

2.5. Приведение корреляционной матрицы к диагональной форме
Преобразование корреляционной матрицы к диагональной форме основано на следующем свойстве вещественной (действительной) симметричной матрицы.
Пусть R- невырожденная
корреляционная матрица и имеетnразличных собственных чисел![]() .
Пусть
.
Пусть![]() - соответствующие собственные векторы,
выбранные из пар собственных векторов,
соответствующих каждому собственному
числу, составляющие ортонормированный
базис вn-мерном пространстве. Пусть
- соответствующие собственные векторы,
выбранные из пар собственных векторов,
соответствующих каждому собственному
числу, составляющие ортонормированный
базис вn-мерном пространстве. Пусть![]() - матрица, столбцами которой являются
собственные векторыai.
Рассмотрим матрицу
- матрица, столбцами которой являются
собственные векторыai.
Рассмотрим матрицу

где E- единичная матрица. Следовательно, матрицаAявляется ортогональной.
Напомним, что некоторая
матрица Aортогональна, если![]() .
По уравнению
.
По уравнению![]() получим
получим![]() ,
где столбцами матрицы в правой части
являются векторы
,
где столбцами матрицы в правой части
являются векторы![]() .
Учитывая, что векторыaiортогональны, получим
.
Учитывая, что векторыaiортогональны, получим
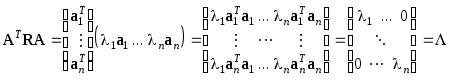 .
.
Матрица
![]() ортогональна, и ее диагональные элементы
являются собственными числами. Из
условия
ортогональна, и ее диагональные элементы
являются собственными числами. Из
условия![]() следует
следует![]() и
и![]() ,
так как
,
так как![]() .
.
Следовательно,
невырожденная корреляционная матрица
Rможет быть приведена к диагональной
форме путем ортогонального преобразования![]() .
.
Пусть
![]() - некоторый вектор, заданный своими
проекциями на осях координат
- некоторый вектор, заданный своими
проекциями на осях координат![]() .
Рассмотрим вектор
.
Рассмотрим вектор![]() ,
где
,
где![]() ,
а строками матрицы
,
а строками матрицы![]() являются собственные векторыaiTлинейного преобразованияR. Тогда
являются собственные векторыaiTлинейного преобразованияR. Тогда

Следовательно,
компонента yi вектораy - это скалярное произведение
собственного вектораai и вектораx. С другой стороны, скалярное
произведение - это произведение модулей
векторовai иx на
косинус угла между ними. Так как![]() ,
то это есть произведение
,
то это есть произведение![]() на косинус угла междуai иx - проекция вектораxнаai.
Поэтому векторxпредставлен своими проекциямиyiна ортонормированный базис собственных
векторов корреляционной матрицыR.
Можно считать, что новый базис
на косинус угла междуai иx - проекция вектораxнаai.
Поэтому векторxпредставлен своими проекциямиyiна ортонормированный базис собственных
векторов корреляционной матрицыR.
Можно считать, что новый базис![]() образует новоеn-мерное пространство
признаков
образует новоеn-мерное пространство
признаков![]() ,
принимающих свои значения наNобъектах.
,
принимающих свои значения наNобъектах.
Значения nпризнаковYi, как бы измеренных наNобъектах, образуют новую матрицу данных![]() ,
полученную из матрицыXортогональным
преобразованиемA:
,
полученную из матрицыXортогональным
преобразованиемA:
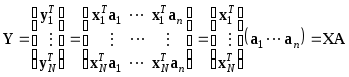 .
.
Корреляционная матрица R, вычисленная по матрицеX, представляет собой матрицу
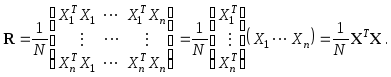
Вычислим среднее признака Yj
![]() ,
,
так как матрица Xстандартизована. Вычислим величину

Тогда матрица является ковариационной матрицей,
вычисленной по матрицеY. Диагональная
структура матрицыпоказывает,
как и следовало ожидать, независимость
признаков![]() .
Собственные числаiявляются дисперсиями этих признаков,
то есть
.
Собственные числаiявляются дисперсиями этих признаков,
то есть![]() .
Если разделить значения компонент
каждого признакаYiна
величину
.
Если разделить значения компонент
каждого признакаYiна
величину![]() ,
то матрицаYбудет приведена к
стандартизованному виду. Тогда
преобразование
,
то матрицаYбудет приведена к
стандартизованному виду. Тогда
преобразование![]() даст стандартизованную матрицу данныхY с единичной корреляционной матрицей:
даст стандартизованную матрицу данныхY с единичной корреляционной матрицей:

