

2. Инициализация массивов
Как и простые переменные, массивы могут быть инициализированы при объявлении. Инициализатор для объектов составных типов (каким является массив) состоит из списка инициализаторов, разделенных запятыми и заключенных в фигурные скобки. Каждый инициализатор в списке представляет собой либо константу соответствующего типа, либо, в свою очередь, список инициализаторов. Эта конструкция используется для инициализации многомерных массивов.
Наличие списка инициализаторов в объявлении массива позволяет не указывать число элементов по его первой размерности. В этом случае количество элементов в списке инициализаторов и определяет число элементов по первой размерности массива. Тем самым определяется размер памяти, необходимой для хранения массива. Число элементов по остальным размерностям массива, кроме первой, указывать обязательно.
Если в списке инициализаторов меньше элементов, чем в массиве, то оставшиеся элементы неявно инициализируются нулевыми значениями. Если же число инициализаторов больше, чем требуется, то выдается сообщение об ошибке.
Примеры инициализации массивов int a[3] = {0, 1, 2}; // Число инициализаторов равно числу элементов
double b[5] = {0.1, 0.2, 0.3}; // Число инициализаторов меньше числа элементов
int c[ ] = {1, 2, 4, 8, 16}; // Число элементов массива определяется по числу инициализаторов
int d[2][3] = {{0, 1, 2},
{3, 4, 5}}; // Инициализация двумерного массива. Массив состоит из двух строк,
// в каждой из которых по 3 элемента. Элементы первой строки получают значения 0, 1 и 2,
// а второй – значения 3, 4 и 5.
int e[3] = {0, 1, 2, 3}; // Ошибка – число инициализаторов больше числа элементов
Обратите внимание, что не существует присваивания массиву, соответствующего описанному выше способу инициализации.
int a[3] = {0, 1, 2}; // Объявление и инициализация
a = {0, 1, 2}; // Ошибка
13. Логические операции и операции присваивания в языке С++.
Операция присваивания
Присваивание – это тоже операция, она является частью выражения. Значение правого операнда присваивается левому операнду.
x = 2; // переменной x присвоить значение 2
cond = x < 2; // переменной cond присвоить значение true, если x меньше 2,
// в противном случае присвоить значение false
3 = 5; // ошибка, число 3 неспособно изменять свое значение
Последний пример иллюстрирует требование к левому операнду операции присваивания. Он должен быть способен хранить и изменять свое значение. Переменные, объявленные в программе, обладают подобным свойством. В следующем фрагменте программы
int x = 0;
x = 3;
x = 4;
x = x + 1;
вначале объявляется переменная x с начальным значением 0. После этого значение x изменяется на 3, 4 и затем 5. Опять-таки, обратим внимание на последнюю строчку. При вычислении операции присваивания сначала вычисляется правый операнд, а затем левый. Когда вычисляется выражение x + 1, значение переменной x равно 4. Поэтому значение выражения x + 1 равно 5. После вычисления операции присваивания (или, проще говоря, после присваивания ) значение переменной x становится равным 5.
У операции присваивания тоже есть результат. Он равен значению левого операнда. Таким образом, операция присваивания может участвовать в более сложном выражении:
z = (x = y + 3);
В приведенном примере переменным x и z присваивается значение y + 3.
Очень часто в программе приходится значение переменной увеличивать или уменьшать на единицу. Для того чтобы сделать эти действия наиболее эффективными и удобными для использования, применяются предусмотренные в Си++ специальные знаки операций: ++ (увеличить на единицу) и -- (уменьшить на единицу). Существует две формы этих операций: префиксная и постфиксная. Рассмотрим их на примерах.
int x = 0;
++x;
Значение x увеличивается на единицу и становится равным 1.
