

1. Предварительный анализ данных - Излагается типология шкал измерения экономических показателей – номинальная, порядковая, интервальная и относительная. Формулируются их свойства, приводятся допустимые преобразования. Изучается специфика использования номинальных факторов в эконометрических моделях. Излагаются методы предварительного анализа данных, которые позволяют выполнить предварительную идентификацию (спецификацию) модели линейной или сводящейся к линейной регрессии – анализ диаграмм рассеивания, диаграмм Бокса-Уискера, анализ свойств матрицы корреляций между независимыми переменными (факторами) и зависимой (результирующей) переменной.
Уровни исследуемого показателя обяз.должны быть:сопоставимы,т.е.одинаковые ед.измерения.,методика расчета и т.д.;однородными,т.е.отсутствие аномальных наблюдений,к-ые резко искажают результаты моделирования;устойчивыми,т.е. на графике визуально должна прослеживаться закономерность;число уровней должно быть достаточно велико. Для визуальной оценки исходных данных строится диаграмма рассеивания.вид точечного графика позволяет сделать предварительный вывод о наличии линейной связи между переменными,если точки на графике лежат близко к воображ.прямой. Для диагностики аномальных наблюдений используется метод Ирвина. Для всех или только подозреваемых в аномальности наблюдений вычисляетсявеличина λi
Λi=[yi-yi-1]/Sy Sy=√∑(yi-y⁻)2/n-1.Если рассчитанная величина превышает табл.уровень то уровень Yi считается аномальным.Строим диаграмму рассеивания. Располож.точек на точечном графике позволяет сделать предварит.вывод о связи между переменными.
2.
Проверка
гипотезы о распределения случайной
величины
- Выдвигается
гипотеза
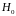 об отсутствии автокорреляции остатков.
Альтернативные гипотезы
об отсутствии автокорреляции остатков.
Альтернативные гипотезы
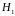 и
и
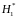 состоят, соответственно, в наличии
положительной или отрицательной
автокорреляции в остатках. Далее по
специальным таблицам (см. приложение
E)
определяются критические значения
критерия Дарбина-Уотсона
состоят, соответственно, в наличии
положительной или отрицательной
автокорреляции в остатках. Далее по
специальным таблицам (см. приложение
E)
определяются критические значения
критерия Дарбина-Уотсона
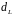 и
и
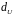 для заданного числа наблюдений
для заданного числа наблюдений
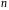 ,
числа независимых переменных модели
,
числа независимых переменных модели
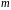 и уровня значимости
и уровня значимости
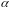 .
По этим значениям числовой промежуток
.
По этим значениям числовой промежуток
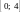 разбивают на пять отрезков. Принятие
или отклонение каждой из гипотез с
вероятностью
разбивают на пять отрезков. Принятие
или отклонение каждой из гипотез с
вероятностью
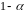 осуществляется следующим образом:
осуществляется следующим образом:
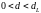 – есть положительная
автокорреляция остатков,
отклоняется, с вероятностью
– есть положительная
автокорреляция остатков,
отклоняется, с вероятностью
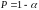 принимается
;
принимается
;
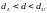 – зона неопределенности;
– зона неопределенности;
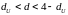 – нет оснований
отклонять
,
т.е. автокорреляция остатков отсутствует;
– нет оснований
отклонять
,
т.е. автокорреляция остатков отсутствует;
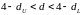 – зона неопределенности;
– зона неопределенности;
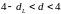 – есть отрицательная
автокорреляция остатков,
отклоняется, с вероятностью
принимается
.
– есть отрицательная
автокорреляция остатков,
отклоняется, с вероятностью
принимается
.
Если фактическое значение критерия Дарбина-Уотсона попадает в зону неопределенности, то на практике предполагают существование автокорреляции остатков и отклоняют гипотезу .
3.

