

1.4. Контрольные вопросы и задания
Приведите примеры применения вариационной статистики в лесном хозяйстве.
Дайте определения и поясните суть следующих терминов:
переменная;
случайная величина;
вероятность события;
генеральная совокупность;
несовместное событие.
Глава 2.
Формирование и свойства эмпирических совокупностей
2.1. Постановка задачи
Результаты наблюдения над лесохозяйственными объектами обычно фиксируются в журналах, бланках, анкетах и других документах учета или заносятся непосредственно в соответствующие файлы портативных компьютеров. Зафиксированные сведения об изучаемом объекте представляют первичный фактический материал, который нуждается в соответствующей обработке с целью исследования генеральной совокупности. На практике инженер лесного хозяйства имеет дело только с выборочной совокупностью (выборкой), т.е. частью генеральной совокупности, поэтому возникает потребность по результатам сравнительно небольшой выборки сделать предположение о поведении всей генеральной совокупности. В других случаях необходимо какой-либо совокупности величин поставить в соответствие другую совокупность и выяснить, имеется ли между ними различия, какая-либо взаимосвязь или нет.
Для того, чтобы сделать статистическое заключение о рассматриваемом объекте, следует выполнить ряд взаимосвязанных операций:
Грамотно обеспечить отбор единиц выборочной совокупности;
Систематизировать и сгруппировать результаты наблюдений;
Графически представить эмпирические совокупности;
Получить статистические показатели для эмпирических совокупностей;
Получить статистические параметры для генеральной совокупности.
Единицы выборочной совокупности (варианты) должны быть отобраны так, чтобы по ним с достаточной точностью можно было судить о свойствах генеральной совокупности. Зачастую в исследованиях производится отбор так называемых "типичных" представителей генеральной совокупности. Такой подход субъективен и не может служить основой получения качественной информации. Заданная точность в характеристике генеральной совокупности обеспечивается случайным отбором необходимого количества вариант.
2.2. Классификация и группировка вариант
Первичные данные наблюдений представляют собой ряд значений, записанных (или занесенных непосредственно в файл компьютера) в последовательности получения. Такой ряд называется статистической совокупностью, а каждый член этой совокупности - вариантой. Число вариант в совокупности представляет объем совокупности N.
П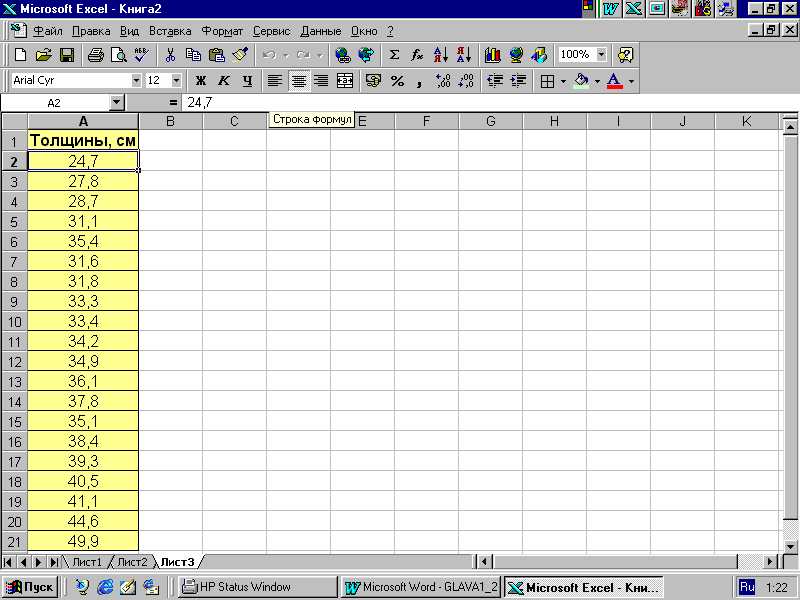 ример
2.1. Пусть
получена статистическая совокупность
диаметров (см) деревьев сосны обыкновенной
на пробной площади. Объем совокупности
N=20:
28,7; 31,1; 38,1; 35,4; 38,0; 49,9; 37,8; 34,9; 39,3; 41,0; 33,4;
36,1; 34,2; 44,6; 40,5; 24,7; 31,8; 27,8; 31,6; 33,0. Файл данных
в среде программы MS
Excel
может выглядеть следующим образом (рис.