--x;
Значение x уменьшается на единицу и становится равным 0.
int y = ++x;
Значение x опять увеличивается на единицу. Результат операции ++ – новое значение x, т.е. переменной y присваивается значение 1.
int z = x++;
Здесь используется постфиксная запись операции увеличения на единицу. Значение переменной x до выполнения операции равно 1. Сама операция та же – значение x увеличивается на единицу и становится равным 2. Однако результат постфиксной операции – это значение аргумента до увеличения. Таким образом, переменной z присваивается значение 1. Аналогично, результатом постфиксной операции уменьшения на единицу является начальное значение операнда, а префиксной – его конечное значение.
Подобными мотивами оптимизации и сокращения записи руководствовались создатели языка Си (а затем и Си++), когда вводили новые знаки операций типа "выполнить операцию и присвоить". Довольно часто одна и та же переменная используется в левой и правой части операции присваивания, например:
x = x + 5;
y = y * 3;
z = z – (x + y);
В Си++ эти выражения можно записать короче:
x += 5;
y *= 3;
z -= x + y;
Т.е. запись oper= означает, что левый операнд вначале используется как левый операнд операции oper, а затем как левый операнд операции присваивания результата операции oper. Кроме краткости выражения, такая запись облегчает оптимизацию программы компилятором.
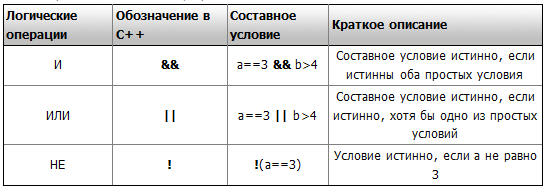
Логические операций
В С++ существует три логические операции:
1) Логическая операция И "&&", нам уже известная;
2) Логическая операция ИЛИ "||";
3) Логическая операция НЕ "!" или логическое отрицание.
Логические операции образуют сложное (составное) условие из нескольких простых (два или более) условий. Эти операции упрощают структуру программного кода в несколько раз. Да, можно обойтись и без них, но тогда количество ифов увеличивается в несколько раз, в зависимости от условия. В следующей таблице кратко охарактеризованы все логические операции в языке программирования С++, для построения логических условий.
14. Вычисление размерности данных и массивов в байтах.
Вам уже известен оператор sizeof, возвращающий размер указанного операнда в байтах. Этот оператор можно использовать с переменными любых типов, за исключением битовых полей. Часто оператор sizeof применяют, чтобы определить размер переменной, тип которой в разных системах может иметь разную размерность. Как говорилось выше, в одном случае для представления целочисленного значения отводится 2 байта, в другом — 4 байта.
Поэтому, например, при работе с массивами, размещаемыми в памяти динамически, необходимо точно знать, сколько памяти запрашивать у операционной системы. Следующая программа автоматически вычислит и отобразит на экране число байтов, занимаемых массивом из семи целочисленных элементов:
/*
* sizeof.с
* Эта программа на языке С демонстрирует использование
* оператора sizeofдля определения физического размера массива.
*/
#include ‹stdio.h›
#define iDAY_OF_WEEK 7
main () { int iweek[iDAY_OF_WEEK] = (1,2, 3, 4, 5, 6, 7} ;
printf("Массив iweek занимает%d байт.\n",(int) sizeof(iweek));
return(0);. }
Вы можете спросить, почему значение, возвращаемое оператором sizeof, приводится к типу int. Дело в том, что в соответствии со стандартом ANSI данный оператор возвращает значение типа size_t, поскольку в некоторых системах одного лишь типа int оказывается недостаточно для представления размерностей данных некоторых типов. В нашем примере операция приведения необходима также для того, чтобы выводимое число соответствовало спецификации %d функции printf().
С помощью следующей программы можно проследить, как размещаются в памяти элементы массива iarray.
/*
* array.с
* Этa программа на языке С позволяет убедиться
* в смежном размещении в памяти элементов массива.