4.Доверительные
интервалы для зависимой переменной
b+ax-t*Sост Рассчитаем
границы интервала, в котором будет
сосредоточено 95% возможных значений Y
при неограниченно большом числе
наблюдений и X = 1
Рассчитаем
границы интервала, в котором будет
сосредоточено 95% возможных значений Y
при неограниченно большом числе
наблюдений и X = 1
5. Корреляционный анализ — метод обработки статистических данных, с помощью которого измеряется теснота связи между двумя или более переменными. Корреляционный анализ тесно связан с регрессионным анализом (также часто встречается термин «корреляционно-регрессионный анализ», который является более общим статистическим понятием), с его помощью определяют необходимость включения тех или иных факторов в уравнение множественной регрессии, а также оценивают полученное уравнение регрессии на соответствие выявленным связям (используя коэффициент детерминации). Ограничения корреляционного анализа
Множество корреляционных полей. Распределения значений (x, y) с соответствующими коэффициентами корреляций для каждого из них. Коэффициент корреляции отражает «зашумлённость» линейной зависимости (верхняя строка), но не описывает наклон линейной зависимости (средняя строка), и совсем не подходит для описания сложных, нелинейных зависимостей (нижняя строка). Для распределения, показанного в центре рисунка, коэффициент корреляции не определен, так как дисперсия y равна нулю.
Применение возможно при наличии достаточного количества наблюдений для изучения. На практике считается, что число наблюдений должно быть не менее, чем в 5-6 раз превышать число факторов (также встречается рекомендация использовать пропорцию не менее, чем в 10 раз превышающую количество факторов). В случае, если число наблюдений превышает количество факторов в десятки раз, в действие вступает закон больших чисел, который обеспечивает взаимопогашение случайных колебаний.
Необходимо, чтобы совокупность значений всех факторных и результативного признаков подчинялась многомерному нормальному распределению. В случае, если объём совокупности недостаточен для проведения формального тестирования на нормальность распределения, то закон распределения определяется визуально на основе корреляционного поля. Если в расположении точек на этом поле наблюдается линейная тенденция, то можно предположить, что совокупность исходных данных подчиняется нормальному закону распределения.
Исходная совокупность значений должна быть качественно однородной
Сам по себе факт корреляционной зависимости не даёт основания утверждать, что одна из переменных предшествует или является причиной изменений, или то, что переменные вообще причинно связаны между собой, а не наблюдается действие третьего фактора.
6. Нелинейные регрессии, построение модели – различают 2 кдасса нелинейных моделей:
1 класс. Регрессии нелинейные относительно включенных в анализ объясняющих переменных.
А. Полиномы различных степеней:
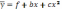
B.Равносторонняя гипербола:
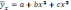

С. Полулогарифмическая ф-ия:
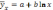
2 класс.
Уравнения нелинейной регрессии
полиномиальная
функция
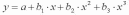
гиперболическая
функция
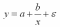
степенная
модель
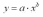
показательная
модель
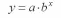
экспоненциальная
модель
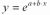
7. Метод наименьших квадратов - один из базовых методов регрессионного анализа для оценки неизвестных параметров регрессионных моделей по выборочным данным. Метод основан на минимизации суммы квадратов остатков регрессии. При МНК используется сумма квадратов отклонения фактических отклонений результативного признака от теоретических «линейных».
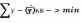
n a+b
a+b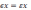
a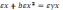
b=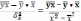
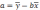
-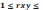 1
1
8. Модель парной регрессии
Парная
регрессия представляет собой регрессию
между двумя переменными –
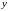 и
и
 ,
т. е. модель вида:
,
т. е. модель вида: 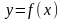 ,
где
,
где
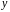 – зависимая переменная (результативный
признак);
– зависимая переменная (результативный
признак);
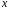 – независимая. Между переменными
и
нет строгой функциональной зависимости,
поэтому практически в каждом отдельном
случае величина
складывается из двух слагаемых:
– независимая. Между переменными
и
нет строгой функциональной зависимости,
поэтому практически в каждом отдельном
случае величина
складывается из двух слагаемых:
 ,
где
– фактическое значение результативного
признака;
,
где
– фактическое значение результативного
признака;
 – теоретическое значение результативного
признака, найденное исходя из уравнения
регрессии;
– теоретическое значение результативного
признака, найденное исходя из уравнения
регрессии;
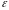 – случайная величина, характеризующая
отклонения реального значения
результативного признака от теоретического,
найденного по уравнению регрессии
(включает влияние не учтенных в модели
факторов, случайных ошибок и особенностей
измерения).
