

М инистерство
образования и науки Украины
инистерство
образования и науки Украины
Севастопольский национальный технический университет
Методические указания
к выполнению лабораторных работ по дисциплине
«Защита информации в компьютерных системах»
для студентов специальности 7.091501
“Компьютерные системы и сети”
всех форм обучения
Севастополь
2009
ЛАБОРАТОРНАЯ РАБОТА № 1. ХЭШ-ФУНКЦИИ
Цель работы: изучить назначение и принципы работы хэш-функций, программная реализация одного из методов функции свертки.
1.1 Теоретические основы
Хеширование – преобразование входного массива данных произвольной длины в выходную битовую строку фиксированной длины таким образом, чтобы изменение входных данных приводило к непредсказуемому изменению выходных данных. Однонаправленная функция H(M) применяется к сообщению произвольной длины М и возвращает значение фиксированной длины h. Многие функции позволяют вычислить значение фиксированной длины по входным данным произвольной длины, но у однонаправленных хэш-функций есть дополнительные свойства, делающие их однонаправленными:
зная М, легко вычислить h;
зная H, трудно определить М, для которого H(M)=h;
зная М, трудно определить другое сообщение М’, для которого Н(М)=Н(М’).
Такие преобразования также называются хеш-функциями или функциями свёртки, а их результаты называют хэшем, хэш-кодом или дайджестом сообщения.
Простым примером хеширования может служить нахождение контрольной суммы сообщения: сумма кодов всех входящих в него символов, от которой берётся несколько последних цифр. Полученное число является примером хэш-кода исходного сообщения. Существует множество способов хеширования, подходящих к различным задачам. Различаются хэш-функции устойчивостью к столкновениям, зависящей в большой степени от длины получаемого кода.
1.2 Обзор алгоритмов выработки хеш-кодов
1.2.1 Алгоритмы sha–0 и sha-1
В общем виде алгоритмы могут быть представлены следующим образом:
дополнение исходного сообщения;
инициализация переменных «сцепления»;
основной цикл алгоритма.
объединение переменных и вывод результата.
Исходное сообщение дополняется так, чтобы его длина была кратной 512 битам. В конец сообщения дописывается единичный бит, а затем нули. В последние 64 разряда записывается длина исходного (не дополненного) сообщения.
Используется пять 32-битовых переменных «сцепления»:
A = 0x67452301;
B = 0xefcdab89;
C = 0x98badcfe;
D = 0x10325476;
E = 0xc3d2e1f0.
Основной цикл алгоритма обрабатывает сообщение 512-битовыми блоками и продолжается, пока не исчерпаются все блоки сообщения. Переменные A, B, C, D, E копируются в a, b, c, d и e соответственно.
Сам цикл состоит из четырех этапов по 20 операций в каждом.
Каждая операция представляет собой нелинейную функцию над тремя из a, b, c, d и e, а затем выполняется сдвиг и сложение аналогично MD5. В SHA используется следующий набор нелинейных функций:
![]()
![]()
![]()
![]()
В алгоритме используются следующие 4 константы:
![]()
![]()
![]()
![]()
Блок сообщения из шестнадцати 32-битных слов преобразуется в восемьдесят 32-битных слов по следующему алгоритму:
![]()
![]()
В сдвиге на 1 разряд влево заключается отличие стандарта SHA-1 от SHA-0. Таким образом для SHA-0 будет выполняться следующий алгоритм:
![]()
В цикле для t от 0 до 79 производятся следующие действия:
![]()
![]()
![]()
![]()
![]()
![]()
Знак + в данном случае значит сложение по модулю 232.
На рисунке 1 показана одна операция SHA.