*/
#include ‹stdio.h›
#define iDAYS 7 main () { int index, iarray[iDAYS];
printf("sizeof(int)= %d\n\n",(int)sizeof(int));
for(index = 0;
index < iDAYS;
index++) printf("siarray[%d]= %X\n",index, &iarray[index]);
return(0); }
Запустив программу, вы получите примерно следующий результат:
sizeof(int)= 4 &iarray[0]= 64FDDC Siarrayfl] = 64FDEO &iarray[2]= 64FDE4 &iarray[3]= 64FDE8 Siarray[4]= 64FDEC Siarray[5]= 64FDFO &iarray[6]= 64FDF4
Обратите внимание на то, что оператор взятия адреса & можно применять к любым переменным, в том числе к элементам массива. Над элементом массива можно выполнять те же операции, что и над любой другой переменной, использовать его в выражениях, присваивать значения и передавать в качестве аргумента функциям. В рассматриваемом примере по отображаемым адресам можно убедиться, что на каждый элемент действительно отводится 4 байта памяти. Ниже показан аналог этой же программы на языке C++:
//
// array.срр
// Это версия предыдущей программы на языке C++.
//
#include ‹iostream.h›
#define iDAYS 7 main () { int index, iarray[iDAYS];
cout << "sizeof (int) = " << (int)sizeof(int) << "\n\n";
for(index = 0; index < iDAYS; index++)
cout << "siarray["<< index << "] = " << &iarray[index] << "\n";
return(0); }
15.
В языке программирования С++ существует два оператора выбора:
1)Оператор выбора if
2) Оператор выбора switch
Операторы выбора позволяют принять программе решение, основываясь на истинности или ложности условия. Если условие истинно (т. е. равно true) значит, оператор в теле if выполняется, после чего выполняется следующий по порядку оператор. Если условие ложно (т. е. равно false) значит, оператор в теле if не выполняется (игнорируется или пропускается) и сразу же выполняется следующий по порядку оператор. Проверяемое условие может быть любым логическим выражением. Логические выражения могут быть образованы операциями равенства и отношения

Очень частой ошибкой программирования является неправильная запись операций равенства и соотношений. Пробелов между знаками ==; !=; >=; <=; быть не должно. Также необходимо помнить правильную последовательность записи символов операций равенства и отношений.
Пример:
"=!" не правильно; "!=" правильная запись
"=>" не правильно; ">=" правильная запись
"=<" не правильно; "<=" правильная запись
Нельзя путать операцию = (операция присваивания) и операцию == (операция равенства) так как это приводит к логическим ошибкам, т. е. программа даже скомпилируется без всяких ошибок, но работать будет не правильно.
Условный оператор или оператор выбора if записывается в двух формах, рассмотрим первую.
if (/*проверяемое условие*/)
{
//тело условного оператора
}
Фигурные скобочки тела условного оператора можно опускать, если при истинности условия необходимо выполнить один оператор. Пример:
if (/*проверяемое условие*/)
/*оператор1*/;
Чтобы в будущем не путаться рекомендую всегда прописывать фигурные скобочки, так код будет более понятен.
Рассмотрим простейший пример использования оператора выбора if. Условие задачи: даны два числа, необходимо их сравнить.
// in_out.cpp: определяет точку входа для консольного приложения.
#include "stdafx.h"
#include <iostream>
using namespace std;
int main()
{
int a, b; // объявление переменных типа int, то есть в таких переменных хранятся только целые числа
cout << "Vvedite pervoe chislo: ";
cin >> a;
cout << "Vvedite vtoroe chislo: ";
cin >> b;
if (a > b) // если а > b
{
cout << a << " > " << b << endl; // печатать данное сообщение
}
if (a < b)// если а < b
{
cout << a << " < " << b << endl;
}
if (a == b) // если а = b
cout << a << " = " << b << endl; // в теле условного оператора опущены фигурные скобочки
system("pause");
return 0;
}
В некоторых источниках говорится, что оператор выбора if else - самостоятельный оператор. Но это не так, if else - это всего лишь форма записи оператора выбора if. Оператор выбора if else позволяет определить программисту действие, когда условие истинно и альтернативное действие, когда условие ложно. Тогда как оператор выбора if позволял определить действие при истинном условии.
