

Смысл критериев различия
Некоторые результаты выборочной статистической совокупности могут далеко отстоять от среднего значения, тогда возникает сомнение, является ли это результатом маловероятных, но все же возможных больших отклонений от центра соответствующей генеральной совокупности, или же результатом того, что в рассматриваемую выборку почему-то оказались включенными результаты, принадлежащие в действительности к другой генеральной совокупности, и являются ли данные эмпирические совокупности выборками из одной и той же генеральной совокупности? Для этой цели применяется нулевая гипотеза.
Нулевая гипотеза состоит в том, что данные эмпирические совокупности являются выборками из одной и той же генеральной совокупности, если между генеральными совокупностями, выборками из которых являются данные эмпирические совокупности, нет реального различия.
Правильность нулевой гипотезы можно проверить следующим образом. Предположив справедливость нулевой гипотезы, т. е. отсутствие реального различия, мы вычисляем вероятность того, что из-за случайности выборки расхождение может достигнуть фактически наблюденной величины; если эта вероятность окажется очень малой, то нулевая гипотеза отвергается (т. е. маловероятно, что расхождение вызвано случайными причинами, а не реальным различием). Вероятность Р, которую принимают за основу при статистической оценке гипотезы, определяет уровень значимости.
Уровень значимости характеризует, в какой мере мы рискуем ошибиться, отвергая нулевую гипотезу. Этот выбор в значительной степени определяется конкретными задачами исследования. Для практических приложений вполне пригоден 5%-ный уровень значимости (95% доверительная вероятность), т. е. принимая этот уровень, мы должны отвергнуть на самом деле верную нуль-гипотезу в 5% всех случаев применения критерия значимости. Чем меньше уровень значимости, тем меньше вероятность отвергнуть проверяемую гипотезу.
Доверительный интервал. Критерий Стьюдента
При обработке данных
вычисляют приближенные значения
неизвестных величин, кото-рые в
математической статистике называются
оценками. Например, среднее значение
![]() ,
по-лученное по данным
выборки, представляет собой оценку
неизвестного математического
ожидания μ. Поэтому необходимо установить
границы, в пределах
которых с заданной ве-роятностью можно
ожидать появления
истинного значения определяемой
величины.
,
по-лученное по данным
выборки, представляет собой оценку
неизвестного математического
ожидания μ. Поэтому необходимо установить
границы, в пределах
которых с заданной ве-роятностью можно
ожидать появления
истинного значения определяемой
величины.
Чтобы дать представление о точности и надежности оценки μ в математической ста-тистике пользуются так называемыми доверительными интервалами.
При больших
n
выборочные средние
распределены
приближенно
нормально вокруг μ
со
стандартным отклонением
![]() Из рассмотрения
кривой нормального распределения мы
получаем, что около 68,3% всех выборочных
находятся в пределах
μ±
.
Из рассмотрения
кривой нормального распределения мы
получаем, что около 68,3% всех выборочных
находятся в пределах
μ±
.
Вероятность 68,3% того, что интервал ( — , + ) содержит μ, сравнительно невысока. С большей уверенностью можно утверждать, что μ покрывается интервалом ( —2 , +2 ), так как вероятность этого равна 95,5%; в том, что μ содержится в интервале ( —3 , +3 ) можно быть почти уверенным: вероятность этого равна 99,7%.
Чем выше требование к вероятности вывода об интервале, содержащем μ, тем шире должен быть интервал, который может обеспечить такую вероятность.
Относительное отклонение выборочного среднего от генерального среднего, т. е.
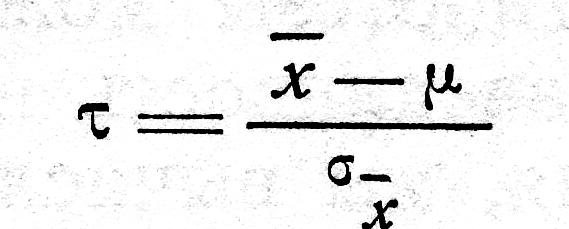
будет оцениваться величиной
.
Если же объемы выборок малы, то распределение величины t отличается от нормального и тем сильнее, чем меньше объем выборок. Тогда доля интервалов ( —t , +t ), покрывающих μ, не определяется функцией нормального распределения.
Распределение величин t при разных п (или при разном числе степеней свободы f = п—1) было найдено Стьюдентом. Значения t, обеспечивающие принятый уровень значимости, зависят не только от этого уровня, но и от объема совокупности п (или от числа степеней свободы f). Значения tР при соответствующей доверительной вероятности для разных f приводятся в таблицах критерия Стьюдента. Значения tР зависят особенно резко от f при малых f. Поэтому увеличение п приводит к сужению доверительного интервала, определяе-
мого величиной
fР
=
tРS/![]()
не только за счет уменьшения множителя 1/ , но в еще большей степени за счет уменьше-ния tР. Так, при Р = 95% изменение п с двух опытов до трех уменьшает множитель tР/ с
12,71/![]() = 9 до 4,3/
= 9 до 4,3/![]() =2,5,
т. е. доверительный интервал сужается
в 3,6 раза. При больших значениях п
увеличение п
на единицу сказывается
на ширине доверительного интервала
гораздо меньше.
=2,5,
т. е. доверительный интервал сужается
в 3,6 раза. При больших значениях п
увеличение п
на единицу сказывается
на ширине доверительного интервала
гораздо меньше.
На практике часто приходится решать задачу сравнения между собой двух средних результатов. Допустим, что на фабрику поступает сырьё из двух заготовительных пунктов. Каждый пункт опробован и результаты анализа представлены двумя рядами величин:
![]()
Необходимо выяснить, есть
ли статистически значимая разница в
содержании металла в приёмных пунктах.
Эту задачу можно решить с помощью
критерия Стьюдента, если есть основания
полагать, что имеем дело с нормально
распределенными наблюдениями и
дисперсии двух систем наблюдений
![]() и
и
![]() не отличаются значимо друг от друга.
не отличаются значимо друг от друга.
При выполнении указанных условий для проверки нулевой гипотезы μх —μу = 0 вычисляют среднее взвешенное двух дисперсий
 (3.19)
(3.19)
и величину
 (3.20)
(3.20)
Число степеней свободы здесь f=n1 + n2 — 2. Если найденное значение t по абсолютной величине не превосходит табличное значение для 5%-ного уровня значимости, то нуль-гипотеза соблюдается, и она ставится под сомнение, если найденное значение t превосходит табличное для 5%- ного уровня значимости.
В частном случае, когда n1 = n2 , выражение упрощается

