

Оценка апостериорных вероятностей
Рассмотренные
в предыдущих разделах методы можно
использовать для оценки апостериорных
вероятностей
![]() на основанииппомеченных выборок,
пользуясь выборками для оценки
соответствующих плотностей
распределения. Предположим, что мы
на основанииппомеченных выборок,
пользуясь выборками для оценки
соответствующих плотностей
распределения. Предположим, что мы
размещаем
ячейку объема Vвокруг х и захватываемkвыборок,
![]() из которых оказываются помеченными
из которых оказываются помеченными
![]() .
Тогда очевидной оценкой совместной
вероятностир(х,
.
Тогда очевидной оценкой совместной
вероятностир(х,
![]() ) будет
) будет
![]()
Таким
образом, приемлемой оценкой для
![]() будет
будет
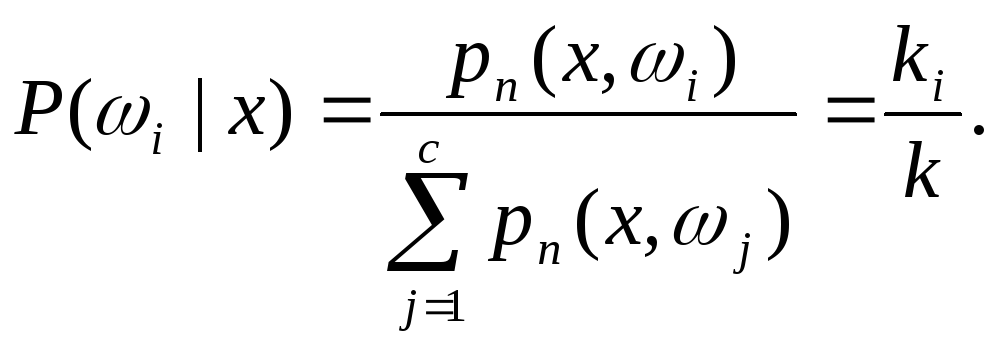
Иначе
говоря, оценка апостериорной вероятности
того, что состояние природы есть
![]() ,
является просто долей выборок в ячейке,
помеченных
,
является просто долей выборок в ячейке,
помеченных
![]() .
.
Чтобы свести уровень ошибки к минимуму, мы выбираем класс, наиболее часто представляемый в ячейке. Если имеется достаточное количество выборок и если ячейка достаточно мала, то можно показать, что результаты будут в этом случае близки к наилучшим.
Если
дело доходит до выбора размера ячейки,
то можно воспользоваться или методом
парзеновского окна, или методом
![]() ближайших соседей. В первом случае
ближайших соседей. В первом случае
![]() будет некоторой определенной функцией
отп,а именно
будет некоторой определенной функцией
отп,а именно
![]() =1/
=1/![]() .Во втором случае
.Во втором случае
![]() будет расширяться до тех пор, пока
не вместит некоторое определенное
число выборок, а именноk=
будет расширяться до тех пор, пока
не вместит некоторое определенное
число выборок, а именноk=![]() .В любом случае по мере устремленияп
к бесконечности в бесконечно малую
ячейку будет попадать бесконечное
число выборок. Тот факт, что объем ячейки
может стать бесконечно малым и все
же будет содержать бесконечно большое
число выборок, позволяет нам изучать
неизвестные вероятности с определенной
точностью и, таким образом, постепенно
добиваться оптимальных результатов.
Довольно интересно, как мы увидим далее,
что можно получать сравнимые результаты,
основывая наше решение только на
метке единственного ближайшего соседа
величины х.
.В любом случае по мере устремленияп
к бесконечности в бесконечно малую
ячейку будет попадать бесконечное
число выборок. Тот факт, что объем ячейки
может стать бесконечно малым и все
же будет содержать бесконечно большое
число выборок, позволяет нам изучать
неизвестные вероятности с определенной
точностью и, таким образом, постепенно
добиваться оптимальных результатов.
Довольно интересно, как мы увидим далее,
что можно получать сравнимые результаты,
основывая наше решение только на
метке единственного ближайшего соседа
величины х.
