

Глава 15 Неполные структуры данных
До сих пор в рассмотренных программах использовались отношения между полными структурами данных. Как будет показано в настоящей главе, на основе применения неполных структур данных могут быть развиты мощные методы программирования.
В первом разделе обсуждаются разностные списки - структура данных, отличающаяся от списков для представления последовательности элементов. Они могут быть использованы для упрощения и повышения эффективности программ обработки списков. Разностные списки вводят в употребление идею накопления. Во втором разделе обсуждаются структуры данных, строящиеся как разности неполных структур, отличных от списков. В третьем разделе показано, как путем наращивания в процессе вычислений могут быть построены в виде неполных структур таблицы и справочники. В последнем разделе обсуждается применение разностных списков для представления очередей.
15.1. Разностные списки
Рассмотрим последовательность 1,2,3.Она может быть представлена как разность двух списков-списков [1,2,3,4,5]и [4,5], или списков [1,2,3,8]и[8] или списков[1,2,3]и [ ].Каждый из этих случаев представляет собой пример разности между двумя неполными списками [l,2,3 | Xs]и Xs.
Для обозначения разности двух списков будем использовать структуру As\Bs, которая названаразностным списком-В этой структуре As -голова разностного списка, a bs – его хвост-Для рассмотренного примера [l,2,3 | Xs] и Xsесть наиболее общий разностный список, представляющий последовательность 1,2,3(здесь [1,2,3 | Xs]-голова, а Xs-хвост разностного списка).
Логические выражения не вычисляются, а унифицируются, поэтому имя бинарного функтора, используемого для обозначения разностного списка, может быть произвольным, пока это не приводит к противоречиям. Оно может быть и вообще опущено, тогда голова и хвост разностного списка становятся двумя отдельными аргументами предиката.
Обычные и разностные списки тесно связаны. И те и другие используются для представления последовательностей элементов. Любой список Lможет быть тривиально представлен как разностный список L\[ ].Пустой список представляется посредством любого разностного списка, голова и хвост которого одинаковы, наиболее общей формой при этом будет разностный список As \ As,
Разностные списки успешно и широко используются в логическом программировании. Применение разностных, а не обычных списков ведет к более выразительным и эффективным программам. Возможность улучшения программ связана с эффективностью соединения разностных списков. Два неполных разностных списка могут быть соединены для образования третьего разностного списка за константное время. В противоположность этому соединение обычных списков с использованием стандартной программы appendпроисходит за линейное время, пропорциональное длине первого списка.
Рассмотрим списки на рис. 15,1.Разностный список Xs \ Zs-это результат при соединения разностного списка Ys \ Zsк разностному списку Х\Ys. Это может быть выражено одним фактом. Программа 15.1определяет предикат append_dl(As,Bs, Cs),который истинен, если разностный список Cs является результатом присоединения разностного списка Bsк разностному списку As.Суффикс _dlиспользуется для обозначения варианта предиката (соединения), в котором аргументами являются разностные списки.
Необходимым и достаточным условием возможности соединения двух разностных списков As\Bsи Xs\Ysс помощью программы 15.1является унифицируемость BsиXs.В этом случае соединенные разностные списки совместимы. Если хвост разностного списка не конкретизирован, то он совместим с любым разностным списком. Более того, в таком случае программа 15.1будет соединять списки за константное время. Например, вопросу append_dl([a,b,c|Xs]\Xs,[1,2]\[ ],Ys)? будет соответствовать результат (Xs =[1,2], Ys = [a,b,c,l,2]\[ ]).
Разностные списки в логическом программировании являются аналогом функции rplacdязыка Лисп, которая также используется для соединения списков за константное время (при этом не размещаются новые ячейки в области списочной памяти). Существует различие между разностными списками и указанной функцией:
разностные списки свободны от побочного эффекта и могут рассматриваться в терминах абстрактной модели вычислений, тогда как функция rplacd - деструктивная
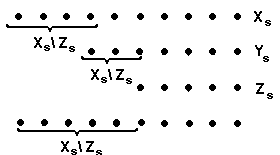
Рис. 15.1 Соединение разностных списков
операция, которая может быть описана лишь с использованием машинного представления S-выражений.
