

7.7. Еще о стековой архитектуре
Доступ к переменным на промежуточных уровнях
Мы обсудили, как можно эффективно обращаться к локальным переменным по фиксированным смещениям от указателя дна, указывающего на запись активации. К глобальным данным, т. е. данным, объявленным в главной программе, также можно обращаться эффективно. Это легко увидеть, если рассматривать глобальные данные как локальные для главной процедуры. Память для глобальных данных распределяется при входе в главную процедуру, т. е. в начале программы. Так как их размещение известно на этапе компиляции, точнее, при компоновке, то действительный адрес каждого элемента известен или непосредственно, или как смещение от фиксированной позиции. На практике глобальные данные обычно распределяются независимо (см. раздел 8.3), но в любом случае адреса фиксированы.
Труднее обратиться к переменным на промежуточных уровнях вложения.
procedure Main is
G: Integer,
procedure Proc_1 is
L1: Integer;
Ada |
procedure Proc_2 is
L2: Integer;
begin L2 := L1 + G; end Proc_2;
procedure Proc_3 is
L3: Integer;
begin L3 := L1 + G; Proc_2; end Proc_3;
begin -- Proc_1
Proc_3;
end Proc_1;
begin — Main
Proc_1;
end Main;
Мы видели, что доступ к локальной переменной L3 и глобальной переменной G является простым и эффективным, но как можно обращаться к L1 в Ргос_3? Ответ прост: значение указателя дна сохраняется при входе в процедуру и используется как указатель на запись активации объемлющей процедуры Ргос_1. Указатель дна хранится в известном месте и может быть немедленно загружен, поэтому дополнительные затраты потребуются только на косвенную адресацию.
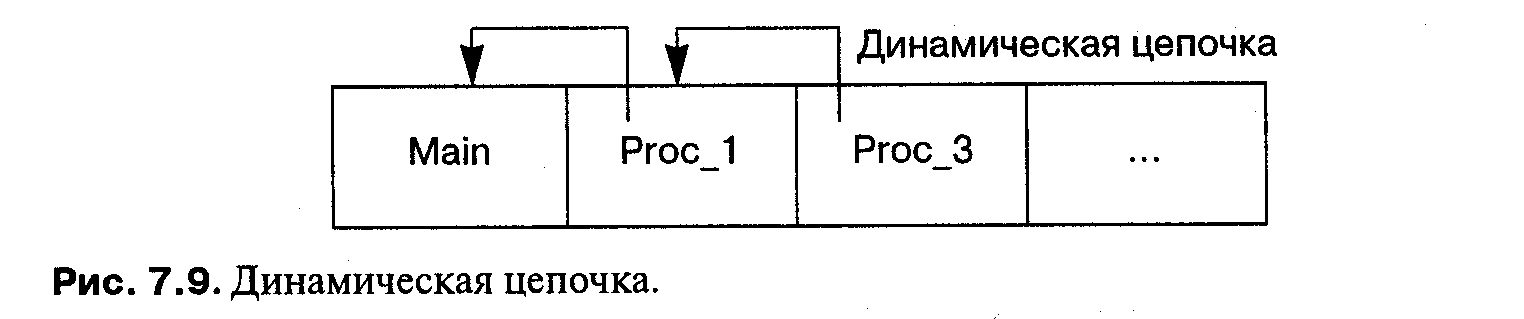
При более глубоком вложении каждая запись активации содержит указатель на предыдущую запись активации. Эти указатели на записи активации образуют динамическую цепочку (см. рис. 7.9). Чтобы обратиться к вышележащей переменной (вложенной менее глубоко), необходимо «подняться» по динамической цепочке. Связанные с этим затраты снижают эффективность работы с переменными промежуточных уровней при большой глубине вложенности. Обращение непосредственно к предыдущему уровню требует только одной косвенной адресации, и эпизодическое глубокое обращение тоже не должно вызывать никаких проблем, но в циклы не следует включать операторы, которые далеко возвращаются по цепочке.
Вызов вышележащих процедур
Доступ к промежуточным переменным фактически еще сложнее, потому что процедуре разрешено вызывать другие процедуры, которые имеют такой же или более низкий уровень вложения. В приведенном примере Ргос_3 вызывает Ргос_2. В записи активации для Ргос_2 хранится указатель дна для процедуры Ргос_3 так, что его можно восстановить, но переменные Ргос_3 недоступны в Ргос_2 в соответствии с правилами области действия.
Так или иначе, программа должна быть в состоянии идентифицировать статическую цепочку, т.е. цепочку записей активации, которая определяет статический контекст процедур согласно правилам области действия, в противоположность динамической цепочке вызовов процедур во время выполнения. В качестве крайнего случая рассмотрим рекурсивную процедуру: в динамической цепочке могут быть десятки записей активации (по одной для каждого рекурсивного вызова), но статическая цепочка будет состоять только из текущей записи и записи для главной процедуры.
Одно из решений состоит в том, чтобы хранить в записи активации статический уровень вложенности каждой процедуры, потому что компилятор знает, какой уровень необходим для каждого доступа. Если главная программа в примере имеет нулевой уровень, то обе процедуры Ргос_2 и Ргос_3 находятся на уровне 2. При продвижении вверх по динамической цепочке уровень вложенности должен уменьшаться на единицу, чтобы его можно было рассматривать как часть статической цепочки; таким образом, запись для Ргос_3 пропускается, и следующая запись, уже запись для Ргос_1 на уровне 1, используется, чтобы получить индекс дна.