Синтаксис оператора выбора if else:
if (/*проверяемое условие*/)
{
/*тело оператора выбора 1*/;
} else
{
/*тело оператора выбора 2*/;
}
Читается так: "Если проверяемое условие истинно, то выполняется тело оператора выбора 1, иначе (то есть проверяемое условие ложно) выполняется тело оператора выбора 2". Обратите внимание на то, как записан оператор выбора if else. Слово else специально сдвинуто вправо для того чтобы программный код был понятен и его было удобно читать.
Рассмотрим задачу с предыдущей темы, с использованием if else. Напомню условие задачи: "Даны два числа, необходимо их сравнить".
// if_else.cpp: определяет точку входа для консольного приложения.
#include "stdafx.h"
#include <iostream>
using namespace std;
int main(int argc, char* argv[])
{
int a, b;
cout << "Vvedite pervoe chislo: ";
cin >> a;
cout << "Vvedite vtoroe chislo: ";
cin >> b;
if ( a >= b) // если a больше либо равно b, то
{
cout << a << " >= " << b << endl;
} else // иначе
{
cout << a << " <= " << b << endl;
}
system("pause");
return 0;
}
Оператор выбора switch
Этот оператор позволяет передать управление одному из нескольких помеченных метками операторов в зависимости от значения целочисленного выражения. Метки оператора switch имеют специальный вид:
case целая_константа:
Вид оператора switch:
switch (целое_выражение ){
[объявления]
[case константное_целое_выражение1:]
. . .
[case константное_целое_выражение2: ]
[операторы]
. . .
[case константное_целое_выражение m:]
. . .
[case константное_целое_выражение n:]
[операторы]
[default:] [операторы] }
Здесь [ ] означают необязательную часть оператора, а ... говорит о том, что указанная конструкция может применяться сколько угодно раз. Блок после switch( ) называют телом оператора switch.
Схема выполнения оператора:
Сначала вычисляется выражение в круглых скобках (назовем его селектором).
Затем вычисленное значение селектора последовательно сравнивается с константным выражением, следующим за case.
Если селектор равен какому-либо константному выражению, стоящему за case, то управление передается оператору, помеченному соответствующим оператором case.
Если селектор не совпадает ни с одной меткой варианта, то управление передается на оператор, помеченный словом default.
Если default отсутствует, то управление передается следующему за switch оператору.
Отметим, что после передачи управления по какой-либо одной из меток дальнейшие операторы выполняются подряд. Поэтому, если необходимо выполнить только часть из них, нужно позаботиться о выходе из switch. Это обычно делается с помощью оператора break, который осуществляет немедленный выход из тела оператора switch.
Пример 1:
int i, d;
cout<<"Задайте целое значение i\n";
cin>>i;
switch ( i ){
case 1: case2: case3: cout<<" i="<< i <<"\n";
case 4: cout<<" i="<< i <<" i^2= "<< i*i<<"\n";
d=3*i - 4; cout<<" d=" << d <<".\n";
break;
case 5: cout<<"i=5.\n"; break;
default: cout<<" Значение i меньше 1 или больше 5.\n";
}
17. Целый тип данных в языке С++.
Типы данных
Все типы данных можно разделить на две категории: скалярные и составные.
Ключевыми словами, используемыми при объявлении основных типов данных, являются:
Для целых типов:
char, int, short, long, signed, unsigned;
Для плавающих типов:
float, double, long double;
Для классов:
struct, union, class;
Для перечисления:
enum;
Для типа void:
void (пустой).
Целые типы данных
Тип char, или символьный
Данными типа char являются различные символы, причем значением этих символов является численное значение во внутренней кодировке ЭВМ.
Символьная константа - это символ, заключенный в апострофы, например: '&', '4', '@', 'а'. Символ '0', например, имеет в кодировке ASCII значение 48.
Существуют две модификации этого типа: signed char и unsigned char.
Данные char занимают один байт и меняются в диапазоне:
signed char (или просто char) -128 .. 127;
unsigned char 0 .. 255.