Хорошим примером программы, которую можно усовершенствовать путем использования разностных списков, является программа 9.1а, предназначенная для раскрытия списков. В ней использованы двойная рекурсия для раздельной линеаризации головы и хвоста списков и последующее соединение полученных списков друг
append_dl ( As. Bs. Сs)
разностный список Cs-результат присоединения разностного списка Bs кразностному списку As; AsиBs-совместные разностные списки
append_dl(Xs\Ys,Ys\Zs,Xs\Zs).
Программа 15.1.Соединение разностных списков.
flatten(Xs, Ys)-
Ys-раскрытый список, составленный из элементов, содержащихся в Xs.
flatten (Xs.Ys) flatten_dl(X, Ys\[ ]). flatten_dl([X!Xs].Ys\Zs)
flatten_dl(X,Ys\Ysl}.flatten_dl(Xs, Ys1\Zs). flatten_dl(X,[X | Xs]\Xs)
constant(X), X [ ]. flatten_dl([ ],Xs\Xs).
Программа 15 2.Программа раскрытия списка списков с использованием разностных списков.
с другом. Приспособим эту программу для вычисления отношения flatten _dl(Ls, Xs),гдеХs-разностный список, представляющий элементы, которые располагаются в списке списков Lsв правильном порядке. Ниже представлен результат прямой трансляции программы 9.1а в эквивалентную программу с разностными списками.
flatten_dl(X | Xs],Ys \ Zs)
flatten_dl(X, As \ Bs),flatten_dl(Xs,Cs\Ds),
append_dl(As\Bs,Cs\,Ds,Ys\Zs).
flatten_dl(X,[X| Xs]\Xs)
constant(X), X [ ]
flatten_dl([ ],Xs \ Xs).
Предложение с двойной рекурсией может быть упрощено посредством развертывания цели по отношению к ее определению в программе 15.1. Тем самым получим правило
flatten_dl([X | Xs].As\Ds) flatten_dl(X, As, Bs), flatten_dl(Xs, Bs\Ds).
Программа для отношения flatten_dlможет быть использована для реализации отношения flattenпосредством выражения связи между списком, подлежащим раскрытию, и разностным списком, вычисляемым программой f1atten_dl.Необходимая связь устанавливается следующим правилом:
flatten(Xs,Ys) flatten._.dl(Xs,Ys\[ ]).
Наконец, выполнив необходимые переименования переменных, получим программу 15.2.
При декларативном прочтении программа 15.2выглядит простои. Благодаря тому что раскрытие исходного списка приводит к разностному, а не обычному списку, явное обращение к предикату appendоказывается необязательным. Полученная программа более эффективна, так как размер ее дерева доказательства линейно, а не квадратично зависит от числа элементов в списке списков.
Операционное поведение программ с разностными списками, подобными программе 15.2,оказывается для понимания труднее. Кажется, что раскрытый список строится словно по волшебству,
Рассмотрим, как действует эта программа. На рис. 15.2 представлена трассировка выполнения программы, вызванного вопросом:flatten([[a],[b,[c]]],Xs)?
flatten([[a].[b,[c]]],Xs)
flatten_dl([[a].[b,[c]]],Xs\[ ]
flatten _dl([a],Xs\Xs1)
flatten _dl(a,Xs\Xsl) Xs=[a|Xs2]
constant(a)
a[ ]
flatten_dl([ ].Xs2\Xsl) Xs2 =Xs1
flatten_dl([[b,[c]]],Xsl\[ ])
flatten_dl([b,[c]],Xsl\Xs3)
flatten_d1(b,Xs1\Xs4) Xsl =[b|Xs4]
constant(b)
b[ ]
flatten_dl([[c]],Xs4\Xs3)
flatten_dl([c].Xs4\ Xs5)
flatten _dl(c,Xs4\ Xs6) Xs4 =[c | Xs6]
constant(c)
c[ ]
flatten_dl([ ],Xs6\Xs5) Xs6 =Xs5
flatten_dl([ ].Xs5\Xs3)` Xs5 =Xs3
flatten _dl([ ],Xs3\[ ]) Xs3 = [ ]
Выход: Xs = [a,b,c]
Рис, 15.2.Трассировка вычислений с использованием разностных списков.
Трассировка показывает, что результат Xsформируется по принципу «сверху вниз» (в терминологии разд. 7.5),Хвост разностного списка действует подобно указателю конца неполной структуры данных. Указатель устанавливается посредством унификации. Благодаря использованию таких «указателей» не требуется в отличие от программы 9.1а строить промежуточные структуры.