– случайная величина, характеризующая
отклонения реального значения
результативного признака от теоретического,
найденного по уравнению регрессии
(включает влияние не учтенных в модели
факторов, случайных ошибок и особенностей
измерения).
Вид мат. функции может быть осуществлен 3-я методами: графическим; аналитическим, экспериментальным.
Построение модели парной регрессии заключается в нахождении уравнения связи двух показателей У и Х, т.е. определяется как повлияет изменение одного показателя на другой. Число наблюдений должно в 7-8 раз превышать число рассчитываемых параметров при переменной . Минус модели - для прогноза необходимо, как правило, больше факторов.
9. Оценка параметров модели парной регрессии
Линейная
регрессия - простейшая модель парной
регрессии. Линейная регрессия сводится
к нахождению уравнения вида
 или
или
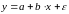 .
.
Построение
линейной регрессии сводится к оценке
ее параметров –
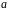 и
и
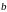 .
Классический подход к оцениванию
параметров линейной регрессии основан
на МНК или можно воспользоваться готовыми
формулами:
.
Классический подход к оцениванию
параметров линейной регрессии основан
на МНК или можно воспользоваться готовыми
формулами: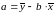 ,
,  .
.
Параметр
 - коэффициент регрессии - показывает
среднее изменение результата с изменением
фактора на одну единицу. Формально
- коэффициент регрессии - показывает
среднее изменение результата с изменением
фактора на одну единицу. Формально
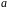 – значение
, при
– значение
, при
 .
Если признак-фактор
не может иметь нулевого значения, то
трактовка свободного члена
не имеет смысла.
.
Если признак-фактор
не может иметь нулевого значения, то
трактовка свободного члена
не имеет смысла.
Для
оценки тесноты связи между факторами
используется линейный коэффициент
корреляции
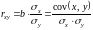 ,
который находиться в пределах
,
который находиться в пределах
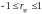 .Чем
ближе абсолютное значение
.Чем
ближе абсолютное значение
 к 1, тем сильнее линейная связь между
факторами.
к 1, тем сильнее линейная связь между
факторами.
Оценку
статистической значимости параметров
регрессии проводится с помощью
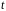 -статистики
Стьюдента и путем расчета доверительного
интервала каждого из показателей. Для
оценки отдельных параметров регрессии
определяют стандартная ошибки:
-статистики
Стьюдента и путем расчета доверительного
интервала каждого из показателей. Для
оценки отдельных параметров регрессии
определяют стандартная ошибки:
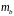 и
и
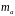 .
.
 ,
где
,
где
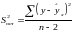 – остаточная дисперсия на одну степень
свободы.
– остаточная дисперсия на одну степень
свободы.
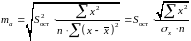 .
.
Для
оценки существенности коэффициента
регрессии его величина сравнивается с
его стандартной ошибкой, т.е. определяется
фактическое значение
-критерия
Стьюдента:
 ,
,
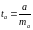 которое
затем сравнивается с табличным значением
при определенном уровне значимости
которое
затем сравнивается с табличным значением
при определенном уровне значимости
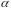 и числе степеней свободы
и числе степеней свободы
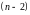 .
Затем находятся доверительные интервалы
для коэффициента регрессии -
.
Затем находятся доверительные интервалы
для коэффициента регрессии -
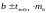 .
Поскольку знак коэффициента регрессии
указывает на рост результативного
признака
при увеличении признака-фактора
(
.
Поскольку знак коэффициента регрессии
указывает на рост результативного
признака
при увеличении признака-фактора
(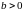 ),
уменьшение результативного признака
при увеличении признака-фактора (
),
уменьшение результативного признака
при увеличении признака-фактора (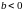 )
или его независимость от независимой
переменной (
)
или его независимость от независимой
переменной ( ),то
границы доверительного интервала для
коэффициента регрессии не должны
содержать противоречивых результатов,
например,
),то
границы доверительного интервала для
коэффициента регрессии не должны
содержать противоречивых результатов,
например,
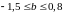 .
.