуку адреси інформаційного ресурсу. Архітектура індексу влаштована таким чином, щоб пошук відбувався максимально швидко і при цьому можна було б визначити цінність кожного із знайдених інформаційних ресурсів мережі.
Запити користувача — зберігаються в його (користувача) особистій базі даних. На відлагодження кожного запиту йде досить багато часу, і тому надзвичайно важливо запам’ятовувати запити, на які система дає гарні відповіді.
Робот-індексувальник — застосовується для сканування Internet і підтримки бази даних індексу в актуальному стані. Ця програма є основним джерелом інформації про стан інформаційних ресурсів мережі.
WWW sites — це весь Internet або точніше — інформаційні ресурси, перегляд яких забезпечується програмами перегляду.