Противоречие между ясностью декларативного и трудностью процедурного понимания программы обусловлено мощью логической переменной. Можно описывать логические отношения неявно и предоставлять их интерпретацию Пролог - системе. Здесь соединение разностных списков выражается неявно, и его появление в программе кажется таинственным. Программы, написанные с использованием разностных списков, иногда структурно подобны программам, в которых используются накопители. В упражнении 9.1(1}предлагалось написать с использованием двойной рекурсии программу для отношения flatten,в которой вместо обращения к предикату appendиспользуются накопители. Решением будет следующая программа:
flatten(Xs, Ys) flatten(Xs,[ ],Ys).
flatten([X | Xs],Zs, Ys)
flatten(Xs,Zs,Ysl),flatten(X, Ysl, Ys). flatten (X, Xs,[X| Xs])
constant(X), X [ ]. flatten([ ],Xs, Xs).
Она весьма схожа с программой 15.2,за исключением двух отличий. Первое отличие - синтаксическое. Разностный список представляется двумя аргументами, однако они расположены в обратном порядке: хвост предшествует голове списка. Второе отличие заключается в порядке целей в рекурсивном предложении flatten. В результате раскрытый список строится по принципу «снизу вверх», т.е. начиная с хвоста.
Рассмотрим еще один пример сходства разностных списков и накопителей. Программа 15.3является результатом преобразования «наивной» версии предикатаreverse,а именно программы 3.16а. В новом варианте обычные списки заменены разностными списками, а операцияappendвообще не применяется
reverse(Xs, Ys)
список Ys-есть обращение списка Xs.
reverse (Xs,Ys) reverse _dl(Xs,Ys \ [ ]).
reverse_.dl([X | Xs].Ys \ Zs)
reverse_dl(Xs,Ys \ [X | Zs]). reverse_dl([ ],Xs \ Xs).
Программа 15.4Обращение с использованием разностных списков.
quicksort ( List, SortedList)
sortedlisi-упорядоченная перестановка элементов списка List.
quicksort(Xs,Ys) quicksort_dl(Xs,Ys \ l:]).
quicksort_dl([X | Xs],Ys \ Zs)
partition (Xs, X, Littles, Bigs),
quicksort_dl(Littles,Ys \ |:X | Ysl]),
quicksort_dl(Bigs,Ysl \ Zs).
quicksort_dl([ ],Xs \ Xs).
partition(Xs,X,Ls,Bs) См. программу 3.22.
Программа 15.4, Программа быстрой сортировки с использованием разностных
В каких же случаях разностные списки являются подходящими структурами данных для Пролог-программ? Обычно программы с явными обращениями к предикату appendмогут оказаться более эффективными, если в них использовать не простые, а разностные списки. Типичным примером является программа с двойной рекурсией, в которой результат получается путем присоединения результатов двух рекурсивных вызовов. Вообще программа, в которой части списка строятся независимо с целью последующего их объединения, является хорошим кандидатом на применение в ней разностных списков.
Программа 3.22 (quicksort)-логическая программа, реализующая алгоритм быстрой сортировки, является примером программы с двойной рекурсией, в которой конечный результат - упорядоченный список -получается соединением двух упорядоченных подсписков. С помощью применения разностных списков можно получить более эффективную программу сортировки. Как показано в программе15.4,все операции append,используемые при объединении частичных результатов, могут быть выполнены неявно.
В программу 15.4.аналогично тому как это было сделано в программе 15.2для отношения flatten,первым включено предложение с заголовком quicksortи цельюquicksort_dl.Рекурсивное предложение в этой программе определяет алгоритм быстрой сортировки, реализованный с использованием разностных списков, в котором конечный результат достигается неявным соединением частичных результатов. Последнее предложение quicksort_dlопределяет, что результат сортировки пустого списка есть пустой разностный список. Отметим, что при выполнении унификации цели quicksort_dl(Littles,Ys\[X\Ys1])обеспечивается размещение «разделяющего» элементаХпосле наименьшего элемента списка Ysи перед наибольшим элементом из Ys1.
