

Определить назначение, структуру, количество регистров процессора обработки чисел с плавающей точкой ia-32 (x87)
Набор регистров, входящих в блок FPU, изображен на схеме ниже. При работе FPU 80-разрядные регистры ST0-ST7 образуют кольцевой стек, в котором хранятся числа с плавающей точкой, представленные в формате с расширенной точностью.
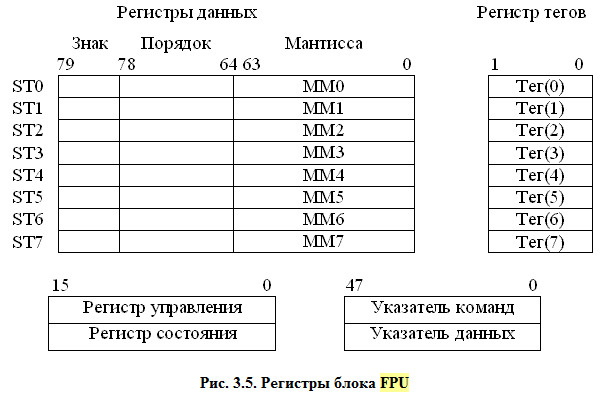
Регистр тегов FPU содержит 16-разрядное слово, включающее восемь двухбитовых тегов. Каждый тег (признак) характеризует содержимое одного из регистров данных. Тег определяет, является ли регистр пустым (незаполненным) – код 11 или в него введено конечное число – 00 (достоверное значение), или нуль – 01, неопределенное значение (бесконечность) – 10 (нет числа и неподдерживаемый формат). Слово тегов позволяет оптимизировать функционирование FPU посредством идентификации пустых и непустых регистров данных, проверить содержимое регистра без сложного декодирования хранящихся в нем данных.
Регистры ммх-технологии
При реализации ММХ-команд регистры данных FPU используются как 64-разрядные регистры ММ0 – ММ7 (схема выше), где могут храниться несколько целочисленных операндов (восемь 8-разрядных, четыре 16-разрядных, два 32-разрядных или один 64-разрядный), над которыми одновременно выполняется поступившая в процессор команда.
Организация многоуровневой кэш-памяти
Большинство современных компьютеров имеют два или три уровня кэш-памяти. Первый, наиболее «близкий» к ядру процессора (L1), обычно реализуется на быстрой двухпортовой синхронной статической памяти, работающей на полной частоте ядра. Объём L1-кэша весьма невелик, составляет 64 КВ или 128 КВ и разделяется пополам на два кэша данных и команд для каждого ядра процессора. Латентность кэша L1 измеряется 3-мя, 4-мя тактами. На втором уровне расположен кэш L2. Он реализуется на однопортовой конвейерной статической памяти и зачастую работает на пониженной тактовой частоте. Поскольку однопортовая память значительно дешевле, объём L2-кэша достигает нескольких мегабайт в двухъядерных структурах процессоров, когда он является общим для двух ядер (Intel Core 2 Duo), или несколько сотен килобайт (256 КВ или 512 КВ), когда в многоядерном процессоре каждое ядро имеет свой L2-кэш. Этот кэш хранит как команды, так и данные. Латентность L2 для процессоров Intel Nehalem 3,2 ГГц составляет 11 тактов, для Penryn 3,2 ГГц – 18 тактов.
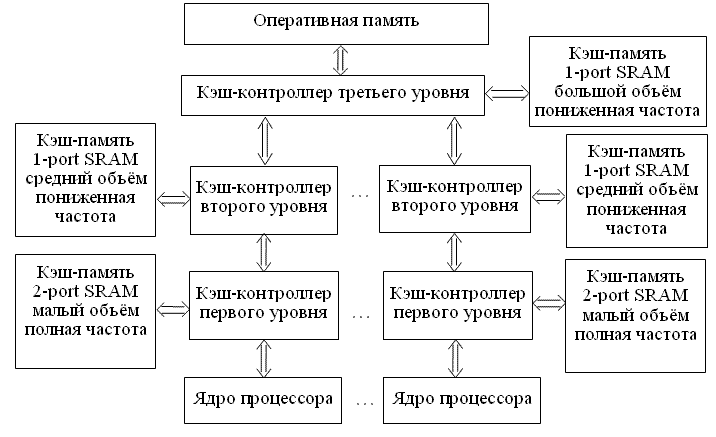
На третьем уровне находится L3-кэш, который объединяет ядра между собой и является разделяемым. В результате, L2-кэш выступает в качестве буфера при обращениях процессорных ядер в разделяемую кэш-память, имеющую достаточно солидный объём (2 МВ – AMD K10, 8 МВ – Intel Nehalem). Латентность L3-кэша исчисляется 52-мя, 54-мя тактами.
При построении многоуровневой кэш-памяти используют включающую (inclusive) или исключающую (exclusive) технологии. Кэш верхнего уровня, построенный по inclusive-технологии, всегда дублирует содержимое кэша нижнего уровня. Если построить инклюзивный L3-кэш, то он будет дублировать данные, хранящиеся в кэшах первого и второго уровней, что снижает эффективную ёмкость всей кэш-подсистемы. С другой стороны, инклюзивный разделяемый L3-кэш способен обеспечить в многоядерных процессорах более высокую скорость работы подсистемы памяти. Это связано с тем, что, если ядро попытается получить доступ к данным, и они отсутствуют в кэше L3, то нет необходимости искать эти данные в собственных кэшах других ядер – там их нет. А благодаря тому, что каждая строка L3-кэша снабжена дополнительными флагами, указывающими владельцев (ядра) этих данных, не вызывает затруднений и процедура обратного изменения содержимого строки кэша. Так, если какое-то ядро модифицирует данные в L3-кэше, изначально принадлежащие другому (или другим) ядрам, то в этом случае обновляется содержимое L1 и L2-кэшей и этих ядер. Эта технология весьма эффективна для обеспечения когерентности персональных кэшей каждого ядра, поскольку она уменьшает потребность в обмене информацией между ядрами. По такой технологии организована кэш-память процессоров Intel Nehalem.
Кэш – подсистема, построенная по exclusive-технологии, никогда не хранит избыточных копий данных и потому эффективная ёмкость подсистемы определяется суммой ёмкостей кэш-памятей всех уровней. Кэш первого уровня никогда не уничтожает строки при нехватке места. Даже если они не были модифицированы, данные в обязательном по-рядке вытесняются в кэш второго уровня, помещаясь на то место, где находилась только что переданная кэшу L1 строка. Т. е. кэши L1 и L2 как бы обмениваются друг с другом своими строками, а потому кэш-память используется весьма эффективно.