

7. Структура генетического алгоритма
Основные этапы процесса эволюции, на основе которого создаются различные схемы генетического поиска, согласно Холланду, следующие:
Конструируется начальная популяция.
Выбираются случайным образом две родительские хромосомы из популяции.
Копирование выбранных хромосом и применение генетических операторов для создания новых хромосом.
Отбор и последующее удаление хромосом из популяции для восстановления первоначального ее размера.
Если не пройдено заданное число шагов, то возврат к шагу 1, в противном случае конец работы алгоритма.
Простой генетический алгоритм (ПГА) был впервые описан Голдбергом на основе работ Холланда. Механизм простого ГА очень несложен. Он копирует последовательности и переставляет их части. Предварительно ГА случайно генерирует популяцию последовательностей - стрингов (хромосом). Затем ГА применяет множество простых операций к начальной популяции и генерирует новые популяции.
ПГА состоит из операторов:
репродукции;
кроссинговера;
мутации.
Первоначально, простой генетический алгоритм (ПГА), предложенный Гольдбергом, имел следующую структуру:
Создание исходной популяции П0, оценка и перенос ее в текущую популяцию;
Создание с помощью оператора репродукции новой популяции Пi и копирование ее в текущую популяцию;
Оценка текущей популяции Пi;
Если не прошло заданное число поколений, то возврат к пункту 2.
Вывод индивида, обладающего лучшим значением ЦФ.
В приведенном алгоритме использовался оператор репродукции, представляющий собой объединение четырех основных генетических операторов: селекции, кроссинговера, мутации и отбора, однако позднее оператор репродукции был разделен на составные части, что обеспечило большую гибкость структуры генетических алгоритмов.
Репродукция - процесс, при котором хромосомы копируются согласно их ЦФ. Эту функцию называют fitness. Хромосомы с “лучшими” значениями ЦФ имеют большую вероятность попадания в следующую генерацию. Оператор репродукции (ОР) является искусственной версией натуральной селекции, “выживания сильнейших” по Дарвину.
ОР представляется в алгоритмической форме различными способами. Самый простой – так называемое “колесо рулетки”, в котором каждая хромосома имеет сектор, по величине пропорциональный его ЦФ (рис. 11).
Во время одной генерации колесо рулетки вращается и после ее остановки, указатель определяет хромосому, выбранную для следующего оператора. Очевидно, но не всегда выполнимо, что хромосома с большой ЦФ в результате ОР будет выбрана для следующего оператора. ОР выбирает хромосомы для оператора кроссинговера (ОК).
Отношение
![]() называют вероятностью
выбора хромосом
при ОР и обозначают
называют вероятностью
выбора хромосом
при ОР и обозначают
![]() где Fi(x)
- значение
ЦФ i - й хромосомы в популяции, sum
F(x)-
суммарное значение ЦФ всех хромосом в
популяции. Величину Pi(ОР)
также называют нормализованной величиной.
Ожидаемое число копий i-й хромосомы
после ОР определяется выражением N
= Pi(OP)
n,
где n - число анализируемых хромосом.
где Fi(x)
- значение
ЦФ i - й хромосомы в популяции, sum
F(x)-
суммарное значение ЦФ всех хромосом в
популяции. Величину Pi(ОР)
также называют нормализованной величиной.
Ожидаемое число копий i-й хромосомы
после ОР определяется выражением N
= Pi(OP)
n,
где n - число анализируемых хромосом.
Число копий
хромосомы, переходящее в следующую
стадию, также иногда определяют на
основе выражения
![]() .
.
Предположим, что заданы шаг (временной) t, m примеров схем H, содержащихся в популяции A(t). Тогда m(H, t) - возможное число различных схем H при заданном t.
В течение репродукции хромосомы копируются согласно их ЦФ: стринг A(i) получает выбор с вероятностью, определяемой выражением Pi(ОР).
Ожидается m(H, t + 1)
представителей схемы H в популяции в
момент времени t + 1. Тогда
![]() где F(H)
- средняя ЦФ хромосом, представленных
схемой H в момент t.
где F(H)
- средняя ЦФ хромосом, представленных
схемой H в момент t.
Если обозначить
среднюю ЦФ всей популяции как
F*
= sum[F(j)]
/ n, то
![]()
То есть схема, имеющая ЦФ выше средней ЦФ популяции, получит больше возможностей для копирования и наоборот.
Предположим, что схема H имеет величину c F*, выше средней ЦФ популяции, где c - константа. Тогда предыдущее выражение можно модифицировать:
![]() .