В описанном выше примере были получены следующие результаты по содержанию металла:

1 пункт
2 пункт
Средневзвешенное двух дисперсий по формуле (3.19)
![]()
![]()
При f=9 по таблице критерия Стьюдента находим t0,05 = 2,26.
Таким образом, полученное значение показалось больше табличного и, следовательно, расхождение между содержанием металла в пунктах надо считать значимым.
Если нет основания считать дисперсии равными, то для сравнения двух статистических выборок при n1 = n2 можно воспользоваться приближенным t-критерием

с числом степеней свободы
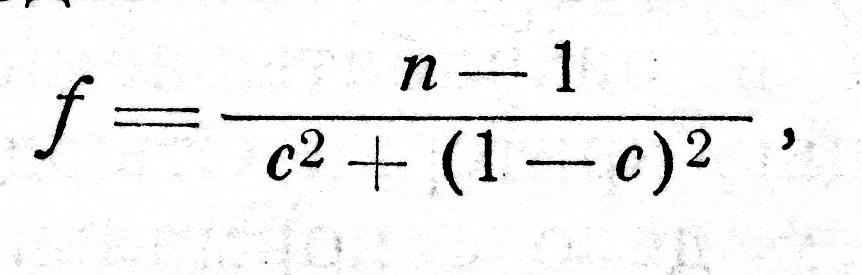
где