2.6. Геометрическая интерпретация главных компонент на плоскости
Пусть в соответствии
со статистической гипотезой порождения
матрицы данных X вn-мерном
пространстве признаков существует
многомерное нормальное распределение
с плотностью вероятности![]() .
Для стандартизованной матрицыXмы
полагаем, что
.
Для стандартизованной матрицыXмы
полагаем, что
![]() .
.
Проведем ортогональное
преобразование матрицы данных Xв
новую матрицу данных![]() ,
гдеA- матрица, столбцами которой
являются собственные векторы корреляционной
матрицыR. Тем самым мы перешли в
новое признаковое пространство,
образованное ортонормированным базисом
линейного преобразованияR. Очевидно,
что в новом признаковом пространстве
задано нормальное распределение с
плотностью вероятности
,
гдеA- матрица, столбцами которой
являются собственные векторы корреляционной
матрицыR. Тем самым мы перешли в
новое признаковое пространство,
образованное ортонормированным базисом
линейного преобразованияR. Очевидно,
что в новом признаковом пространстве
задано нормальное распределение с
плотностью вероятности
![]()
![]() .
.
Так как
![]() то
то
![]() ,
,
 ;
; .
.
Тогда
 .
.
Пусть n = 2, тогда двухмерное нормальное распределение имеет вид
 .
.
Рассмотрим уравнение
![]() .
Из курса аналитической геометрии
известно, что это уравнение линии второго
порядка. При заданномpи найденных
.
Из курса аналитической геометрии
известно, что это уравнение линии второго
порядка. При заданномpи найденных![]() данная линия является линией постоянного
значения плотности вероятности
данная линия является линией постоянного
значения плотности вероятности .
Преобразуем данное уравнение линии
второго порядка к каноническому виду
.
Преобразуем данное уравнение линии
второго порядка к каноническому виду![]() .
Так как
.
Так как![]() ,
то данное уравнение является каноническим
уравнением эллипса в системе координат,
образованной собственными векторами,
которые соответствуют собственным
числам
,
то данное уравнение является каноническим
уравнением эллипса в системе координат,
образованной собственными векторами,
которые соответствуют собственным
числам![]() .
.
Если r>0, то![]() и система главных компонентy10y2повернута на 450относительно
исходной системы координатx10x2.
Еслиr<0, то
и система главных компонентy10y2повернута на 450относительно
исходной системы координатx10x2.
Еслиr<0, то![]() и система главных компонентy10y2повернута на 1350 относительноx10x2.
и система главных компонентy10y2повернута на 1350 относительноx10x2.
Если r=0, то![]() .
Тогда уравнение эллипса представляет
собой уравнение окружности
.
Тогда уравнение эллипса представляет
собой уравнение окружности![]() радиуса
радиуса![]() .
В этом случае система главных компонентy10y2может быть
ориентирована в любом направлении, то
есть любое направление является главным
для такого линейного преобразованияR. Еслиr=1, то
.
В этом случае система главных компонентy10y2может быть
ориентирована в любом направлении, то
есть любое направление является главным
для такого линейного преобразованияR. Еслиr=1, то![]() .
Тогда уравнение эллипса для линии
постоянного значения плотности
вероятности вырождается в уравнение
для двух точек, расположенных на оси
0y1, вида
.
Тогда уравнение эллипса для линии
постоянного значения плотности
вероятности вырождается в уравнение
для двух точек, расположенных на оси
0y1, вида![]() (рис. 2.1).
(рис. 2.1).

Рис.2.1. Главные компоненты
Определим уравнение максимального эллипса в соответствии с правилом “трех сигм”, согласно которому 99.73% всех наблюдений сосредоточено внутри него.
Согласно свойствам канонического
уравнения эллипса его главная ось
совпадает с направлением первой главной
компоненты 0y1. Длина главной
полуоси составляет величину![]() .
В то же время максимальное положительное
случайное отклонение величиныy1на оси 0y1от центра координат
с вероятностью 0.9973 не превышает величины
.
В то же время максимальное положительное
случайное отклонение величиныy1на оси 0y1от центра координат
с вероятностью 0.9973 не превышает величины![]() .
Следовательно,
.
Следовательно,![]() ,
откудаp=9.
,
откудаp=9.
Проведя те же рассуждения
для второй оси максимального эллипса,
получим, что уравнение имеет вид
![]() и описывает линию постоянного значения
плотности вероятности на уровне
и описывает линию постоянного значения
плотности вероятности на уровне
 .
.
Так как длина главной
полуоси равна
![]() ,
то при увеличении значенияrдлина
главной полуоси увеличивется. В то же
время длина второй полуоси эллипса
,
то при увеличении значенияrдлина
главной полуоси увеличивется. В то же
время длина второй полуоси эллипса![]() уменьшается при увеличенииr.
Следовательно, чем сильнее связаны
признакиX1иX2корреляционной зависимостью, тем больше
дисперсия
уменьшается при увеличенииr.
Следовательно, чем сильнее связаны
признакиX1иX2корреляционной зависимостью, тем больше
дисперсия![]() признакаY1и меньше дисперсия
признакаY1и меньше дисперсия![]() признакаY2при неизменной
суммарной дисперсии
признакаY2при неизменной
суммарной дисперсии![]() .
.