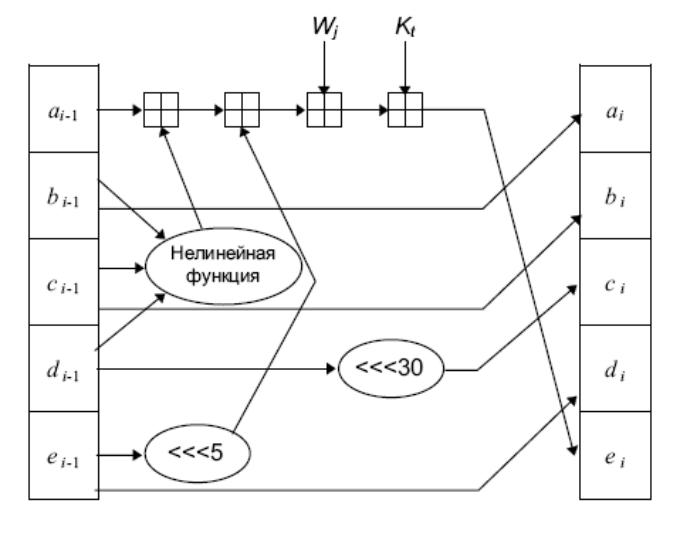
Рисунок 1 – Операция SHA-1.
Проверочные вектора для хэш-функции SHA-0:
Входной вектор |
Хеш-код |
"" (пустая строка) |
F96CEA198AD1DD5617AC084A3D92C6107708C0EF |
"message digest" |
C1B0F222D150EBB9AA36A40CAFDC8BCB ED830B14 |
8 повторений "1234567890" |
4AA29D14D171522ECE47BEE8957E35A41F3E9CFF |
Проверочные вектора для хэш-функции SHA-1:
Входной вектор |
Хеш-код |
"" (пустая строка) |
DA39A3EE5E6B4B0D3255BFEF95601890AFD80709 |
"message digest" |
C12252CEDA8BE8994D5FA0290A47231C1D16AAE3 |
8 повторений "1234567890" |
50ABF5706A150990A08B2C5EA40FA0E585554732 |
1.2.2 Хеш-функция MD2
MD2 – хэш-функция, разработанная Бертом Калиски в 1992 году. Размер хэша – 128 бит. Размер блока входных данных – 512 бит.
Предполагается, что на вход подано сообщение, состоящее из b байт, хэш которого нам предстоит вычислить. Здесь b может быть нулем. Запишем сообщение побайтово, в виде: m0m1…mb-1.
Ниже приведены 5 шагов, используемые для вычисления хэша сообщения.
Шаг 1 – Добавление недостающих бит
Сообщение расширяется так, чтобы его длина в байтах по модулю 16 равнялась 0. Расширение производится всегда, даже если сообщение изначально имеет нужную длину.
Расширение производится следующим образом: i байт, равных i, добавляется к сообщению. В итоге, к сообщению добавляется как минимум 1 байт, и как максимум 16.
На этом этапе (после добавления байт) сообщение имеет длину в точности кратную 16 байтам. Обозначим его M[0..N-1], где N кратно 16.
Шаг 2 – Добавление контрольной суммы
16-байтная контрольная сумма сообщения добавляется к результату предыдущего шага.
Этот шаг использует 256-байтную «случайную» перестановочную матрицу, состоящую из цифр числа пи:
PI_SUBST[256] = {
41, 46, 67, 201, 162, 216, 124, 1, 61, 54, 84, 161, 236, 240, 6, 19,
98, 167, 5, 243, 192, 199, 115, 140, 152, 147, 43, 217, 188, 76, 130, 202,
30, 155, 87, 60, 253, 212, 224, 22, 103, 66, 111, 24, 138, 23, 229, 18,
190, 78, 196, 214, 218, 158, 222, 73, 160, 251, 245, 142, 187, 47, 238, 122,
169, 104, 121, 145, 21, 178, 7, 63, 148, 194, 16, 137, 11, 34, 95, 33,
128, 127, 93, 154, 90, 144, 50, 39, 53, 62, 204, 231, 191, 247, 151, 3,
255, 25, 48, 179, 72, 165, 181, 209, 215, 94, 146, 42, 172, 86, 170, 198,
79, 184, 56, 210, 150, 164, 125, 182, 118, 252, 107, 226, 156, 116, 4, 241,
69, 157, 112, 89, 100, 113, 135, 32, 134, 91, 207, 101, 230, 45, 168, 2,
27, 96, 37, 173, 174, 176, 185, 246, 28, 70, 97, 105, 52, 64, 126, 15,
85, 71, 163, 35, 221, 81, 175, 58, 195, 92, 249, 206, 186, 197, 234, 38,
44, 83, 13, 110, 133, 40, 132, 9, 211, 223, 205, 244, 65, 129, 77, 82,
106, 220, 55, 200, 108, 193, 171, 250, 36, 225, 123, 8, 12, 189, 177, 74,
120, 136, 149, 139, 227, 99, 232, 109, 233, 203, 213, 254, 59, 0, 29, 57,
242, 239, 183, 14, 102, 88, 208, 228, 166, 119, 114, 248, 235, 117, 75, 10,
49, 68, 80, 180, 143, 237, 31, 26, 219, 153, 141, 51, 159, 17, 131, 20};
Пусть S[i] означает i-ый элемент этой таблицы. Она будет приведена ниже. Контрольная сумма вычисляется следующим образом:
// Обнуление контрольной суммы
for i = 0 to 15 do:
set C[i] to 0.
