

Тема 3. Линейные регрессионные модели с переменной структурой.
При изучении социально-экономических процессов и явлений может оказаться необходимым включить в модель фактор, имеющий два или более качественных уровня, например, образование, пол, фактор сезонности. Качественные признаки могут существенно влиять на структуру линейных связей между переменными и приводить к скачкообразному изменению параметров регрессионной модели. В этом случае говорят об исследовании регрессионных моделей с переменной структурой или построении регрессионных моделей по неоднородным данным.
Оценить влияние значений количественных переменных и уровней качественных признаков с помощью одного уравнения регрессии можно путем введения фиктивных переменных.
В качестве фиктивных переменных обычно используются дихотомические (бинарные) переменные, которые принимают всего два значения: «0» и «1». Например, при исследовании зависимости заработной платы от уровня образования Z можно рассмотреть k=3 уровня: начальное образование, среднее и высшее. Обычно вводят (k-1) бинарную переменную. В нашем случае потребуется ввести две фиктивные переменные.
Тогда регрессионная модель запишется в виде:
y= b0 + b1∙x1 + … + bm∙xm + bm+1∙z1 + bm+2∙z2 +ε,
где ![]()
![]()
x1, …,∙xn – экономические (количественные) переменные.
Наличие у работника начального образования будет отражено парой значений z1=0, z2=0.
Параметры при фиктивных переменных z1 и z2 представляют собой разность между средним уровнем результативного признака для соответствующей группы и базовой группы (в нашем примере это работники с начальным образованием).
При построении регрессионных моделей по неоднородным данным необходимо выяснить, действительно ли две выборки однородны в регрессионном смысле, можно ли объединить их в одну и рассматривать единую модель регрессии?
Для ответа на этот вопрос можно воспользоваться тестом Г.Чоу.
По каждой выборке строятся две линейные регрессионные модели:

Проверяемая нулевая гипотеза имеет вид – H0: b'=b''; D(ε')= D(ε'')= σ2.
Если нулевая гипотеза верна, то две регрессионные модели можно объединить в одну объема n = n1 + n2.
Согласно критерию Г.Чоу нулевая гипотеза H0 отвергается на уровне значимости α, если статистика
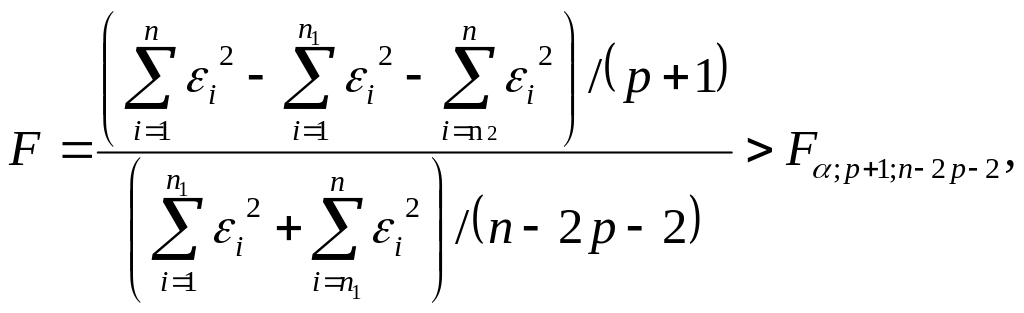
где
 - остаточные суммы квадратов соответственно
для объединенной, первой и второй
выборок, n
= n1
+ n2.
- остаточные суммы квадратов соответственно
для объединенной, первой и второй
выборок, n
= n1
+ n2.
Для проверки гипотезы о структурной стабильности тенденции изучаемого временного ряда можно использовать тест Д.Гуйарати.
Пример 4. Рассмотрим полученную в примере 1 модель зависимости балансовой прибыли предприятия торговли (тыс. руб.) от следующих переменных:
- фонд оплаты труда, тыс. руб.; - объем продаж по безналичному расчету, тыс. руб.
Известно, что первая выборка значений переменных объемом n1=12 получена при одних условиях, а другая, объемом n2=12, - при несколько измененных условиях.
Задание: Проверить, адекватно ли предположение об однородности исходных данных в регрессионном смысле. Можно ли объединить две выборки в одну и рассматривать единую модель регрессии по ?
Решение.
Для проверки предположения об однородности исходных данных в регрессионном смысле применим тест Чоу.
В соответствии со схемой теста построим уравнения регрессии по первым n1=12 наблюдениям. Результаты представлены в таблице 8.
Таблица 8
Дисперсионный анализ |
|
|
|
|
|
|
df |
SS |
MS |
F |
Значимость F |
Регрессия |
2 |
1,02E+09 |
5,1E+08 |
11,9033 |
0,002967 |
Остаток |
9 |
ESS1 = = 3,85E+08 |
4,3Е+07 |
|
|
Итого |
11 |
1,40E+09 |
|
|
|
Результаты дисперсионного анализа модели, построенной по оставшимся n2=12 наблюдениям, представлены в таблице 9.
Таблица 9
Дисперсионный анализ |
|
|
|
|
|
|
df |
SS |
MS |
F |
Значимость F |
Регрессия |
2 |
1,87Е+09 |
9,33E+08 |
57,1758 |
7,6549E-06 |
Остаток |
9 |
ESS2 = = 1,47E+08 |
1,63Е+07 |
|
|
Итого |
11 |
2,01E+09 |
|
|
|
Результаты регрессионного и дисперсионного анализа модели, построенной по всем n = n1 + n2 = 24 наблюдениям, представлены в таблице 3 (ESS = 6,39Е+08):
Рассчитаем статистику F по формуле:
![]() .
.
Находим табличное значение Fтабл= FРАСПОБР(0,05;3;18) = 3,15.
Так как, Fрасч< Fтабл, то справедлива гипотеза , т.е. надо использовать единую модель по всем наблюдениям.