

Б) исходя из "размаха" распределения
В) нахождение доверительных интервалов среднего значения признака, с использованием ошибки среднего арифметического.
Г)
выявление стандартного отклонения и
нахождения интервала
![]() , в
который попадает
68% значений выборки при нормальном
распределении
, в
который попадает
68% значений выборки при нормальном
распределении
А) Нахождение квартилей по процентильной шкале. Эта шкала разбивается на 4 части, каждая из частей называется квартилем.
|
Q4 |
Четвертый квартиль |
75-100% |
Среднее значение |
Q3 |
Третий квартиль |
50-75% |
Q2 |
Второй квартиль |
25-50% |
|
|
Q1 |
Первый квартиль |
0-25% |
Процентили подсчитываются по следующему алгоритму:
1). Располагаем значения признака в нашей выборке в порядке возрастания (столбец 2 табл. 3)
Таблица.3.
№№ п/п |
Значения (xi ) |
Частоты встречаемости |
Накопленные частоты xf |
Процентили |
|
1 |
2 |
3 |
4 |
5 |
|
|
|
23 |
1 |
1 |
2 |
|
|
|
25 |
1 |
2 |
4 |
|
|
|
28 |
1 |
3 |
6 |
|
|
|
29 |
2 |
5 |
10 |
|
|
|
31 |
1 |
6 |
12 |
|
|
|
32 |
2 |
8 |
16 |
|
|
|
33 |
1 |
9 |
18 |
|
|
|
34 |
1 |
10 |
20 |
|
|
|
36 |
1 |
11 |
22 |
|
|
|
38 |
1 |
12 |
24 |
|
|
|
39 |
2 |
14 |
28 |
|
|
|
41 |
1 |
15 |
30 |
|
|
|
42 |
2 |
17 |
34 |
|
|
|
43 |
1 |
18 |
36 |
|
|
|
44 |
2 |
20 |
40 |
|
|
|
45 |
2 |
22 |
44 |
|
|
|
47 |
3 |
25 |
50 |
|
|
|
48 |
1 |
26 |
52 |
|
|
|
49 |
2 |
28 |
56 |
|
|
|
50 |
1 |
29 |
58 |
|
|
|
51 |
2 |
31 |
62 |
|
|
|
52 |
1 |
32 |
64 |
|
|
|
54 |
3 |
35 |
70 |
|
|
|
55 |
2 |
37 |
74 |
|
|
|
57 |
2 |
39 |
78 |
|
|
|
58 |
2 |
41 |
82 |
|
|
|
61 |
1 |
42 |
84 |
|
|
|
62 |
1 |
43 |
86 |
|
|
|
63 |
2 |
45 |
90 |
|
|
|
65 |
1 |
46 |
92 |
|
|
|
67 |
1 |
47 |
94 |
|
|
|
70 |
1 |
48 |
96 |
|
|
|
71 |
1 |
49 |
98 |
|
|
|
73 |
1 |
50 |
100 |
|
В столбце 3 располагаем частоты в встречаемости каждого значения (xi )
В
 столбце 4 подсчитываем накопленные
частоты – сверху вниз прибавляется
частота встречаемости каждого значения
столбце 4 подсчитываем накопленные
частоты – сверху вниз прибавляется
частота встречаемости каждого значенияВ столбце 5 вычисляем и записываем накопленные проценты – исходя из того, что количество значений (измерений, равных количеству испытуемых) в нашей выборке = 50,
100% - 50
процентиль - накопленная частость (xf )
процентиль =![]()
![]()
После заполнения колонки 5 табл. 3. находим квартили. Квартиль 1: Q1 – это величина, ниже которой располагаются 25% всех значений [3]. Это – 25% граница. Ниже третьего квартиля располагается 75 % всех значений. 75% ранг соответствует значению признака приблизительно 56 (см. колонка 5 табл. 5.3) , а 25 процентиль примерно 38,5.
Таким образом, можно считать, что индивиды, у которых значение измеряемого признака в данной выборке (в нашем примере – личностная тревожность) оказалось выше 56, относятся к лицам с повышенной тревожностью, а те, у кого значение ЛТ оказалось ниже 38,5 – относятся к "низкой группе" (личностная тревожность – ниже среднего уровня).
Для распределений, отклоняющихся от нормального (ассиметричных) более правильным будет нахождение полуквартильных отклонений по медиане [2].
Процентильный способ нахождения средне-интервального значения страдает неточностью, так как интервалы между делениями шкалы различны и при нормальном распределении расхождения между ними больше в противоположных частях шкалы, в то время как в центре шкалы (вокруг позиции 50) интервалы очень незначительны. С помощью процентной ранговой шкалы - в отличие от шкал интервалов – нельзя вычислить ни среднего арифметического, ни величины рассеяния признака.