Правило ближайшего соседа Общие замечания
Пусть
![]() ={x1,
. . .,хn}
будет множествомnпомеченных выборок, и пусть
={x1,
. . .,хn}
будет множествомnпомеченных выборок, и пусть![]() будет выборкой, ближайшей к х. Тогдаправило ближайшего соседадля
классификации х заключается в том, что
х присваивается метка, ассоциированная
с
будет выборкой, ближайшей к х. Тогдаправило ближайшего соседадля
классификации х заключается в том, что
х присваивается метка, ассоциированная
с![]() .
Правило ближайшего соседа является
почти оптимальной процедурой; его
применение обычно приводит к уровню
ошибки, превышающему минимально возможный
байесовский. Как мы увидим, однако, при
неограниченном количестве выборок
уровень ошибки никогда не будет хуже
байесовского более чем в два раза.
.
Правило ближайшего соседа является
почти оптимальной процедурой; его
применение обычно приводит к уровню
ошибки, превышающему минимально возможный
байесовский. Как мы увидим, однако, при
неограниченном количестве выборок
уровень ошибки никогда не будет хуже
байесовского более чем в два раза.
Прежде
чем вдаваться в детали, давайте попытаемся
эвристически разобраться в том,
почему правило ближайшего соседа дает
такие хорошие результаты. Для начала
отметим, что метка
![]() ,
ассоциированная с ближайшим соседом,
является случайной величиной, а
вероятность того, что
,
ассоциированная с ближайшим соседом,
является случайной величиной, а
вероятность того, что![]() =
=![]() ,
есть просто апостериорная вероятность
,
есть просто апостериорная вероятность
![]() .
Когда количество выборок очень
велико, следует допустить, что
.
Когда количество выборок очень
велико, следует допустить, что![]() расположено достаточно близко к х,
чтобы
расположено достаточно близко к х,
чтобы
![]()
![]() .
В этом случае можем рассматривать
правило ближайшего соседа как
рандомизированное решающее правило,
которое классифицирует х путем выбора
класса
.
В этом случае можем рассматривать
правило ближайшего соседа как
рандомизированное решающее правило,
которое классифицирует х путем выбора
класса
![]() с вероятностью
с вероятностью
![]() .
Поскольку это точная вероятность того,
что природа находится в состоянии
.
Поскольку это точная вероятность того,
что природа находится в состоянии
![]() ,
значит, правило ближайшего соседа
эффективно согласует вероятности с
реальностью. Если мы определяем
,
значит, правило ближайшего соседа
эффективно согласует вероятности с
реальностью. Если мы определяем
![]() (х) как
(х) как
![]() (23)
(23)
то
байесовское решающее правило всегда
выбирает
![]() .
Когда вероятность
.
Когда вероятность
![]() близка к единице, выбор с помощью правила
ближайшего соседа почти всегда будет
таким же, как и байесовский, это значит,
что когда минимальная вероятность
ошибки мала, то вероятность ошибки
правила ближайшего соседа также мала.
Когда
близка к единице, выбор с помощью правила
ближайшего соседа почти всегда будет
таким же, как и байесовский, это значит,
что когда минимальная вероятность
ошибки мала, то вероятность ошибки
правила ближайшего соседа также мала.
Когда
![]() близка к 1/с,так что все классы
одинаково правдоподобны, то выборы,
сделанные с помощью этих двух правил,
редко бывают одинаковыми, но вероятность
ошибки в обоих случаях составляет
приблизительно 1-1/с.Не исключая необходимости в более
тщательном анализе, эти замечания
позволяют меньше удивляться хорошим
результатам правила ближайшего соседа.
близка к 1/с,так что все классы
одинаково правдоподобны, то выборы,
сделанные с помощью этих двух правил,
редко бывают одинаковыми, но вероятность
ошибки в обоих случаях составляет
приблизительно 1-1/с.Не исключая необходимости в более
тщательном анализе, эти замечания
позволяют меньше удивляться хорошим
результатам правила ближайшего соседа.
Наш анализ поведения правила ближайшего соседа будет направлен на получение условной средней вероятности ошибки Р(е|х) при большом количестве выборок, где усреднение производится по выборкам. Безусловная средняя вероятность ошибки будет найдена путем усредненияР(е|х)по всем х:
![]() (24)
(24)
Заметим, что решающее правило Байеса минимизирует Р(e) путем минимизацииР (е|x)для каждого х.
Если Р*(е|x)является минимально возможным значениемР(e|x), а Р* —минимально возможным значениемР(е),то
![]() (25)
(25)
и
![]() (26)
(26)