Отметим, что если необходимо иметь дело с переменными, принимающими значения русских букв, то их тип должен быть unsigned char, т.к. коды русских букв >127 (B кодировке ASCII).
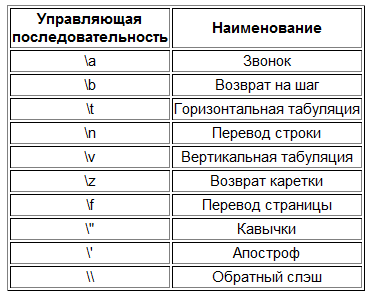
Символы, в том числе и неграфические, могут быть представлены как символьные константы с помощью т.н. управляющих последовательностей.
Управляющая последовательность - это специальные символьные комбинации, которые начинаются с \ , за которым следует буква или комбинация цифр (см. табл. 2).
Последовательности '\ddd' и '\xddd' позволяют представлять любой символ из набора ЭВМ как последовательность восьмеричных или шестнадцатеричных цифр соответственно. Например, символ возврата каретки можно задать так: '\r' или '\015' или 'x00D'.
Тип int (эквивалент short int)
Данные типа int занимают 2 байта и принимают целые значения из диапазона: -32768 . . 32767.
Тип unsigned int
Данные такого типа занимают 2 байта, их диапазон: 0 . . 65535.
Тип long (long int)
Такие данные занимают 4 байта и изменяются в диапазоне 0 . . 4 298 876 555.
Отметим, что если целая константа выходит из диапазона int, то она автоматически становится константой типа long или даже unsigned long.
Так, 32768 имеет тип long, 2676768999 имеет тип unsigned long.
Задать тип константы можно и явно с помощью суффиксов 'U' и 'L':
-6L 6U 33UL.
В самом стандарте языка определено лишь, что sizeof (char)=1 и sizeof (char)<=sizeof (short)<=sizeof (int)<= sizeof (long).
Здесь sizeof (type)- операция, определяющая размер типа type в байтах.
Целая константа, которая начинается с нуля, является восьмеричной константой, а начинающаяся символами 0x - шестнадцатеричной константой, например

18. Инструкции присваивания. Выражения.
Выражения
Программа оперирует с данными. Числа можно складывать, вычитать, умножать, делить. Из разных величин можно составлять выражения, результат вычисления которых – новая величина. Приведем примеры выражений:
X * 12 + Y // значение X умножить на 12 и к результату прибавить значение Y
val < 3 // сравнить значение val с 3
-9 // константное выражение -9
Выражение, после которого стоит точка с запятой – это оператор-выражение. Его смысл состоит в том, что компьютер должен выполнить все действия, записанные в данном выражении, иначе говоря, вычислить выражение.
x + y – 12; // сложить значения x и y и затем вычесть 12
a = b + 1; // прибавить единицу к значению b и запомнить результат в переменной a
Выражения – это переменные, функции и константы, называемые операндами, объединенные знаками операций. Операции могут быть унарными – с одним операндом, например, минус; могут быть бинарные – с двумя операндами, например сложение или деление. В Си++ есть даже одна операция с тремя операндами – условное выражение. Чуть позже мы приведем список всех операций языка Си++ для встроенных типов данных. Подробно каждая операция будет разбираться при описании соответствующего типа данных. Кроме того, ряд операций будет рассмотрен в разделе, посвященном определению операторов для классов. Пока что мы ограничимся лишь общим описанием способов записи выражений.
В типизированном языке, которым является Си++, у переменных и констант есть определенный тип. Есть он и у результата выражения. Например, операции сложения ( + ), умножения ( * ), вычитания ( - ) и деления ( / ), примененные к целым числам, выполняются по общепринятым математическим правилам и дают в результате целое значение. Те же операции можно применить к вещественным числам и получить вещественное значение.
Операции сравнения: больше ( > ), меньше ( < ), равно ( == ), не равно ( != ) сравнивают значения чисел и выдают логическое значение: истина ( true ) или ложь ( false ).