Б) Выявление "размаха" распределения позволяет также найти среднеинтервальное (средневыборочное) значение. Интервальное оценивание – интервал числовой оси, в пределах которого где-то лежит значение данного параметра. В этом случае вместо одного числа – среднего арифметического – точечной оценки – указывается нижняя и верхняя границы интервала. Когда интервал строится с учетом попадания значения параметра в границы интервала, он называется доверительным интервалом. Вероятность того, что в случайно выбранный нами интервал из совокупности всех возможных доверительных интервалов будет содержать искомый параметр, называют доверительным коэффициентом, или уровнем доверительной вероятности. В психологических исследованиях выбирают уровни доверительной вероятности 95% (0, 95), 99% (0,99) и 99,9%. Данные уровни вероятности говорят о том, что вывод – вероятностный, т.е. заключающий в себе риск допустить ошибку (с вероятностью 95% или 99%)
Построение 95% доверительного интервала для среднего арифметического в случае нашего примера можно производить, исходя из размаха распределения [4].
Размах – это разность максимального и минимального значений в ряду данных.
В нашем примере: W = x max - x min = 73 – 23 =50
В
Верхняя
граница
Нижняя
граница![]()
![]() ерхнюю
и нижнюю границы доверительного интервала
среднего арифметического определяют
по формулам:
ерхнюю
и нижнюю границы доверительного интервала
среднего арифметического определяют
по формулам:
W –
размах , kn
– табличный коэффициент![]()
В нашем примере W = 50 ; k50 = 0,13 (см. таблицу 3.)
Т.о. Верхняя граница = 47,6 + 0,13 50 = 54,1; Нижняя граница = 47,6 - 0,13 50 = 41,1
Таким образом, доверительный интервал для среднего арифметического на уровне вероятности 95% представлен значениями: 41,1 - 54,1
Таблица 4.
Значения коэффициента kn для расчета границ доверительных интервалов средних арифметических (для уровня достоверности 95%)
n |
kn |
n |
kn |
5 6 7 8 9 10 11 12 |
0,51 0,40 0,33 0,29 0,25 0,23 0,21 0,19 |
13 14 15 16 17 18 19 20 |
0,18 0,17 0,16 0,15 0,14 0,14 0,13 0,13 |
![]() В). Доверительные интервалы для
нахождения среднеинтервального значения
признака строятся также на основе ошибки
математического ожидания (Стандартная
ошибка среднего арифметического)
(Бодалев, Столин, С. 61):
В). Доверительные интервалы для
нахождения среднеинтервального значения
признака строятся также на основе ошибки
математического ожидания (Стандартная
ошибка среднего арифметического)
(Бодалев, Столин, С. 61):
Где Sm – стандартная ошибка среднего арифметического, которая оценивается по формуле:
Где S
– стандартное отклонение (в других
источниках эта величина обозначается
δ) n
- количество испытуемых в выборке
(объем)
![]()
Если тестовый балл какого-либо испытуемого попадает в границы доверительного интервала, то нельзя сказать, что испытуемый обладает повышенным (или пониженным) значением измеряемого свойства с заданным уровнем статистической значимости.
МЕРЫ РАЗБРОСА ИЛИ РАССЕИВАНИЯ ПРИЗНАКА:
Наиболее часто употребляемыми мерами рассеивания признака считаются размах и стандартное отклонение (или среднеквадратическое отклонение)
Размах – это разность максимального и минимального значений в ряду данных.
W = x max - x min . В нашем примере W = 73 – 23 =50
Более точной мерой рассеивания данных является стандартное отклонение или дисперсия.
Для несгруппированных данных вычисляют стандартное отклонение (S), которое используют как синоним среднеквадратического отклонения (), дисперсия вычисляется как квадрат этой величины [2].
Расчет осуществляется по следующему алгоритму (см. табл. 5):
1. Рассчитываем среднее арифметическое ( ). В нашем примере = 47,6
Находится отклонение каждого результата измерения (хi) от среднего арифметического = ( хi - ) см. колонка №3.
Найденное значение отклонения каждого результата от среднего возводится в квадрат
( хi - )2 - колонка №4.
Таблица 5.