.
Начиная с t = 0 и
допуская постоянную величину c,
получим:
![]()
Некоторые исследователи считают, что репродукция может привести к экспоненциальному уменьшению или увеличению схем, особенно если выполнять генерации параллельно.
Известно, что вероятность “выживания” хромосомы А на шаге t после ОР определяется величиной Ps(t) = (1 – P2)t – 1 P2. Величина t изменяется от 1, 2, ... , N, где N – число генераций генетического алгоритма.
Отметим, что если мы только копируем старые хромосомы без обмена, поисковое пространство не увеличивается и процесс затухает. Поэтому необходимо использование ОК, который создает новые хромосомы и увеличивает или уменьшает число схем в популяции.
Приведем верхний уровень ГА, описанного Холландом:
Конструирование начальной популяции.
Оценка хромосом в популяции.
Выбор пар хромосом из популяции.
Применение ОК с вероятностью Р(ОК). Если все пары проанализированы, то переходим к 5°, иначе к 4°.
Применение ОМ к каждой новой хромосоме с вероятностью Р(ОМ).
Применение оператора инверсии к каждой новой хромосоме с вероятностью Р(ОИ).
Верхний уровень генетического алгоритма, описанного Девисом, выглядит несколько иначе:
Инициализация популяции хромосом.
Оценка каждой хромосомы в популяции.
Создание новых хромосом посредством скрещивания имеющихся хромосом; применение мутации и рекомбинации.
Устранение хромосом из популяции, чтобы освободить место для новых хромосом.
Оценка новых хромосом и вставка их в популяцию.
Если время исчерпано, то остановка и возврат к наилучшей хромосоме, если нет, то переход к 3°.
Сравнив описания ГА Голдберга, Холланда и Девиса, можно заметить, что они представляют собой реализацию одной основной идеи моделирования эволюции с некоторыми модификациями. Однако эти изменения могут оказывать существенное влияние на качество окончательного решения.
Таким образом, ожидаемое число копий, которое частная схема H получает в следующей генерации после выполнения ОР, ОК, ОМ, определяется по формуле:
![]()
Это выражение называется “схемой теорем” или фундаментальной теоремой ГА.
Проведенный анализ позволяет описать ГА следующим образом.
В начале работы случайным образом генерируется множество решений (естественный аналог - популяция особей). Каждое решение кодируется набором чисел (хромосомный набор генов) в соответствии со спецификой задачи. Диапазон значений каждого числа (алфавит) должен быть минимальным (в идеальном случае - 0 и 1). Каждое число (ген) должно иметь в наборе (хромосоме) жестко фиксированное место (локус), а также нести адекватную информацию о кодируемом объекте, явлении, свойстве и т.п.
После формирования исходного множества решений - первого поколения популяции (а также после генерации следующих поколений) необходимо произвести селекцию нереализуемых решений и решений с очень низкой оценкой, т.е. исключить их из состава множества. Для оценки решения (хромосомы) применяется функция пригодности (выживание во внешних природных условиях). Функция пригодности так же, как и кодирование решений, реализуется в контексте задачи.
После операции селекции случайным образом генерируется следующее поколение множества решений при помощи операции скрещивания или кроссинговера. Операция скрещивания производится следующим образом.
В качестве родителей случайно выбираются два решения (хромосомы). Затем случайно в хромосоме выбирается точка кроссинговера. После этого часть генов, ограниченная точкой кроссинговера, одной хромосомы меняется местами с аналогичной частью второй хромосомы, т.е. происходит перекомпоновка родительских хромосом и рождение потомков. Благодаря применению операции кроссинговера осуществляется перебор возможных решений.
Операция мутации может применяться либо после операции, либо после попадания процесса поиска в локальный оптимум (множество решений не улучшается в течение многих поколений). Она предназначена для генерации качественно новых значений генов, которые должны выводить процесс поиска из локальных оптимумов.
Итак, построение субоптимального решения (в естественной среде - развитие наследственной информации) осуществляется путем:
а) скрещивания двух решений - при этом происходит генерация двух новых решений путем перекомпоновки двух старых решений;
б) случайного преобразования мутации, старого решения путем генерации качественно нового гена или генов.
Модифицированная структура генетических алгоритмов выглядит следующим образом:
Создание первоначальной популяции, оценка и перенос ее в текущую популяцию;
Селекция текущей популяции;
Кроссинговер пар, выбранных оператором селекции из текущей популяции;
Мутация особей текущей популяции;
Оценка текущей популяции;
Отбор из полученной новой популяции заданного числа особей;
Если не прошло заданное число поколений, то возврат на 2;
Вывод индивида с лучшим значением ЦФ.
