

6.1.2. Общая схема кластеризации.
Этапы:
Выделение характеристик объектов;
Выбор метрики;
Выбор метода кластеризации и разбиение объектов на группы;
Представление результатов.
Выделение характеристик:
Выбор свойств, характеризующих объекты (количественные и качественные характеристики);
Нормализация характеристик (приведение к единой шкале);
Представление объектов в виде характеристических векторов.
Выбор метрики
Метрика выбирается в зависимости от пространства, где расположены объекты. Если все координаты объекта непрерывны и вещественны, то используется метрика Евклида:

Представление результатов
Обычно используется один из следующих способов представления кластеров:
Центроидами;
Набором характерных точек;
О
 граничениями
кластеров.
граничениями
кластеров.
6.1.3. Методы кластеризации.
Алгоритм k-средних (k-Means)
Выбрать k точек, являющихся начальными «центрами масс» кластеров (любые k из n объектов или вообще k случайных точек);
Отнести каждый объект к кластеру с ближайшим «центром масс»;
Пересчитать «центры масс» кластеров согласно текущему членству;
Если критерий остановки алгоритма не удовлетворен, вернуться к шагу 2.
Критерии остановки:
Отсутствие перехода объектов из кластера в кластер на шаге 2;
Минимальное изменение среднеквадратической ошибки.
Достоинства: алгоритм быстро работает и прост в реализации.
Недостатки:
алгоритм создает только кластеры, похожие на гиперсферы;
алгоритм чувствителен к начальному выбору «центров масс».
Иерархические алгоритмы (иерархическое группирование)
Наибольшее распространение получили агломеративные процедуры, основанные на последовательном объединении кластеров (разбиение «снизу-вверх»).
На первом шаге все объекты считаются отдельными кластерами. На каждом последующем шаге два ближайших кластера объединяются в один. Каждое объединение уменьшает число кластеров на один так, что в конце концов все объекты объединяются в один кластер. В результате образуется дендрограмма, отображающая результаты группирования объектов на всех шагах алгоритма.
Вид дендрограммы зависит от выбранного способа измерения расстояний между кластерами.
Достоинства: возможность проследить процесс выделения группировок и иллюстрация соподчиненности кластеров.
Н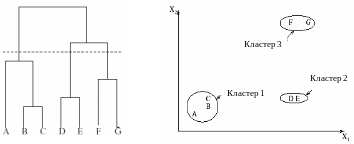 едостаток:
квадратичная трудоемкость.
едостаток:
квадратичная трудоемкость.
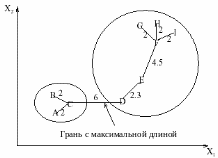
Минимальное покрывающее дерево
Позволяет производить иерархическую кластеризацию «сверху-вниз».
Объекты представляются вершинами связного неориентированного графа с взвешенными ребрами, где вес ребер – это их длина (расстояние между объектами). Нужно удалить ребра как можно большей суммарной длины, оставив граф связным. При этом получается дерево с минимальной суммарной длиной ребер.
Алгоритм Прима:
Выбирается произвольная вершина. Она образует начальное дерево.
Измеряется расстояние от нее до всех других вершин.
До тех пор пока в дерево не добавлены все вершины:
Найти ближайшую вершину, с минимальным расстоянием до дерева;
Д
 обавить
ее к дереву;
обавить
ее к дереву;Пересчитать расстояния от вершин до дерева: если расстояние до какой-либо вершины из новой вершины меньше текущего расстояния от дерева, то старое расстояние от дерева заменить новым.
Разбить объекты на заданное число кластеров в соответствии с максимальными длинами ветвей дерева.
Метод ближайшего соседа
Пока существуют объекты вне кластеров:
Для каждого такого объекта выбрать ближайшего соседа, кластер которого определен, и если расстояние до этого соседа меньше порога – отнести его в тот же кластер, иначе можно создать новый кластер;
Увеличить порог при необходимости.
Достоинство: простота.
Недостаток: низкая эффективность.
Нечеткая кластеризация
Непересекающаяся (четкая) кластеризация относит объект только к одному кластеру.
Нечеткая кластеризация считает для каждого объекта xi степень его принадлежности uik к каждому из k кластеров.
Схема нечеткой кластеризации:
Выбрать начальное нечеткое разбиение N объектов на K кластеров путем выбора матрицы принадлежности U размера N x K (обычно uik [0;1]);
Используя матрицу U, найти значение критерия нечеткой ошибки. Например,
![]()
![]()
Перегруппировать объекты с целью уменьшения ошибки.
Повторять шаг 2, пока матрица U меняется.
Достоинства:
Отсутствие необходимости в априорных предположениях относительно структуры данных (вид и параметры распределения вероятности по кластерам, центров плотности);
Отсутствие ограничений на геометрию кластеров;
Время выполнения алгоритма мало зависит от числа компонент входных векторов.
Недостаток: большое время выполнения алгоритма, характеризуемое порядком от числа элементов.