Операция присваивания
Присваивание – это тоже операция, она является частью выражения. Значение правого операнда присваивается левому операнду.
x = 2; // переменной x присвоить значение 2
cond = x < 2; // переменной cond присвоить значение true, если x меньше 2,
// в противном случае присвоить значение false
3 = 5; // ошибка, число 3 неспособно изменять свое значение
Последний пример иллюстрирует требование к левому операнду операции присваивания. Он должен быть способен хранить и изменять свое значение. Переменные, объявленные в программе, обладают подобным свойством. В следующем фрагменте программы
int x = 0;
x = 3;
x = 4;
x = x + 1;
вначале объявляется переменная x с начальным значением 0. После этого значение x изменяется на 3, 4 и затем 5. Опять-таки, обратим внимание на последнюю строчку. При вычислении операции присваивания сначала вычисляется правый операнд, а затем левый. Когда вычисляется выражение x + 1, значение переменной x равно 4. Поэтому значение выражения x + 1 равно 5. После вычисления операции присваивания (или, проще говоря, после присваивания ) значение переменной x становится равным 5.
У операции присваивания тоже есть результат. Он равен значению левого операнда. Таким образом, операция присваивания может участвовать в более сложном выражении:
z = (x = y + 3);
В приведенном примере переменным x и z присваивается значение y + 3.
Очень часто в программе приходится значение переменной увеличивать или уменьшать на единицу. Для того чтобы сделать эти действия наиболее эффективными и удобными для использования, применяются предусмотренные в Си++ специальные знаки операций: ++ (увеличить на единицу) и -- (уменьшить на единицу). Существует две формы этих операций: префиксная и постфиксная. Рассмотрим их на примерах.
int x = 0;
++x;
Значение x увеличивается на единицу и становится равным 1.
--x;
Значение x уменьшается на единицу и становится равным 0.
int y = ++x;
Значение x опять увеличивается на единицу. Результат операции ++ – новое значение x, т.е. переменной y присваивается значение 1.
int z = x++;
Здесь используется постфиксная запись операции увеличения на единицу. Значение переменной x до выполнения операции равно 1. Сама операция та же – значение x увеличивается на единицу и становится равным 2. Однако результат постфиксной операции – это значение аргумента до увеличения. Таким образом, переменной z присваивается значение 1. Аналогично, результатом постфиксной операции уменьшения на единицу является начальное значение операнда, а префиксной – его конечное значение.
Подобными мотивами оптимизации и сокращения записи руководствовались создатели языка Си (а затем и Си++), когда вводили новые знаки операций типа "выполнить операцию и присвоить". Довольно часто одна и та же переменная используется в левой и правой части операции присваивания, например:
x = x + 5;
y = y * 3;
z = z – (x + y);
В Си++ эти выражения можно записать короче:
x += 5;
y *= 3;
z -= x + y;
Т.е. запись oper= означает, что левый операнд вначале используется как левый операнд операции oper, а затем как левый операнд операции присваивания результата операции oper. Кроме краткости выражения, такая запись облегчает оптимизацию программы компилятором.
Порядок вычисления выражений
У каждой операции имеется приоритет. Если в выражении несколько операций, то первой будет выполнена операция с более высоким приоритетом. Если же операции одного и того же приоритета, они выполняются слева направо.
Например, в выражении
2 + 3 * 6
сначала будет выполнено умножение, а затем сложение ;соответственно, значение этого выражения — число 20.
В выражении
2 * 3 + 4 * 5
сначала будет выполнено умножение, а затем сложение. В каком порядке будет производиться умножение – сначала 2 * 3, а затем 4 * 5 или наоборот, не определено. Т.е. для операции сложения порядок вычисления ее операндов не задан.
В выражении
x = y + 3
вначале выполняется сложение, а затем присваивание, поскольку приоритет операции присваивания ниже, чем приоритет операции сложения.