2.1):
ример
2.1. Пусть
получена статистическая совокупность
диаметров (см) деревьев сосны обыкновенной
на пробной площади. Объем совокупности
N=20:
28,7; 31,1; 38,1; 35,4; 38,0; 49,9; 37,8; 34,9; 39,3; 41,0; 33,4;
36,1; 34,2; 44,6; 40,5; 24,7; 31,8; 27,8; 31,6; 33,0. Файл данных
в среде программы MS
Excel
может выглядеть следующим образом (рис.
2.1):
Рис. 2.1.
Статистическая обработка первичных данных начинается с расположения вариант в определенной последовательности, зависящей от характера варьирования изучаемого признака:
Количественное:
непрерывное;
дискретное.
2. Качественное:
атрибутивное.
При непрерывном варьировании отдельные значения признака могут иметь любое значение меры (протяженности, объема, веса и т.д.) в определенных пределах. Например, толщина деревьев в древостое принимает различные значения меры протяженности от самого тонкого до самого толстого.
При дискретном варьировании отдельные значения признака выражаются отвлеченными числами (чаще всего целыми). Например, число деревьев на пробной площади, диаметр деревьев в ступенях (классах) толщины и т.д.
При атрибутивном варьировании значения признака классифицируют по градациям этого признака. Например, цвет, повреждаемость, класс бонитета и т.д.
При количественном варьировании первоначальное упорядочивание совокупности проводят в порядке возрастания или убывания. При малом числе вариант (до 20) строится непосредственный ряд значений.
Пример 2.2. Упорядоченный ряд значений толщины деревьев по данным примера 2.1 может быть получен в программе MS Excel с помощью процедуры "Сортировка", которая находится в меню "Данные" (рис. 2.2).
При большем объеме выборки (N>20) ранжированный ряд не обладает свойством наглядности. Поэтому значение признака размещают с указанием числа их повторяемости в виде двойного ряда. В первой строке (столбце) заносят значение признака, а во второй строке (столбце) указывают число повторяющихся значений.
Пример 2.3. Двойной ряд значений толщины деревьев в примере 2.1 может быть получен в программе MS Excel с помощью статистической функции "ЧАСТОТА" (рис. 2.3).
Размещение значений признака в порядке их возрастания (убывания) с указанием числа их повторяемости называют вариационным рядом. В вариационном ряду значения признака, разнесенные по классам, называют распределением частот. Очевидно, что сумма частот равна объему выборки N (см. рис. 2.3).
Величина классового промежутка, на которую разбивается ряд варьирующих значений признака определяется по формуле:
![]() ,
,
где
X max, X min – максимальное и минимальное значения признака;
n – число классовых промежутков.
Число классовых промежутков зависит от объема выборки и ориентировочно равно корню квадратному из числа наблюдений.
