

Если принятый сигнал дискретизован и Si – I-й отсчет принятого сигнала.
Сумма квадратов разностей между значениями принятого сигнала Si и символами k-го кодового слова называется невязкой, или евклидовым расстоянием между этим кодовым словом и принятым сигналом.
Если помех в канале связи нет или они невелики, то при передаче l-го кодового слова принятый сигнал S будет совпадать с этим кодовым словом или незначительно отличаться от него. Тогда невязка будет равна нулю или минимальна именно для l = k.
Таким образом, оптимальный декодер должен вычислить евклидовы расстояния между принятым сигналом S и всеми возможными кодовыми словами Uk данного кода и принять решение в пользу кодового слова Ul , минимизирующего dl 2 , то есть наиболее похожего на принятый сигнал.
Структурная схема декодера максимального правдоподобия, реализующего правило декодирования (1.33) – (1.34), приведена на рис. 1.8.
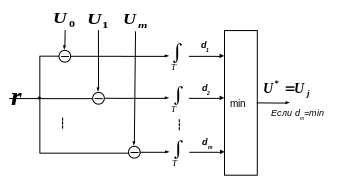
Рис. 1.8
Рассмотренный нами оптимальный декодер является так называемым мягким декодером, поскольку он выносит решения относительно Ul непосредственно на основе принятого сигнала.
На практике чаще применяется так называемое жесткое декодирование, когда в приемнике сначала принимается решение относительно значения символов принятой последовательности, а уже затем – относительно значения кодового слова.
В этом случае оптимальный декодер (жесткий декодер максимального правдоподобия) должен вычислить расстояния
d*k = { rl - Uk }2 (1.35)
между принятой последовательностью r и всеми возможными кодовыми словами Uk данного кода и принять решение в пользу кодового слова, в минимальной степени отличающегося от принятой последовательности.
Таким образом, при жестком декодировании максимального правдоподобия по принятому сигналу сначала определяются символы принятой последовательности r , а потом эта последовательность поочередно сравнивается со всеми кодовыми словами данного кода. Решение принимается в пользу кодового слова, максимально похожего на принятую последовательность.
Поскольку в процессе мягкого декодирования информация о сигнале учитывается в большей мере (решение принимается по всему сигналу сразу, а не по частям, для каждого символа в отдельности, и только потом - для всей принятой последовательности), то качество мягкого декодирования должно быть, по идее, выше. Однако реализация жесткого декодера является гораздо более простой – действия выполняются над нулями и единицами. Поэтому такие декодеры используются чаще, хотя и несколько проигрывают мягким декодерам в вероятности правильного декодирования.
В заключение нужно сказать, что при декодировании блочных кодов декодеры максимального правдоподобия применяются достаточно редко из-за их сложности при больших размерах кода. Правда, при современных мощностях микропроцессорных устройств это уже не представляет непреодолимой трудности. Скорее, нужно выбирать между усложнением алгоритма декодирования и выигрышем в повышении вероятности правильного декодирования.
Для сверточных же кодов декодирование с использованием метода максимального правдоподобия – стек-алгоритм, алгоритм Фано и алгоритм Витерби - это основные способы декодирования.