

Метод Хаффмана.
Сжатие Хаффмана - статистический метод сжатия, который уменьшает среднюю длину кодового слова для символов алфавита. Код Хаффмана является примером кода, оптимального в случае, когда все вероятности появления символов в сообщении - целые отри- цательные степени двойки. Код Хаффмана может быть построен по следующему алгоритму:
Выписываем в ряд все символы алфавита в порядке возрастания или убывания вероятности их появления в тексте;
Последовательно объединяем два символа с наименьшими вероятностями появления в новый составной символ, вероятность появления которого полагается равной сумме вероятностей составляющих его символов. В конце концов, мы построим дерево, каждый узел которого имеет суммарную вероятность всех узлов, находящихся ниже него;
Прослеживаем путь к каждому листу дерева помечая направление к каждому узлу (например, направо - 1, налево - 0).
Поясним создание дерева с использованием иллюстраций:
A B C D E
10 5 8 13 10
B C A E D
5 8 10 10 13
A E BC D
10 10 13 13
BC D AE
13 13 20
AE BCD
20 26
AEBCD
46
Таким образом, построено дерево
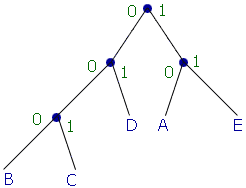
Теперь, если в тексте встречается, например, символ "d", то вместо того, чтобы выделять этому символу байт, после сжатия символ займет всего 2 бита (01).
При использовании адаптивного кодирования Хаффмена усложнение алгоритма состоит в необходимости постоянной корректировки дерева и кодов символов основного алфавита в соответствии с изменяющейся статистикой входного потока.
Методы Хаффмена дают достаточно высокую скорость и умеренно хорошее качество сжатия. Эти алгоритмы давно известны и широко применяется как в программных (всевозможные компрессоры, архиваторы и программы резервного копирования файлов и дисков), так и в аппаратных (системы сжатия "прошитые" в модемы и факсы, сканеры) реализациях.
Эвристические (словарные) алгоритмы сжатия (типу LZ, LZW), как правило, ищут в файле строки, что повторяются и строят словарь фраз, которые уже встречались. Обычно такие алгоритмы имеют целый ряд специфических параметров (размер буфера, максимальная длина фразы и т.п.), подбор которых зависит от опыта автора работы, и эти параметры добираются таким образом, чтобы достичь оптимального соотношения времени работы алгоритма, коэффициента сжатия и перечня файлов, которые хорошо сжимаются.
Алгоритмы группы kwe
В основе алгоритма сжатия по ключевым словам положен принцип кодирования лексических единиц группами байт фиксированной длины. Примером лексической единицы может быть обычное слово. На практике, на роль лексических единиц выбираются повторяющиеся последовательности символов, которые кодируются цепочкой символов (кодом) меньшей длины. Результат кодирования помещается в таблице, образовывая так называемый словарь.
Существует довольно много реализаций этого алгоритма, среди которых наиболее распространенными являются алгоритм Лемпеля-Зіва (алгоритм LZ) и его модификация алгоритм Лемпеля-Зіва-Велча (алгоритм LZW). Словарем в данном алгоритме является потенциально бесконечный список фраз. Алгоритм начинает работу с почти пустым словарем, который содержит только одну закодированную строку, так называемая NULL-строка. При считывании очередного символа входной последовательности данных, он прибавляется к текущей строке. Процесс продолжается до тех пор, пока текущая строка соответствует какой-нибудь фразе из словаря. Но рано или поздно текущая строка перестает соответствовать какой-нибудь фразе словаря. В момент, когда текущая строка представляет собой последнее совпадение со словарем плюс только что прочитанный символ сообщения, кодер выдает код, который состоит из индекса совпадения и следующего за ним символа, который нарушил совпадение строк. Новая фраза, состоящая из индекса совпадения и следующего за ним символа, прибавляется в словарь. В следующий раз, если эта фраза появится в сообщении, она может быть использована для построения более длинной фразы, что повышает меру сжатия информации.
Алгоритм LZW построен вокруг таблицы фраз (словаря), которая заменяет строки символов сжимаемого сообщения в коды фиксированной длины. Таблица имеет так называемое свойством опережения, то есть для каждой фразы словаря, состоящей из некоторой фразы w и символа К, фраза w тоже заносится в словарь. Если все части словаря полностью заполнены, кодирование перестает быть адаптивным (кодирование происходит исходя из уже существующих в словаре фраз).
