

5.2. Однофакторный комплекс
Изучается зависимость некоторой величины от меняющегося фактора А, градации (или уровни) которого обозначены Ai. Тогда каждое наблюдение можно обозначить через xij, где i - уровень фактора A, j - номер наблюдения. Исходные данные удобно представить в виде табл. 5.1.
Таблица 5.1
Уровни фактора Ai |
Результаты измерений |
Средние по факторам |
A1 |
x11 x12 … x1m |
M1 |
A2 |
x21 x22 … x2m |
M2 |
… |
… |
… |
Ak |
Xk1 xk2 … xkm |
Mk |
В табл. 5.1 k строк (или групп) - по числу уровней фактора А, в каждой группе mi наблюдений (число наблюдений неодинаково); при равном числе наблюдений подход не меняется, но приводимые ниже формулы несколько упрощаются, так как все mi равны m. Для подготовки данных к анализу образуем суммы квадратов:
s02=
![]() (xij—M)2;
(5.1)
(xij—M)2;
(5.1)
sm2=
![]() mi(xij—M)2;
(5.2)
mi(xij—M)2;
(5.2)
sb2= (xij—Mi)2, (5.3)
где
s02 - общая сумма квадратов всех наблюдений от общей средней M;
sm2 - cумма квадратов отклонений групповых средних Mi от общей средней M, взвешенной через число наблюдений по группам:
sb2 -cумма квадратов отклонений внутри групп (от групповых средних).
Простые преобразования позволяют разложить первую сумму на две другие:
s02 = sm2 + sb2 . (5.4)
Формула (5.4) является основой дисперсионного анализа. Рассмотрим оценки дисперсий, связанных с введенными суммами. Сумма s02 связана с оценкой общей дисперсии изучаемого признака, если ее разделить на число степеней свободы N - 1, где N - число наблюдений. По сумме sm2 можно оценить дисперсию между уровнями факторов Ai - межгрупповую дисперсию. Число степеней свободы k - 1. Сумма sb2 позволяет оценить дисперсию внутри групп (или остаточную). Так как оценка дисперсии внутри каждой из групп связана с mi - 1 степенью свободы, то общее число степеней свободы k(mi - 1) = N - k.
Дальнейший анализ зависит от типа рассматриваемой модели. Для модели с фиксированными факторами ответ на основной вопрос дисперсионного анализа сводится к проверке гипотезы Н0: M1 = M2 = … = Mk, то есть утверждения, что все групповые средние не зависят от влияния фактора А. Тогда, если верна Н0, межгрупповая дисперсия должна быть равна внутригрупповой, то есть сформулированная гипотеза может быть заменена эквивалентной Н0: sm2 = sb2. Допустим, что xi - независимые наблюдения над случайной величиной X, распределенной нормально со средним и дисперсией 2. Тогда отношение (5.5) используется в качестве статистической характеристики критерия.
F(k,
n-k)
=
 .
(5.5)
.
(5.5)
Если вычисленное значение F меньше табличного на 5-процентном уровне значимости , то гипотезу об отсутствии влияния фактора А не отклоняют. Если рассчитанное значение F больше табличного на 1- процентном уровне значимости, то различия по уровням фактора А являются существенными. Если же факторы случайны, то проверка гипотезы о равенстве групповых средних представляет небольшой интерес (уровни фактора А - сами случайные величины) и проверяют гипотезу о том, что межгрупповая дисперсия в генеральной совокупности равна нулю Ho: sm2 = 0.
Пример 5.3. Исследуется влияние средней высоты древостоя на величину среднего видового числа условно одновозрастных спелых ельников с помощью MS Excel (см. рис. 5.1). Числа наблюдений mi и групповые средние Mi рассчитываются соответственно в колонках H и I. Число групп k = 8, общее число наблюдений N=40. Общее среднее M = 460 (ячейка I10). Квадраты отклонений вариант от групповых средних рассчитаны в ячейках B12…G19. В колонке J по формулам (5.1) - (5.5) вычислены показатели s02=36195, sm2=14587, sb2 = 21608, учитывая, что число степеней свободы для групповой дисперсии равно k - 1 = 8 – 1 = 7, для общей N - 1 = 40 – 1 = 39, а для внутригрупповой N - k = 40 – 8 = 32. Статистическая характеристика из (5.5) Fф = 2084/675 = 3,09. При = 0,05 табличное значение F (из табл. 4.3 или с использованием функции MS Excel FРАСПОБР()) Fst(0,05;7;32) = 2,3. Так как Fф > Fst, то гипотезу об отсутствии влияния высоты на среднее видовое число древостоя отклоняют: средние значения видовых чисел в генеральной совокупности не все равны между собой.
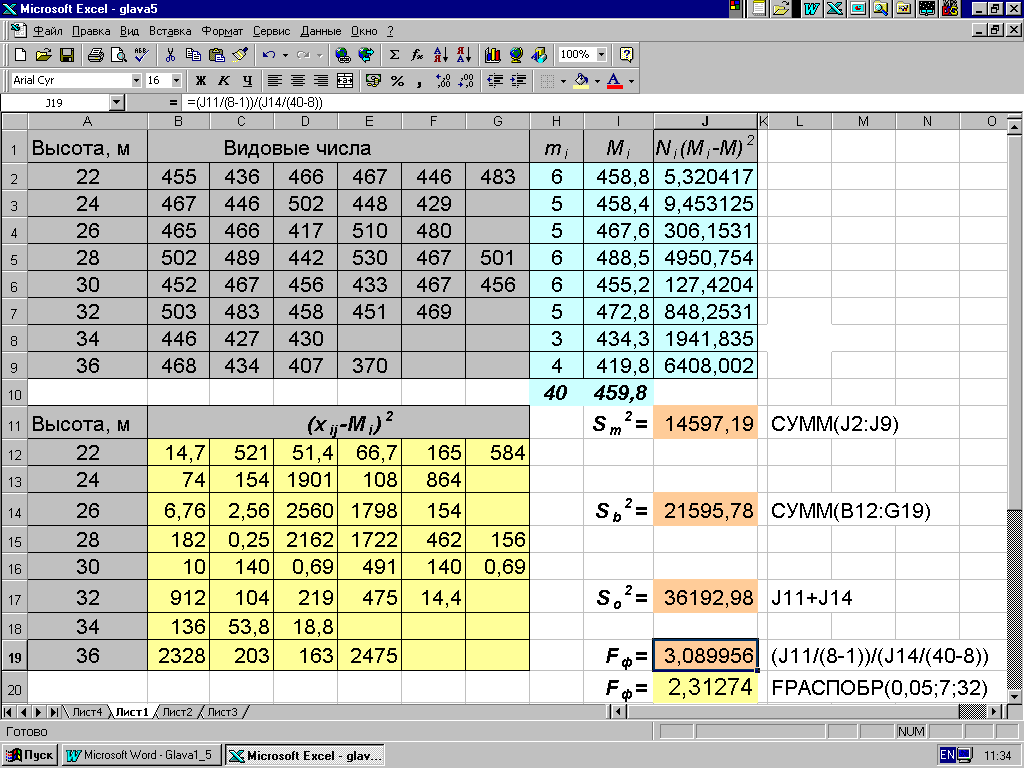
Рис. 5.1.