end // конец цикла по i
set L to 0.
//Обработка каждого 16-байтового блока
for i = 0 to N/16-1 do
// Контрольная сумма блока i
for j = 0 to 15 do
set c to M[i*16+j].
set C[j] to C[j] xor S[c xor L].
set L to C[j].
end // конец цикла по j
end // конец цикла по i
16-байтная контрольная сумма C[0..15] добавляется к сообщению. Теперь сообщение можно записать в виде M[0..N1-1], где N1 = N + 16.
Шаг 3 – Инициализация MD-буфера
Для вычисления хэша используется 48-байтный буфер X. Он инициализируется нулями.
Шаг 4 – Обработка сообщения блоками по 16 байт
На этом шаге используется та же 256-байтная перестановочная матрица S, как и на шаге 2.
Производим следующие операции:
//Обработка каждого блока по 16 байт
for i = 0 to N1/16-1 do
// Копирование блока i в X
for j = 0 to 15 do
set X[16+j] to M[i*16+j].
set X[32+j] to (X[16+j] xor X[j]).
end // конец цикла по j
set t to 0.
//Выполнение 18 раундов
for j = 0 to 17 do
// i-ый раунд
for k = 0 to 47 do
set t and X[k] to (X[k] xor S[t]).
end // конец цикла по k
set t to (t+j) modulo 256.
end // конец цикла по j
end // конец цикла по i
Шаг 5 – Формирование хэша
Хэш вычисляется как результат X[0..15] в начале идет байт X[0], а конце X[15].
Проверочные вектора для хэш-функции MD2:
Входной вектор |
Хеш-код |
"" (пустая строка) |
8350E5A3E24C153DF2275C9F80692773 |
"message digest" |
AB4F496B FB2A530B219FF33031FE06B0 |
8 повторений "1234567890" |
05DBBA94 14433324 75B8E3F5 72F5D148 |
1.2.3 Хеш-функция MD4
MD4 – хэш-функция, разработанная профессором Массачусетского университета Рональдом Ривестом в 1990 году. Для произвольного входного сообщения функция генерирует 128-разрядное хэш-значение.
Предполагается, что на вход подано сообщение, состоящее из b байт, хэш которого нам предстоит вычислить. Здесь b может быть нулем. Запишем сообщение побитово, в виде: m0m1…mb-1.
Ниже приведены 5 шагов, используемые для вычисления хэша сообщения.
Шаг 1 – Добавление недостающих битов
Сообщение расширяется так, чтобы его длина в битах по модулю 512 равнялась 448. Расширение производится всегда, даже если сообщение изначально имеет нужную длину.
Расширение производится следующим образом: один бит, равный 1, добавляется к сообщению, а затем добавляются биты, равные 0. В итоге, к сообщению добавляется, как минимум 1 бит, и как максимум 512.