С учетом всех последующих модификаций схему работы ГА можно представить в виде структурной схемы, изображенной на рис. 12.
Для нормальной работы ГА, как правило, устанавливают следующие параметры:
МОДИФИЦИРОВАННАЯ СХЕМА РАБОТЫ ГЕНЕТИЕЧКОГО АЛГОРИТМА
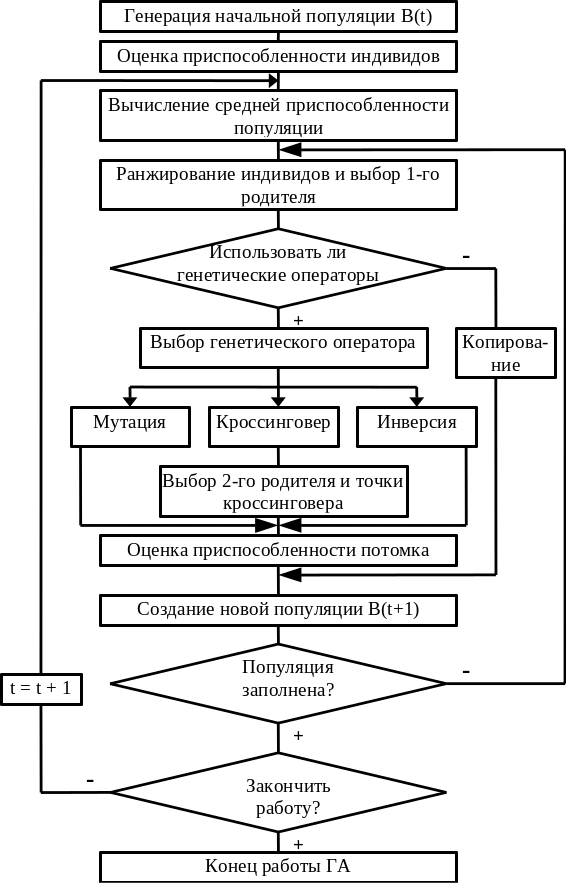
Рис. 12
1) количество поколений - влияет на продолжительность генетического поиска субоптимального решения (обычно от 100 до 1000);
2) размер популяции - влияет на разнообразие решений (размер генофонда), а следовательно на вероятность построения субоптимального решения (обычно устанавливается в пределах 50-200);
3) вероятность скрещивания - задает количество скрещиваемых пар решений в одном поколении (60-80 % общего количества пар);
4) вероятность мутации - определяет частоту генерации новой информации (1-5 % генов на одно поколение решений);
5) схему эволюционирования, микроэволюцию - развитие одной популяции или макроэволюцию - развитие нескольких популяций;
Генетические алгоритмы предназначены для поиска субоптимального решения в NP-полных задачах.
Современное состояние математического обеспечения и возможности современных ЭВМ не позволяют решать NP-полные задачи, т.е. предоставить алгоритм нахождения оптимального решения за полиномиальное время. В настоящее время оптимальное решение в такого рода задачах можно получить только путем полного перебора за экспоненциальное время.
ГА относятся к классу алгоритмов оптимизации, которые используют принцип сведения. Этот принцип заключается в том, что характерные черты субоптимальных решений используются для синтеза других субоптимальных решений.
Помимо этого, ГА обладают мощным средством выхода из локальных оптимумов - операцией мутации.
Таким образом, ГА представляет собой модель развития информации, которая позаимствована у природы, и предназначена для оптимизации технических систем.
Вообще, чем проще рассматриваемая задача, тем более неэффективным, по сравнению с традиционными методами, становится применение ГА. Так, например, для задачи, где целевая функция имеет один экстремум, применение ГА теряет смысл, поскольку любой локальный метод решит эту задачу проще и быстрее. Хотя с другой стороны, нет такой задачи, которую нельзя было бы решить с помощью ГА. На сегодняшний день в вопросе целесообразности применения ГА не существует четкой границы. И ответ на вопрос о границе разумной сложности задачи решается в основном эмпирическим путем. Например, в качестве такого критерия может быть принято условие - задача должна быть решена за одну ночь работы компьютера уровня Pentium - 100.
Таким образом, ГА представляет собой модель развития информации, которая позаимствована у природы, и предназначена для оптимизации технических систем.