Программа 15.4получена преобразованием программы 3.22 таким же образом, что и программа 15.2из программы 9,1а. Списки заменяются разностными списками, а цель append_dlраскрывается соответствующим образом. Предложениеquicksortс целью quicksort_dlвыражает отношение между списком, подлежащим со' тировке, и разностным списком, используемым в процессе вычислений.
Замечательпым примером преимущества использования разностных списков является решение упрощенной версии задачи Дейкстры о голландском флаге. Задача формулируется следующим образом: «Дан список элементов, окрашенных в красный, белый и голубой цвета. Упорядочить список так, чтобы все красные элементы расположились вначале, за красными должны следовать белые элементы за которыми в свою очередь должны быть расположены голубые элементы. При переупорядочении должен быть сохранен исходный относительный порядок элементов одного и того же цвета». Например, список [red(l),white(2),blue(3),red(4).white(5)] после переупорядочения должен принять вид [red(l),red(4),white(2),white(5),blue(3)].
В простом я разумном решении этой задачи, представленном программой 15 5 элементы исходного списка сначала распределяются по трем различным спискам' которые затем соединяются друг с другом в нужной последовательности. Базовое отношение в программе - dutch (Xs,Ys), где Xs-исходный список окрашенных элементов, a Ys-переупорядоченный список с требуемым расположением элементов по цветам.
dutch (Xs,RedWhitesBliies)
RedsWhitesBlues-список элементов списка Xs,упорядоченных по цветам: красные. белые, голубые.
dutch(Xs,RedsWhitesBlues)
distribute{Xs, Reds, Whites, Blues),
append(Whites, Blues, WhitesBlues). append(Reds,WhitesBlues,RedsWhitesBlues).
distribute (Xs, Reds, Wiites, Blues)
Reds. White.4и Blues-списки красных, белых и голубых элементов списка Xsсоответственно.
distribute([red(X) | Xs].[red(X) | Reds],Whites, Blues)
dislribute(Xs. Reds. Whites, Blues),
dislribute([white(X) | Xs],Reds,[white(X) | Whites], Blues)
distribute(Xs. Reds, Whites, Blues).
distribute([blue(X) | Xs].Reds,Whitcs,[biue(X)|Blues])
distribute(Xs, Reds, Whites, Biues).
distributed:([ ].[ ],[ ].[ ]).
append (Xs,Ys,Zs) См. программу 3.15.
Программа 15.5.Решение задачи о голландском флаге.
Ядро программы - процедура distribute,которая строит три одноцветных списка. Списки строятся по принципу «сверху вниз». Если использовать предикат distribute_dlsдля построения трех различных разностных списков вместо трех обычных, то два обращения к процедуре appendмогут быть исключены из программы. Соответствующая модификация представлена в виде программы 15.6.
При унификации цели distribute_dlsв предложении dutchпроисходит неявное соединение разностных списков. Полный список окончательно собирается из отдельных частей, когда удовлетворяется последнее предложение distribute_dlsв программе.
Решение задачи о голландском флаге является примером программы, в которой независимо строятся части решения, объединяемые в конце решения. Разностные списки использовались здесь более сложным образом, чем в предыдущих программах.
Использование явного конструктора для разностных списков, хотя и облегчает чтение программы, влечет за собой заметные дополнительные затраты времени и памяти. В связи с этим целесообразно использовать два отдельных аргумента. В тех
dutch ( Хs,RedsWhitesBlues)
RedsWhitesBluesсписок элементов списка Xs,упорядоченных по цвету: красные, белые, голубые.
dutch(Xs,RedsWilesBlues)
distribute_dls(Xs,RedsWhitesB1ues\WhitesBlues,WhitesBlues\Blues,Blues\[ ]).
distribute_dls (Xs, Red,Wiiles,Blues)
Reds. Whitesи Blues:разностные списки красных, белых и голубых элементов в спискеXsсоответственно.
distribute_dls([red (X) | Xs], [red (X)| Reds] \ Reds1, Whites, Blues)
distribute, dls(Xs, Reds\Reds1, Whites, Blues).
distribute_dls([while(X) | Xs], Reds, [white(X) | Whites] \Whitesl, Blues)
distribute_dls(Xs, Reds, Whites \ Whites1, Blues).
distribute_dls([blue(X) | Xs], Reds, Whiles, [blue(X)| Blues]\Blues!)
distribute_dls(Xs,Reds,Whites,Blues\Blues1).
distribute_dls([ ],Reds\Reds,Whiles\Whites,Blues\Blues).
