

5.8. Спецификация представления
В этой книге неоднократно подчеркивается значение интерпретации программы как абстрактной модели реального мира. Однако для таких программ, как операционные системы, коммуникационные пакеты и встроенное программное обеспечение, необходимо манипулировать данными на физическом уровне их представления в памяти.
Вычисления над битами
В языке С есть булевы операции, которые выполняются побитно над значениями целочисленных типов: «&» (and), «|» (or), «л» (xor), «~» (not).
Булевы операции в Ada — and, or, xor, not — также могут применяться к булевым массивам:
type Bool_Array is array(0..31) of Boolean;
Ada |
B2: Bool_Array := (0..15 => False, 16..31 => True);
B1 :=B1 orB2;
Однако само объявление булевых массивов не гарантирует, что они представляются как битовые строки; фактически, булево значение обычно представляется как целое число. Добавление управляющей команды
Ada |
pragma Pack(Bool_Array);
требует, чтобы компилятор упаковывал значения массива как можно плотнее. Поскольку для булева значения необходим только один бит, 32 элемента массива могут храниться в 32-разрядном слове. Хотя таким способом и обеспечиваются требуемые функциональные возможности, однако гибкости, свойственной языку С, достичь не удастся, в частности, из-за невозможности использовать в булевых вычислениях такие восьмеричные или шестнад-цатеричные константы, как OxfOOf OffO. Язык Ada обеспечивает запись для таких констант, но они являются целочисленными значениями, а не булевыми массивами, и поэтому не могут использоваться в поразрядных вычислениях.
Эти проблемы решены в языке Ada 95: в нем для поразрядных вычислений могут использоваться модульные типы (см. раздел 4.1):
Ada |
UI,U2: Unsigned_Byte;
U1 :=U1 andU2;
Поля внутри слов
Аппаратные регистры обычно состоят из нескольких полей. Традиционно доступ к таким полям осуществляется с помощью сдвига и маскирования; оператор
field = (i » 4) & 0x7;
извлекает трехбитовое поле, находящееся в четырех битах от правого края слова i. Такой стиль программирования опасен, потому что очень просто сделать ошибку в числе сдвигов и в маске. Кроме того, при малейшем изменении размещения полей может потребоваться значительное изменение программы.
- Изящное решение этой проблемы впервые было сделано в языке Pascal: использовать обычные записи, но упаковывать несколько полей в одно слово. Обычный доступ к полю Rec.Field автоматически переводится компилятором в правильные сдвиг и маску.
В языке Pascal размещение полей в слове явно не задается; в других языках такое размещение можно описать явно. Язык С допускает спецификаторы разрядов в поле структуры (при условии, что поля имеют целочисленный тип):
C |
int : 3; /* Заполнитель */
int f1 :1;
int f2 :2;
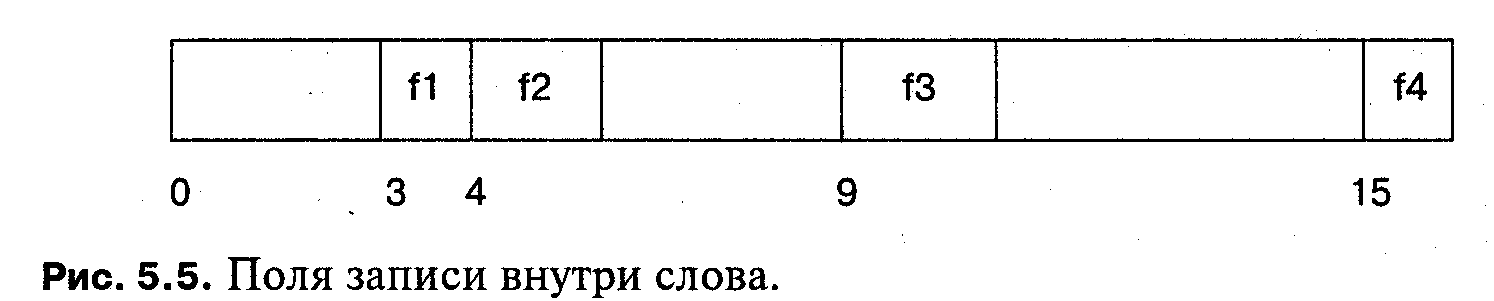
C |
int f3 :2;
int : 4; /* Заполнитель */
int f4 :1;
}reg;
и это позволяет программисту использовать обычную форму предложений присваивания (хотя поля и являются частью слова), а компилятору реализовать эти присваивания с помощью сдвигов и масок:
reg r;
C |
i = r.f2;
r.f3 = i;
Язык Ada неуклонно следует принципу: объявления типа должны быть абстрактными. В связи с этим спецификации представления (representation specifications) используют свою нотацию и пишутся отдельно от объявления типа. К следующим ниже объявлениям типа:
type Heat is (Off, Low, Medium, High);
type Reg is
Ada |
F1: Boolean;
F2: Heat;
F3: Heat;
F4: Boolean;
end record;
может быть добавлена такая спецификация:
Ada |
record
F1 at 0 range 3..3;
F2 at Orange 4..5;
F3at 1 range 1..2;
F4at 1 range 7..7;
end record;
Конструкция at определяет байт внутри записи, a range определяет отводимый полю диапазон разрядов, причем мы знаем, что достаточно одного бита для значения Boolean и двух битов для значения Heat. Обратите внимание, что заполнители не нужны, потому что определены точные позиции полей.
Если разрядные спецификаторы в языке С и спецификаторы представления в Ada правильно запрограммированы, то обеспечена безошибочность всех последующих обращений.
Порядок байтов в числах
Как правило, адреса памяти растут начиная с нуля. К сожалению, архитектуры компьютеров отличаются способом хранения в памяти многобайтовых значений. Предположим, что можно независимо адресовать каждый байт и что каждое слово состоит из четырех байтов. В каком виде будет храниться целое число 0x04030201: начиная со старшего конца (big endian), т. е. так, что старший байт имеет меньший адрес, или начиная с младшего конца (little endian), т. е. так, что младший байт имеет меньший адрес? На рис. 5.6 показано размещение байтов для двух вариантов.

В компиляторах такие архитектурные особенности компьютеров, естественно, учтены и полностью прозрачны (невидимы) для программиста, если он описывает свои данные на должном уровне абстракции.
Однако при использовании спецификаций представления разница между двумя соглашениями может сделать программу непереносимой. В языке Ada 95 порядок битов слова может быть задан программистом, так что для переноса программы, использующей спецификации представления, достаточно заменить всего лишь спецификации.
Производные типы и спецификации представления в языке Ada
Производный тип в языке Ada (раздел 4.6) определен как новый тип, чьи значения и
операции такие же, как у родительского типа. Производный тип может иметь представление, отличающееся от родительского типа. Например, если определен обычный тип Unpacked_Register:
Ada |
record
…
end record;
можно получить новый тип и задать спецификацию представления, связанную с производным типом:
Ada |
for Packed_Register use
record
…
end record;
Преобразование типов (которое допустимо между любыми типами, полученными друг из друга) вызывает изменение представления, а именно упаковку и распаковку полей слов в обычные переменные:
U: Unpacked_Register;
Р: Packed_Register;
-
Ada
U := Unpacked_Register(P);
Р := Packed_Register(U);
Это средство может сделать программы более надежными, потому что, коль скоро написаны правильные спецификации представления, остальная часть программы становится полностью абстрактной.