

5.3.3 Модификация алгоритма isodata (без участия человека для выбора некоторых параметров)
Как видно раздела 5.3.2, в использовании алгоритма ISODATA некоторые параметры процесса, типа числа кластеров, минимального приемлемого среднеквадратичного отклонения, и минимального приемлемого расстояния между кластерами, должны быть определены. Знание этих параметров предполагает, что предыдущее обучение было выполнено на данных. Кроме того, эффективность алгоритма сильно зависит от различных параметров, предварительно установленных пользователем. "Правильная" установка обычно может быть определена только методом проб и ошибок.
Дэвис и Болдин предложили параметр кластеризации, который должен быть минимизирован, чтобы получить естественное разделение наборов данных. Параметр, который они использовали есть
![]() (5.39)
(5.39)
Где
Dii
и Djj
определены как дисперсия для кластеров
i
и j,
соответственно; и Dij
- расстояние между кластерами i
и j.
Из определений очевидно, что если
![]() то домен кластера
то домен кластера
![]() (5.40,
5.41)
(5.40,
5.41)
Некоторые ограничения на R, чтобы сделать его значимым:
 (5.42)
(5.42)
![]()
Первое и второе выражения указывают, что функция подобия R неотрицательна и обладает свойством симметрии. Третье выражение подразумевает, что подобие между кластерами нулевое, тогда и только тогда, когда их дисперсия равна нулю.
Четвертое и пятое выражения подразумевают, что, если расстояние между кластерами увеличивается, в то время как их дисперсии остаются постоянными, подобие кластеров уменьшается. Напротив если внутреннее расстояние есть константа, подобие кластеров увеличивается при увеличении дисперсии.
Для начала число кластеров может быть выбрано большим; даже такого размера, как число образцов в данном наборе данных. Следуя алгоритму ISODATA как обсуждалось в разделе 5.3.2, мы можем получить номер и расположение кластеров также как выборок модели, распределенных каждому кластеру. Dii и Djj могут быть вычислены согласно определению
![]() (5.43)
(5.43)
и
![]() (5.44)
(5.44)
где zki – k-тый компонент кластера i. Rij и R, среднее число критериев подобия каждого кластера с наиболее подобным кластером, может тогда быть вычислено согласно
![]() (5.45)
(5.45)
и
![]() (5.46)
(5.46)
где Ri есть максимум Rij, i != j и Nc есть число кластеров.
Различные значения R могут быть получены для различных чисел кластеров в ходе кластеризации. Число кластеров, соответствующих самым маленьким значениям R, кажется наиболее подходящим.
На рисунках 5.6a и c показаны набор данных 225 точек для испытания и проверки эффективности R для самого маленького из 20 значений Nc. R минимален когда Nc = 8 и приблизительно на 5 % большее чем минимум когда Nc = 9.
На рисунке 5.6b показано, что точки данных сгруппированы в семь кластеров как показано выделением, и в восемь как обозначено дополнительной пунктирной линией.
5.3.4 Техника динамического поиска оптимального кластера (dynoc)
DYNOC - алгоритм, предложенный Тоу, чтобы обойти недостатки, упомянутые ранее. Основная цель этого алгоритма в том, чтобы ввести индекс эффективности и определить оптимальные кластеры. Оптимальные кластеры получаются, когда (Nc) достигает пика, и Nc оптимален, если (Nc) - глобальный максимум. Максимизация этого индекса эффективности может быть вставлена в любой из алгоритмов, типа максимального алгоритма расстояния, алгоритма K-средних и ISODATA алгоритма, перед разбиением наибольшего кластера и/или объединением малых кластеров.
![]() (5.47)
(5.47)

(a) (b)
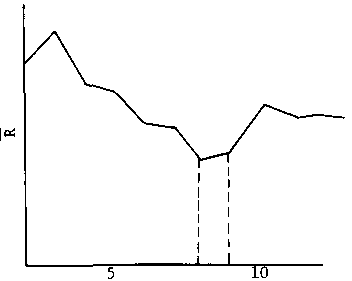
Число кластеров, Nc (c)
Рисунок 5.6 Иллюстративный пример для изменения ISODATA алгоритма; (a) набор данных из 225 точек; (b) кластеризация из 225 точек в семь или восемь групп; (c) R на графике Nc.