Шаг 2 – Добавление длины сообщения
64-битное представление b (длины сообщения перед расширением) добавляется к результату предыдущего шага. В маловероятном случае, когда b больше, чем 264, используются только 64 младших бита. Эти биты добавляются в виде двух 32-битных слов, и первым добавляется слово, содержащее младшие разряды.
На этом этапе получается сообщение длиной кратной 512 битам или 16-ти 32-битным словам. Обозначим его M[0..N-1], где N кратно 16.
Шаг 3 – Инициализация MD-буфера
Для вычисления дайджеста сообщения используется буфер, состоящий из 4 слов (32-битных регистров): A, B, C, D. Эти регистры инициализируются следующими шестнадцатеричными числами (младшие байты сначала):
A = 0x01234567;
B = 0x89abcdef;
C = 0xfedcba98;
D = 0x76543210.
Шаг 4 – Обработка сообщения блоками по 16 слов
Определим три вспомогательные функции, каждая из которых получает на вход три 32-битных слова, и по ним вычисляет одно 32-битное слово.
![]()
![]()
![]()
На каждую битовую позицию F действует как условное выражение: если X, то Y; иначе Z. G действует на каждую битовую позицию как функция максимального значения: если по крайней мере в двух словах из X, Y, Z соответствующие биты равны 1, то G выдаст 1 в этом бите, а иначе G выдаст бит, равный 0. Функция H реализует побитовый xor, она обладает таким же свойством, как F и G.
Алгоритм хеширования на абстрактном языке программирования:
// Обработка каждого блока из 16-ти слов
for i = 0 to N/16-1 do
// Запись i-го блока в переменную X
for j = 0 to 15 do
set X[j] to M[i*16+j].
end // конец цикла по j
// Сохранение A как AA, B как BB, C как CC, и D как DD
AA = A
BB = B
CC = C
DD = D
// Раунд 1
// [abcd k s] соответствует a = (a + F(b,c,d) + X[k]) <<< s
// Производится 16 следующих операций:
[ABCD 0 3] [DABC 1 7] [CDAB 2 11] [BCDA 3 19]
[ABCD 4 3] [DABC 5 7] [CDAB 6 11] [BCDA 7 19]
[ABCD 8 3] [DABC 9 7] [CDAB 10 11] [BCDA 11 19]
[ABCD 12 3] [DABC 13 7] [CDAB 14 11] [BCDA 15 19]
// Раунд 2
// [abcd k s] соответствует a = (a + G(b,c,d) + X[k] + 5A827999) <<< s
// Производится 16 следующих операций:
[ABCD 0 3] [DABC 4 5] [CDAB 8 9] [BCDA 12 13]
[ABCD 1 3] [DABC 5 5] [CDAB 9 9] [BCDA 13 13]
[ABCD 2 3] [DABC 6 5] [CDAB 10 9] [BCDA 14 13]
[ABCD 3 3] [DABC 7 5] [CDAB 11 9] [BCDA 15 13]
// Раунд 3
// [abcd k s] соответствует a = (a + H(b,c,d) + X[k] + 6ED9EBA1) <<< s
// Производится 16 следующих операций:
[ABCD 0 3] [DABC 8 9] [CDAB 4 11] [BCDA 12 15]
[ABCD 2 3] [DABC 10 9] [CDAB 6 11] [BCDA 14 15]
[ABCD 1 3] [DABC 9 9] [CDAB 5 11] [BCDA 13 15]
[ABCD 3 3] [DABC 11 9] [CDAB 7 11] [BCDA 15 15]
// Затем производим следующие операции сложения
A = A + AA
B = B + BB
C = C + CC
D = D + DD
end // конец цикла по i
Шаг 5 – Формирование хэша
Результат (хэш-функция) получается как ABCD, начиная с младшего бита A, и заканчивая старшим битом D.
Проверочные вектора для хэш-функции MD4:
Входной вектор |
Хеш-код |
"" (пустая строка) |
31D6CFE0D16AE931B73C59D7E0C089C0 |
"message digest" |
D9130A8164549FE818874806E1C7014B |
8 повторений "1234567890" |
E33B4DDC9C38F2199C3E7B164FCC0536 |