

15.Контроллер массива процессоров
Контроллер массива процессоров выполняет последовательный программный код, реализует команды ветвления программы, транслирует команды и сигналы управления в процессорные элементы. Рисунок 13.11 иллюстрирует одну из возможных реализаций КМП, в частности принятую в устройстве управления системы PASM.
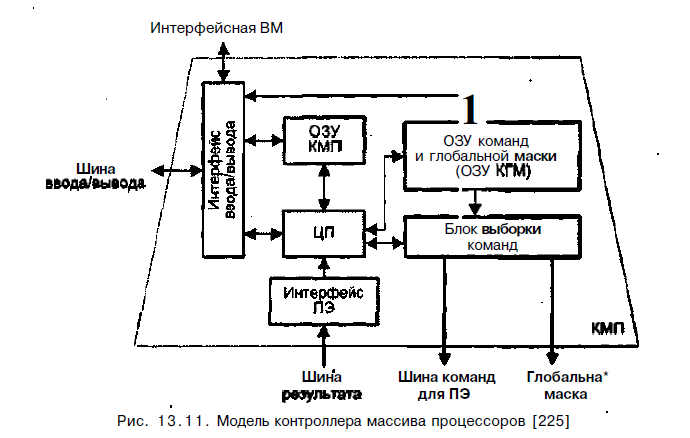
При загрузке из ИВМ программа через интерфейс ввода/вывода заносится в оперативное запоминающее устройство КМП (ОЗУ КМП). Команды для процессорных элементов и глобальная маска, формируемая на этапе компиляции, также через интерфейс ввода/вывода загружаются в ОЗУ команд и глобальной маски(ОЗУ КГМ). Затем КМП начинает выполнять программу, извлекая либо одну скалярную команду из ОЗУ КМП, либо множественные команды из ОЗУ КГМ. Скалярные команды - команды, осуществляющие операции над хранящимися в КМП скалярными данными, выполняются центральным процессором (ЦП) контролле-ра массива процессоров. В свою очередь, команды, оперирующие параллельными переменными, хранящимися в каждом ПЭ, преобразуются в блоке выборки команд в более простые единицы выполнения - нанокоманды. Нанокоманды совместно с маской пересылаются через шину команд для ПЭ на исполнение в массив процессоров. Например, команда сложения 32-разрядных слов в КМП системы МРР преобразуется в 32 нанокоманды одноразрядного сложения, которые каждым ПЭ обрабатываются последовательно,
В большинстве алгоритмов дальнейший порядок вычислений зависит от результатов и/или флагов условий предшествующих операций. Для обеспечения такого режима в матричных системах статусная информация, хранящаяся в процессорных элементах, должна быть собрана в единое слово и передана в КМП для выработки решения о ветвлении программы. Например, в предложении IF ALL (условие A) THEN DO В оператор В будет выполнен, если условие А справедливо во всех ПЭ. Для корректного включения/отключения процессорных элементов КМП должен знать результат проверки условия А во всех ПЭ. Такая информация передается в КМП по однонаправленной шине результата. В системе СМ-2 эта шина названа GLOBAL. В системе МРР для той же цели организована структура, называемая деревом SUM-OR. Каждый ПЭ помещает содержимое своего одноразрядного регистра признака на входы дерева, которое с помощью операции логического сложения комбинирует эту информацию и формирует слово результата, используемое в КМП для принятия решения.
16. Мімд. Мультипроцесори. Визначення, структура.
В настоящее время тем не менее наметился устойчивый интерес к архитектурам класса MIMD. MIMD-системы обладают большей гибкостью, в частности могут работать и как высокопроизводительные однопользовательские системы, и как многопрограммные ВС, выполняющие множество задач параллельно. Кроме того, архитектура MIMD позволяет наиболее эффективно распорядиться всеми преимуществами современной микропроцессорной технологии,
В MIMD-системе каждый процессорный элемент (ПЭ) выполняет свою программу достаточно независимо от других ПЭ. В то же время ПЭ должны как-то взаимодействовать друг с другом. Различие в способе такого взаимодействия определяет условное деление MIMD-систем на ВС с общей памятью и системы с распределенной памятью. В системах с общей памятью, которые характеризуют как сильно связанные (tightly coupled), имеется общая память данных и команд, доступная всем процессорным элементам с помощью общей шины или сети соединений. К этому типу, в частности, относятся симметричные мультипроцессоры (SMP, Symmetric Multiprocessor) и системы с неоднородным доступом к памяти (NUMA, Non-Uniform Memory Access).
В системах с распределенной памятью или слабо связанных (loosely coupled) многопроцессорных системах вся память распределена между процессорными элементами, и каждый ёлок памяти доступен только «своему» процессору. Сеть соединений связывает процессорные элементы друг с другом. Представителями этой группы могут служить системы с массовым параллелизмом (МРР, Massively Parallel Processing) и кластерные вычислительные системы.
Базовой моделью вычислений на MIMD-системе является совокупность независимых процессов, эпизодически обращающихся к совместно используемым данным. Существует множество вариантов этой модели. На одном конце спектра -распределенные вычисления, в рамках которых программа делится на довольно большое число параллельных задач, состоящих из множества подпрограмм.
На другом конце — модель потоковых вычислений, где каждая операция в программе может рассматриваться как отдельный процесс. Такая операция ожидает поступления входных данных (операндов), которые должны быть переданы ей дру-гими процессами. По их получении операция выполняется, и результирующее значение передается тем процессам, которые в нем нуждаются. Примерные значения пиковой производительности для различных типов систем класса MIMD.