

5.2.2 Алгоритм Бачелора и Уилкинса
Бачелор и Уилкинс предложили другую простую эвристическую процедуру кластеризации, известную как алгоритм максимального расстояния. Для иллюстрации алгоритма используется простой пример состоящий из 10 двумерных образцов показанный на рисунке 5.2.
Пусть x1 будет центром первого кластера z1.
Определим образец наиболее удалённый от x1, это x6. Он будет центром кластера z2.
Вычислим расстояние от каждого оставшегося образца до z1 и z2.
Запомним минимальное расстояние для каждой пары таких вычислений.
Выберем максимум из минимальных расстояний.
Если это расстояние существенно больше чем часть расстояния d(z1, z2), создадим новый кластер с центром в z3. Иначепроцедуразавершена.
Вычислим расстояние от центра каждого из кластеров до оставшихся образцов и запомним минимумы каждой группы для трёх расстояний. Опять выберем максимум из минимальных расстояний. Если это расстояние существенная часть «типичного предыдущего максимального расстояния то соответствующий образец становится центром кластера z4. Иначе процедура завершается.
Повторяемпроцедурупокаочереднойобразецприводитксозданиюновогокластера.
Присваиваемоставшиесяобразцыближайшимкластерам.
В рассматриваемом примере x1, x6 и x8 соответствуют центрам кластеров. [x1, x3, x4], [x2, x6], и [x5, x7, x8, x9, x10] входят в соответствующие кластеры.
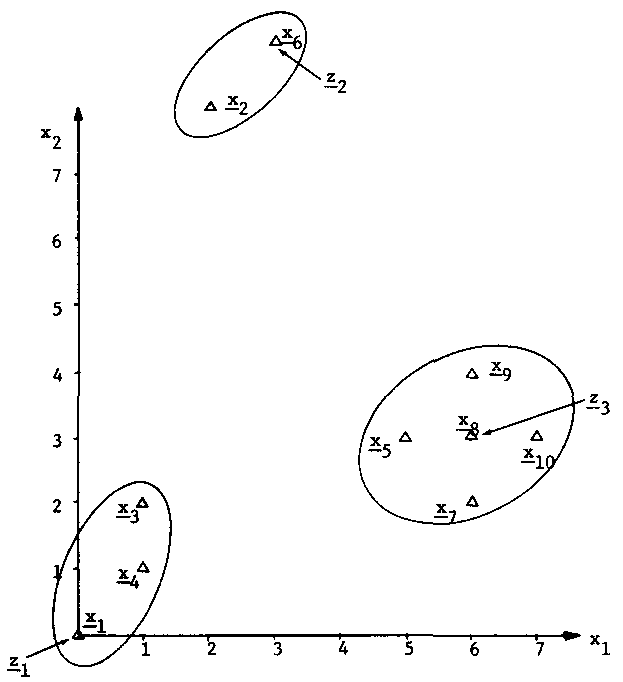
Figure 5.2.
1.
![]()
2.
![]()
Пусть
![]()
3.

4. Сохраняем все расстояния слева полученные на шаге 3.
5. Максимумрасстоянийсохранённыхнашаге4есть
![]()
6. Таким образом
![]()
пусть
![]()
7.
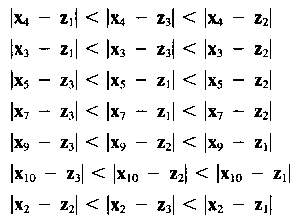
8. Сохраняем все расстояния слева.
9. Максимум этих минимальных расстояний есть
![]()
10. Поскольку
![]()
и условия возникновения нового кластера не удовлетворены, процедура завершается.
5.2.3 Алгоритм иерархической кластеризации основанный на к-ближайших соседях
Процесс классификации точки как элемента класса, к которому принадлежит самый близкий сосед, известен как классификация по ближайшему соседу. Если принадлежность решена большей частью k самых близких соседей, процедура будет названа k-ближайших-соседей решающим правилом. Алгоритм кластеризации, обсуждаемый в этом разделе следует концепции, предложенной Мизогучи и Какушо (1978). Процедуры состоят из двух стадий. На первой стадии, происходит предгруппировка данных, чтобы получить подкластеры. На второй стадии, подкластеры объединяются в иерархическом порядке, используя критерий подобия.
Алгоритм записывается следующим образом:
1. Выбираем подходящее значение к.
2. Вычисляем k(i), Pk(i), и k(i) для каждой точки образца i, где k(i) есть множество к-ближайших соседей точки i, i = 1, 2, . . . , N, основанное на евклидовой мере расстояния. Pk(i) называется потенциалом точки образца i, и определяется как
![]() (5.25)
(5.25)
где d(i,j) есть евклидово расстояние между точками образцов i и j. Очевидно, что d(i,i) = 0. k(i) есть множество образцов к-смежных с точкой i.
3. Подчинить каждую точку i точке j так, чтобы
![]() (5.26)
(5.26)
то есть подчинить каждую точку i одному из её соседей j который имеет наименьшее значение потенциала.
4. Обнаружить и сосчитать точки субкластеризации и присвоить их ближайшему субкластеру.
5. Объединить субкластеры если между ними существует к-граничная точка..
(a) Если между парой субкластеров существует к-граничная точка то объединить два наиболее похожих субкластера среди неупорядоченных пар субкластеров используя меру схожести SIM(m,n):
![]() (5.27)
(5.27)
где m и n обозначают подкластеры. SIM1(m,n) обозначает разницу в плотности между кластером и границей и может использоваться для определения точки минимума плотности. SIM2(m,n) есть относительный размер границы кластера и может использоваться для определения перешейка между двумя кластерами. Математически
![]() (5.28)
(5.28)
и
![]() (5.29)
(5.29)
где
![]() (5.30)
(5.30)
что является средним значением Pk(i) на всех i в Ykm,n и
![]() (5.31)
(5.31)
что есть среднее значение Pk(i) на точках кластера m. N(.) обозначает число элементов множества в скобках.
![]() (5.32)
(5.32)
есть множество точек в кластере m которые являются k смежными точками для кластера n. Wm есть множество точек в подкластере m.
(b) Если не существует k-граничных точек между двумя любыми парами кластеров то следует использовать меру расстояния для объединения кластеров p и q так что
![]() (5.33)
(5.33)
где обозначает множество неупорядоченных пар субкластеров.