Для данного правила существует исключение: если в выражении несколько операций присваивания, то они выполняются справа налево. Например, в выражении
x = y = 2
сначала будет выполнена операция присваивания значения 2 переменной y. Затем результат этой операции – значение 2 – присваивается переменной x.
Ниже приведен список всех операций в порядке понижения приоритета. Операции с одинаковым приоритетом выполняются слева направо (за исключением нескольких операций присваивания ).
:: (разрешение области видимости имен)
. (обращение к элементу класса), -> (обращение к элементу класса по указателю), [] (индексирование), вызов функции, ++ (постфиксное увеличение на единицу), -- (постфиксное уменьшение на единицу), typeid (нахождение типа), dynamic_cast static_cast reinterpret_cast const_cast (преобразования типа)
sizeof (определение размера), ++ (префиксное увеличение на единицу), -- (префиксное уменьшение на единицу), ~ (битовое НЕ), ! (логическое НЕ), – (изменение знака), + (плюс), & (взятие адреса), * (обращение по адресу), new (создание объекта), delete (удаление объекта), (type) (преобразование типа)
.*, ->* (обращение по указателю на элемент класса)
* ( умножение ), / ( деление ), % ( остаток )
+ ( сложение ), – ( вычитание )
<< , >> ( сдвиг )
< <= > >= ( сравнения на больше или меньше)
== != (равно, неравно)
& (поразрядное И)
^ (поразрядное исключающее ИЛИ)
| (поразрядное ИЛИ)
&& (логическое И)
|| (логическое ИЛИ)
= ( присваивание ), *= /= %= += -= <<= >>= &= |= ^= (выполнить операцию и присвоить)
?: (условная операция)
, ( последовательность )
Для того чтобы изменить последовательность вычисления выражений, можно воспользоваться круглыми скобками. Часть выражения, заключенная в скобки, вычисляется в первую очередь. Значением
(2 + 3) * 6
будет 30.
Скобки могут быть вложенными, соответственно, самые внутренние выполняются первыми:
(2 + (3 * (4 + 5) ) – 2)
19. Типы данных в языке С++.
Основные типы данных в C++
Основные (стандартные) типы данных часто называют арифметическими, поскольку их можно использовать в арифметических операциях. Для описания основных типов определены следующие ключевые слова:
int (целый);
char (символьный);
wchar_t (расширенный символьный);
bool (логический);
float (вещественный);
double (вещественный с двойной точностью).
Первые четыре тина называют целочисленными (целыми), последние два — типами с плавающей точкой. Код, который формирует компилятор для обработки целых величин, отличается от кода для величин с плавающей точкой.
Существует четыре спецификатора типа, уточняющих внутреннее представление и диапазон значений стандартных типов:
short (короткий);
long (длинный);
signed (знаковый);
unsigned (беззнаковый).
Целый тип (int)
Размер типа int не определяется стандартом, а зависит от компьютера и компилятора. Для 16-разрядного процессора под величины этого типа отводится 2 байта, для 32-разрядного — 4 байта.
Спецификатор short перед именем типа указывает компилятору, что под число требуется отвести 2 байта независимо от разрядности процессора. Спецификатор long означает, что целая величина будет занимать 4 байта. Таким образом, на 16-разрядном компьютере эквиваленты int и short int, а на 32-разрядном — int и long int.
Внутреннее представление величины целого типа — целое число в двоичном коде. При использовании спецификатора signed старший бит числа интерпретируется как знаковый (0 — положительное число, 1 — отрицательное). Спецификатор unsigned позволяет представлять только положительные числа, поскольку старший разряд рассматривается как часть кода числа. Таким образом, диапазон значений типа int зависит от спецификаторов. Диапазоны значений величин целого типа с различными спецификаторами для IBM PC-совместимых компьютеров приведены в таблице «Диапазоны значений простых типов данных» в конце записи.
По умолчанию все целочисленные типы считаются знаковыми, то есть спецификатор signed можно опускать.
