

14.2. Хранилища данных. Многомерные хранилища данных
Комбинация многомерного и реляционного подхода: киоск данных
Каждая из описанных моделей имеет как достоинства, так и недостатки.
Многомерная модель позволяет производить быстрый анализ данных, не позволяет хранить большие массивы информации.
Реляционная модель практически не имеет ограничений по объему накапливаемых данных, однако имеет низкую скорость выполнения аналитических запросов.
Можно ли совместить эти два подхода?
Во-первых редко возникает операция когда для анализа необходима вся информация, хранящая в хранилище. Обычно каждый аналитик обслуживает одно из направлений деятельности организации.
Реальный объем этих данных позволяет вместить их в многомерные хранилища. Источником данных для них должен быть центральное хранилище организации. Многомерные хранилища данных выполняют роль мелких складов.
Киоск данных - это специализированное многомерное хранилище, обслуживающее одно из направлений деятельности предприятия.
Комбинация будет выглядеть следующим образом.
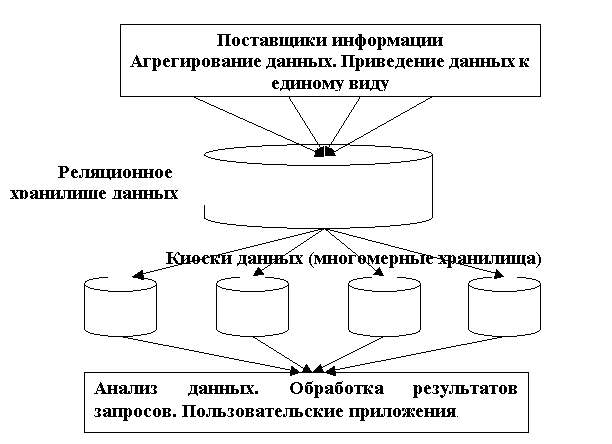
Системы, использующие хранилища данных строятся на основе архитектуры клиент-сервер. Хранилище размещается на специализированном сервере для него используют мощные многопроцессорные вычислительные системы. В качестве СУБД используют СУБД, поддерживающие параллельную обработку запросов:
1. TERADATA,NCD
2. DB\2, IBM
3. Oracle
4. INFORMIK
Киоски данных реализуются с использованием серверов многомерных баз данных:
1. Essbase (Arbor Soft ware)
2. Oracle Express (Oracle)
3. Centium (Planning Sciences)
Хранилища данных принято делить:
ип хранилища |
объем данных |
число строк в фактологической таблице |
маленькие |
до 3 Гбайт |
несколько миллионов строк |
средние |
до 25 Гбайт |
до 100 млн. строк |
большие |
до 200 Гбайт
|
несколько сотен млн.строк |
сверхбольшие |
свыше 200 Гбайт |
миллиард и более |
В таблице приведен полезный объем, использованый для анализа. Дисковое пространство обычно в несколько раз больше за счет того, что необходимо поддерживать систему индексов, обычно в 5-10 раз.
14.3. Методы аналитической обработки (olap)
1. используется статистический метод: регрессивного, факторного, дисперсионного анализа, анализа временных рядов
2. метод искусственного интеллекта - нейронные сети, нечетная логика, генетические алгоритмы, методы извлечений знаний. Эти методы называют методы интеллектуального анализа данных (ИАД)
Средство анализа данных в системах принятия решений (СППР) на основе хранимых данных, используется для решения следующих задач:
1. выделение в данных групп, сходных по некоторым признакам
2. нахождение и аппроксимация зависимостей, а также поиск наиболее значимых параметров
3. анализ аномалий, т.е. поиск данных, отклоняющихся от среднего
4. прогнозирование развития событий на основе хранящейся ретроспективной информации об их состоянии в прошлом