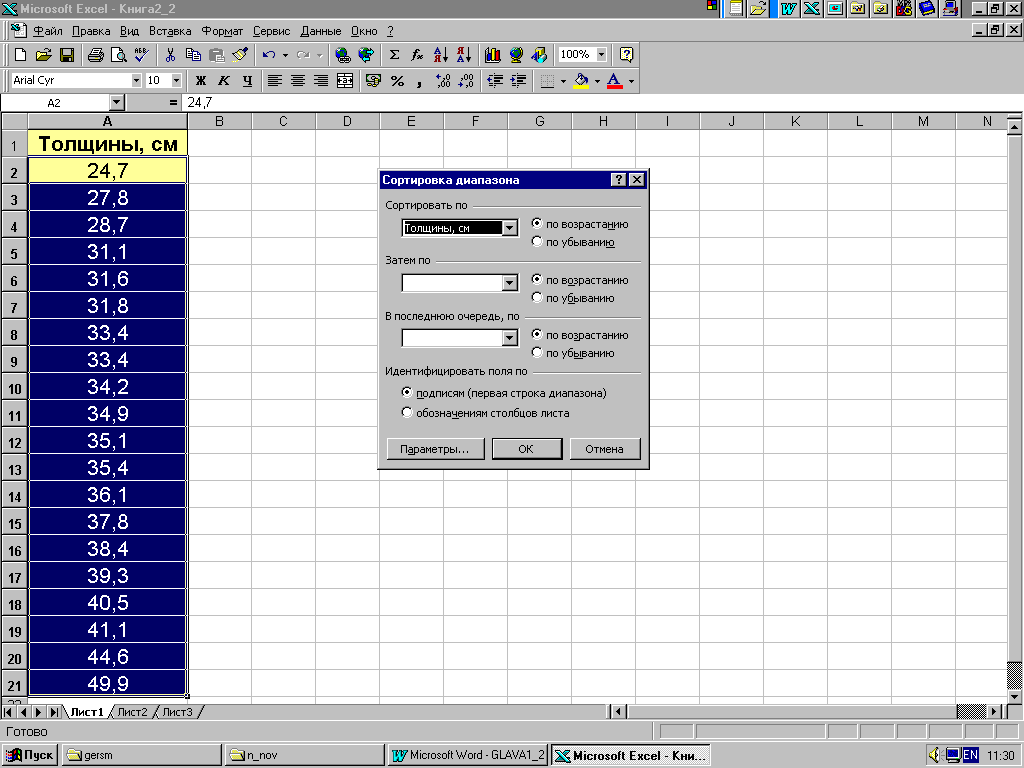
Рис. 2.2.
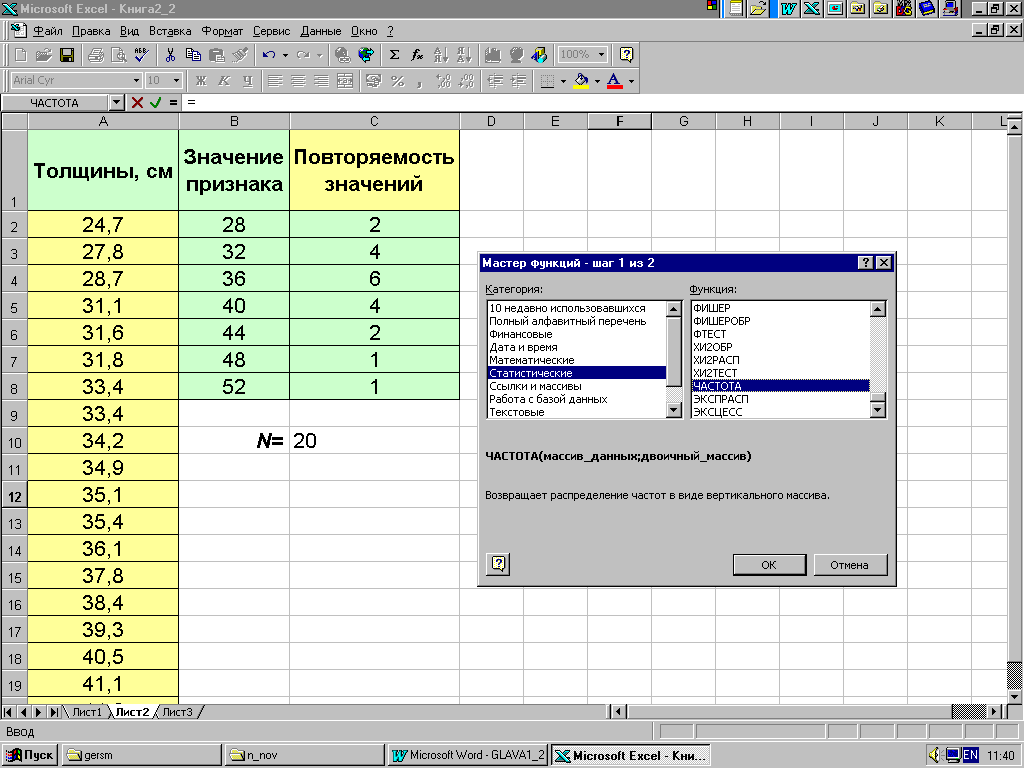
Рис. 2.3.