Константам, встречающимся в программе, приписывается тот или иной тип в соответствии с их видом. Если этот тип по каким-либо причинам не устраивает программиста, он может явно указать требуемый тип с помощью суффиксов L, l (long) и U, u (unsigned). Например, константа 32L будет иметь тип long и занимать 4 байта. Можно использовать суффиксы L и U одновременно, например, 0x22UL или 05Lu.
Примечание
Типы short int, long int, signed int и unsigned int можно сокращать до short, long, signed и unsigned соответственно.
Символьный тип (char)
Под величину символьного типа отводится количество байт, достаточное для размещения любого символа из набора символов для данного компьютера, что и обусловило название типа. Как правило, это 1 байт. Тип char, как и другие целые типы, может быть со знаком или без знака. В величинах со знаком можно хранить значения в диапазоне от -128 до 127. При использовании спецификатора unsigned значения могут находиться в пределах от О до 255. Этого достаточно для хранения любого символа из 256-символьного набора ASCII. Величины типа char применяются также для хранения целых чисел, не превышающих границы указанных диапазонов.
Расширенный символьный тип (wchar_t)
Тип wchar_t предназначен для работы с набором символов, для кодировки которых недостаточно 1 байта, например, Unicode. Размер этого типа зависит от реализации; как правило, он соответствует типу short. Строковые константы типа wchar_t записываются с префиксом L, например, L»Gates».
Логический тип (bool)
Величины логического типа могут принимать только значения true и false, являющиеся зарезервированными словами. Внутренняя форма представления значения false — 0 (нуль). Любое другое значение интерпретируется как true. При преобразовании к целому типу true имеет значение 1.
Типы с плавающей точкой (float, double и long double)
Стандарт C++ определяет три типа данных для хранения вещественных значений: float, double и long double.
Типы данных с плавающей точкой хранятся в памяти компьютера иначе, чем целочисленные. Внутреннее представление вещественного числа состоит из двух частей — мантиссы и порядка. В IBM PC-совместимых компьютерах величины типа float занимают 4 байта, из которых один двоичный разряд отводится под знак мантиссы, 8 разрядов под порядок и 23 под мантиссу. Мантисса — это число, большее 1.0, но меньшее 2.0. Поскольку старшая цифра мантиссы всегда равна 1, она не хранится.
Для величин типа double, занимающих 8 байт, под порядок и мантиссу отводится 11 и 52 разряда соответственно. Длина мантиссы определяет точность числа, а длина порядка — его диапазон. Как можно видеть из таблицы в конце записи, при одинаковом количестве байт, отводимом под величины типа float и long int, диапазоны их допустимых значений сильно различаются из-за внутренней формы представления.
Спецификатор long перед именем типа double указывает, что под его величину отводится 10 байт.
Константы с плавающей точкой имеют по умолчанию тип double. Можно явно указать тип константы с помощью суффиксов F, f (float) и L, l (long). Например, константа 2E+6L будет иметь тип long double, а константа 1.82f — тип float.
Для написания переносимых на различные платформы программ нельзя делать предположений о размере типа int. Для его получения необходимо пользоваться операцией sizeof, результатом которой является размер типа в байтах. Например, для операционной системы MS-DOS sizeof (int) даст в результате 2, а для Windows 98 или OS/2 результатом будет 4.
В стандарте ANSI диапазоны значений для основных типов не задаются, определяются только соотношения между их размерами, например:
slzeof(float) ? slzeof(double) ? sizeof(long double)
sizeof(char) ? slzeof(short) ? sizeof(int) ? sizeof(long)
Примечание
Минимальные и максимальные допустимые значения для целых типов зависят от реализации и приведены в заголовочном файле <limits.h> (<climits>), характеристики вещественных типов — в файле <float.h> (<cfloat>), а также в шаблоне класса numeric_limits
Тип void
Кроме перечисленных, к основным типам языка относится тип void, но множество значений этого типа пусто. Он используется для определения функций, которые не возвращают значения, для указания пустого списка аргументов функции, как базовый тип для указателей и в операции приведения типов