Программа 15.6. Решение задачи о голландском флаге с использованием разностных списков.
случаях, когда требуется повысить эффективность программы, соответствующие простые преобразования могут быть выполнены вручную или автоматически.
Упражнения к разд. 15.1
1.Перепишите программу 15.2так, чтобы порядок элементов в окончательном списке был обратным по отношению к порядку их расположения в списке списков.
2.Перепишите программы 3.27для отношений pre_order( Tree,List), in_order (Tree,List)иpost_order(Tree, List),собирающие элементы при обходе двоичного дерева, используя разностные списки и исключая явное применение предиката append.
3.Перепишите программу 12.3для решения задачи о ханойских башнях, используя для формирования списка перемещений не обычный, а разностный список.
15.2. Разностные структуры
Идея, лежащая в основе построения и применения разностных списков, состоит в использовании для представления частичных результатов вычислений разности неполных структур данных. Такой подход применим не только к спискам, но и к другим рекурсивным структурам данных. В этом разделе рассматривается один специфический пример, связанный с алгебраическими суммами.
Рассмотрим задачу нормализации арифметических выражений, например сумм. На рис- 15.3представлены две суммы: (a+b)+(c+d)и (а+(b+(с+d))). Согласно стандартному синтаксису Пролога, скобки в термеа + b +срасставляются следующим образом:((а+ b)+с). Опишем процедуру преобразования суммы в нормализованную сумму, в которой сгруппированы правые скобки. Например, выражение, представленное на рис, 15.3слева, должно быть преобразовано в нормализованное выражение, показанное справа. Такая процедура полезна для упрощения алгебраических выражений, облегчения написания программ проверки эквивалентности выражений.
Введем понятие разностной суммыкак некоторого варианта разностного списка. Разностная сумма представлена структурой видаЕ1 + + Е2,гдеЕ1и E2 - неполные нормализованные суммы. Предполагается, что + +является обозначением бинар-
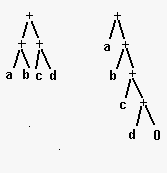
Рис 15.3 Ненормализованная и нормализованная суммы
ного инфиксного оператора. Условимся также использовать 0для обозначения пустой суммы.
Программа 15.7является программой для нормализации сумм. Реляционной схемой программы является отношение normalize (Exp,NormExp},где NormExp-выражение, эквивалентное выражениюЕхр,в котором сгруппированы правые скобки при сохранении порядка констант, определенного в выраженииЕхр.
normalize (Sum, NormalizedSiim)
NormalizedSum - результат нормализации выражения Sum.
normalize(Exp,Norm) normalize._ds(Exp,Norm+ +0).
normalize_ds(A +В, Norm + + Space)
normalize_ds(A, Norm+ +NormB),
normalize_ds(B, NormB + + Space).
normalize_ds(A,(A + Space) + +Space)
constant (A).
Программа 15.7.Нормализация выражений типа «сумма».
По структуре эта программа подобна программе 15.2для раскрытия списков с использованием разностных списков. Существует начальный этап установки разностной структуры, на котором обычно выполняется обращение к предикату с тем же именем, но имеющим другую арность или другой вид аргументов. Последнее предложение normaiize_dsв программе распространяет хвост неполной структуры данных, в то время как цели в теле рекурсивного предложения передают хвост первой неполной структуры во вторую структуру, где он занимает место головы структуры данных.
Программа строит нормализованную сумму по принципу сверху вниз. По аналогии с программами, использующими разностные списки, и эта программа может быть легко модифицирована, с тем чтобы структура строилась снизу вверх (см. упражнение в конце раздела).
Эти программы имеют простой декларативный смысл. Операционное их толкование состоит в представлении процесса построения структуры путем ее наращивания, когда явно указывается «место» для последующих результатов. Здесь видна полная аналогия с разностными списками.
Упражнения к разд. 15.2
1.Определите предикат normalized_sum(Expression),который истинен, если выражениеExpression-нормализованная сумма.
2.Перепишите программу 15.7так, чтобы
а) нормализованная сумма строилась по принципу «снизу вверх»,
б) получился обратный порядок элементов.
3.Напишите программу для нормализации произведения, используя разностное произведение определенное по аналогии с разностной суммой.