Алгоритмы сжатия этой группы наиболее эффективны для текстовых данных больших объемов и малоэффективны для файлов маленьких размеров (за счет необходимости сохранение словаря).
Метод LZW-сжатия данных
Собственно исходный Lempel/Ziv подход к сжатию данных был впервые обнародован в 1977г., а усовершенствованный (Terry Welch) вариант был опубликован в 1984г. Алгоритм на удивление прост. LZW-сжатие заменяет строки символов некоторыми кодами. Это делается без какого-либо анализа входного текста. Вместо этого при добавлении каждой новой строки символов просматривается таблица строк. Сжатие происходит, когда код заменяет строку символов. Коды, генерируемые LZW-алгоритмом, могут быть любой длины, но они должны содержать больше бит, чем единичный символ. Первые 256 кодов (когда используются 8-битные символы) по умолчанию соответствуют стандартному набору символов. Остальные коды соответствуют обрабатываемым алгоритмом строкам.
Простая программа, приведенная ниже, работает с 12-битными кодами. Значения кодов 0 - 255 соответствуют отдельным байтам, а коды 256 - 4095 соответствуют подстрокам.
Сжатие.
Алгоритм LZW-сжатия в простейшей форме приведен ниже. Каждый раз, когда генерируется новый код, новая строка добавляется в таблицу строк. LZW постоянно проверяет, является ли строка уже известной, и , если так, выводит существующий код без генерации нового.
Процедура LZW-сжатия: СТРОКА = очередной символ из входного потока WHILE входной поток не пуст DO СИМВОЛ = очередной символ из входного потока IF СТРОКА+СИМВОЛ в таблице строк THEN СТРОКА = СТРОКА+СИМВОЛ ELSE вывести в выходной поток код для СТРОКА добавить в таблицу строк СТРОКА+СИМВОЛ СТРОКА = СИМВОЛ END of IF END of WHILE вывести в выходной поток код для СТРОКА
Простая строка, использованная для демонстрации алгоритма, приведена на рис.2. Входная строка является кратким списком английских слов, разделенных символом "/". Как вы можете заметить, анализируя алгоритм, его работа начинается с того, что на первом шаге цикла он выполняет проверку на наличие строки "/W" в таблице. Когда он не находит эту строку, то генерирует код для "/" и добавляет в таблицу строку "/W". Т.к. 256 символов уже определены для кодов 0 - 255, то первой определенной строке может быть поставлен в соответствие код 256. После этого система читает следующую букву ("E"), добавляет вторую подстроку ("WE") в таблицу и выводит код для буквы "W".
Этот процесс повторяется до тех пор, пока вторая подстрока, состоящая из прочитанных символов "/" и "W", не сопоставится со строковым номером 256. В этом случае система выводит код 256 и добавляет трехсимвольную подстроку в таблицу. Этот процесс продолжается до тех пор, пока не исчерпается входной поток и все коды не будут выведены.
Входная строка : /WED/WE/WEE/WEB/WET
Вход(символы) |
Выход(коды) |
Новые коды и соответствующие строки |
/W |
/ |
256 = /W |
E |
W |
257 = WE |
D |
E |
258 = ED |
/ |
D |
259 = D/ |
WE |
256 |
260 = /WE |
/ |
E |
261 = E/ |
WEE |
260 |
262 = /WEE |
/W |
261 |
263 = E/W |
EB |
257 |
264 = WEB |
/ |
B |
265 = B/ |
WET |
260 |
266 = /WET |
<EOF> |
T |
|
Рис. 2 Процесс сжатия
Выходной поток для заданной строки показан на рис. 2, также как и полученная в результате таблица строк. Как вы можете заметить, эта таблица быстро заполняется, т.к. новая строка добавляется в таблицу каждый раз, когда генерируется код. В этом явно вырожденном примере было выведено пять закодированных подстрок и семь символов. Если использовать 9-битные коды для вывода, то 19-символьная входная строка будет преобразована в 13.5-символьная выходную строку. Конечно, этот пример был выбран только для демонстрации. В действительности сжатие обычно не начинается до тех пор, пока не будет построена достаточно большая таблица, обычно после прочтения порядка 100 входных байт.