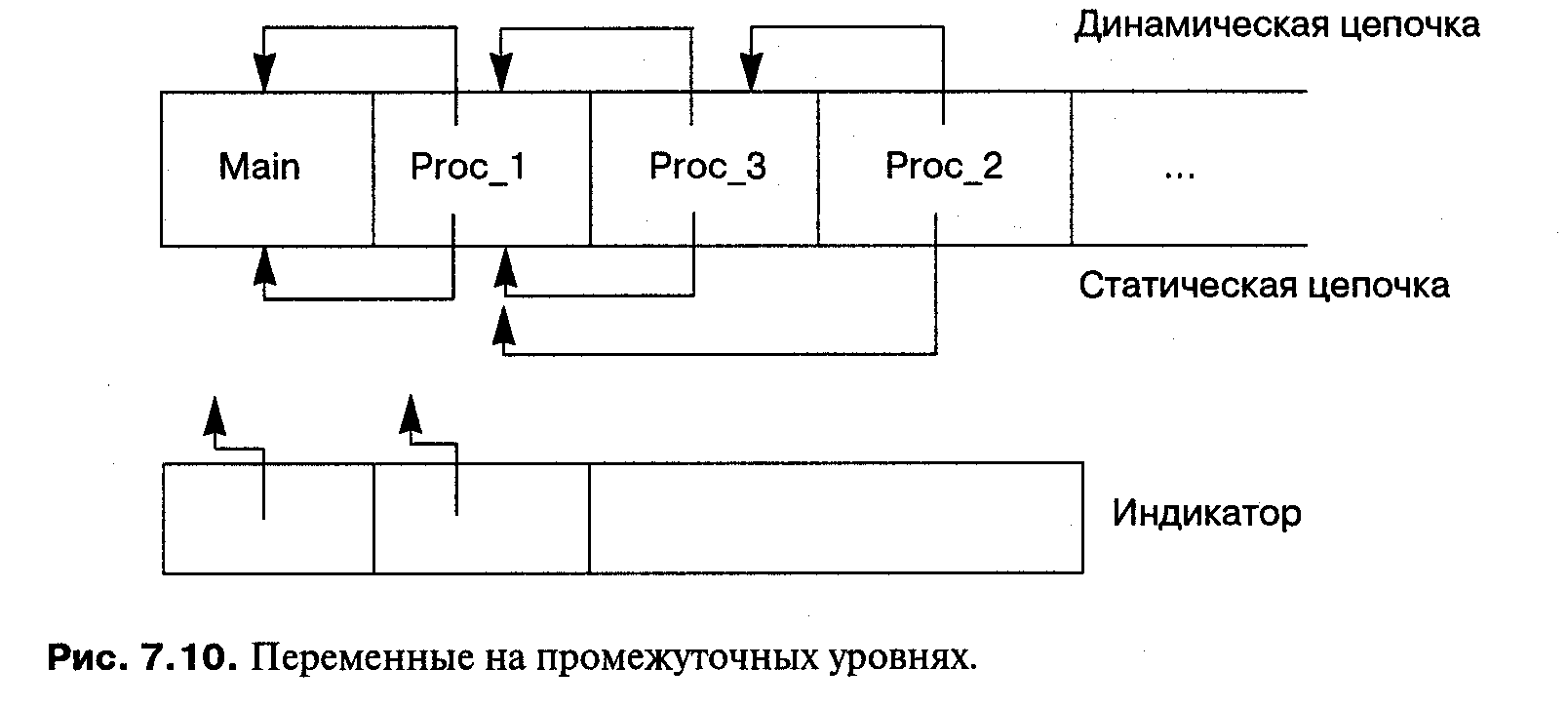
Другое решение состоит в том, чтобы явно включить статическую цепочку в стек. На рисунке 7.10 показана статическая цепочка сразу после вызова Ргос_2 из Ргос_3 . Перед вызовом статическая цепочка точно такая же, как динамическая, а после вызова она стала короче динамической и содержит только главную процедуру и Ргос_1.
Преимущество явной статической цепочки в том, что она часто короче, чем динамическая (вспомните здесь о предельном случае рекурсивной процедуры). Однако мы все еще должны осуществлять поиск при каждом обращении к промежуточной переменной. Более эффективное решение состоит в том, чтобы использовать индикатор, который содержит текущую статическую цепочку в виде массива, индексируемого по уровню вложенности (см. рис. 7.10). В этом случае для обращения к переменной промежуточного уровня, чтобы получить указатель на правильную запись активации, в качестве индекса используется уровень вложенности, затем из записи извлекается указатель дна, и, наконец, прибавляется смещение, чтобы получить адрес переменной. Недостаток индикатора в том, что необходимы дополнительные затраты на его обновление при входе и выходе из процедуры.
Возможная неэффективность доступа к промежуточным переменным не должна служить препятствием к применению вложенных процедур, но программистам следует учитывать такие факторы, как глубина вложенности, и правильно находить компромисс между использованием параметров и прямым доступом к переменным.