Ранг |
Значения |
( хi - ) |
( хi - )2 |
Ранг |
Значения |
( хi - ) |
( хi - )2 |
|
1 |
2 |
3 |
4 |
1 |
2 |
3 |
4 |
|
1 |
23 |
-24,6 |
605,16 |
26 |
48 |
0,4 |
0,16 |
|
2 |
25 |
-22,6 |
510,76 |
27,5 |
49 |
1,4 |
1,96 |
|
3 |
28 |
-19,6 |
384,16 |
27,5 |
49 |
1,4 |
1,96 |
|
4,5 |
29 |
-18,6 |
342,25 |
29 |
50 |
2,4 |
5,76 |
|
4,5 |
29 |
-18,6 |
342.25 |
30,5 |
51 |
3,4 |
11,56 |
|
6 |
31 |
-16,6 |
275,56 |
30,5 |
51 |
3,4 |
11,56 |
|
7,5 |
32 |
-15,6 |
243,36 |
32 |
52 |
4,4 |
19,36 |
|
7,5 |
32 |
-15.6 |
243,36 |
34 |
54 |
6,4 |
40,96 |
|
9 |
33 |
-14,6 |
213,16 |
34 |
54 |
6,4 |
40,96 |
|
10 |
34 |
-13,6 |
184,96 |
34 |
54 |
6,4 |
40,96 |
|
11 |
36 |
-11,6 |
134,56 |
36,5 |
55 |
7,4 |
54,76 |
|
12 |
38 |
-9,6 |
92,16 |
36,5 |
55 |
7,4 |
54,76 |
|
13,5 |
39 |
-8,6 |
73,96 |
38,5 |
57 |
9,4 |
88,36 |
|
13,5 |
39 |
-8,6 |
73,96 |
38,5 |
57 |
9,4 |
88,36 |
|
15 |
41 |
-6,6 |
43,56 |
40,5 |
58 |
10,4 |
108,16 |
|
16,5 |
42 |
-5,6 |
31,36 |
40,5 |
58 |
10,4 |
108,16 |
|
16,5 |
42 |
-5.6 |
31,36 |
42 |
61 |
13,4 |
179,56 |
|
18 |
43 |
-4,6 |
21,16 |
43 |
62 |
14.4 |
207,36 |
|
19,5 |
44 |
-3.6 |
12,96 |
44,5 |
63 |
15,4 |
237,16 |
|
19,5 |
44 |
-3.6 |
12,96 |
44,5 |
63 |
15.4 |
237,16 |
|
21,5 |
45 |
-2.6 |
6,76 |
46 |
65 |
17,4 |
302,76 |
|
21,5 |
45 |
-2.6 |
6,76 |
47 |
67 |
19,4 |
376,36 |
|
24 |
47 |
-0,6 |
0,36 |
48 |
70 |
22,4 |
501,76 |
|
24 |
47 |
-0,6 |
0,36 |
49 |
71 |
23,4 |
547,56 |
|
24 |
47 |
-0,6 |
0,36 |
50 |
73 |
25,4 |
645,16 |
( хi - )2 = 7457,93 |
Суммируются значения квадратов отклонений: ( хi - )2
Сумма квадратов отклонений делится на общее количество наблюдений (n), в результате чего получается величина, называемая дисперсией (D)
Д елим сумму квадратов отклонений на общее число наблюдений (n) и получаем величину, называемую дисперсией: D = ( - хi )2
 n
n
В общем случае стандартное отклонение вычисляется как корень квадратный из дисперсии:
В
нашем примере
√152,2
= 12,34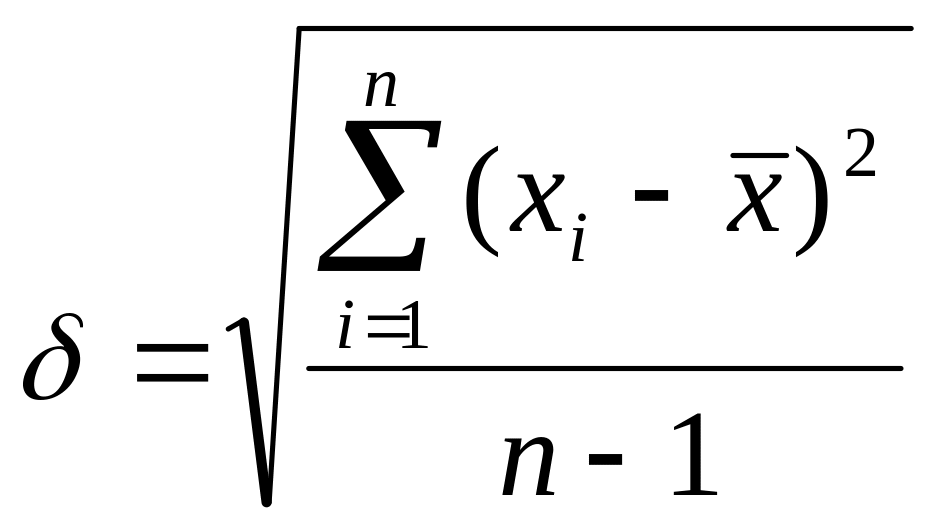
![]()
Г) Согласно характеристикам нормального распределения, примерно 68% значений признака попадают в интервал , и составляют статистическую "норму".. Значения признака, отстоящее от среднего больше, чем на одну δ, можно отнести к значениям выше среднего, а соответственно, меньше чем на одну δ – ниже среднего.
В нашем примере: 47,6 – 12,34 = 35,26; 47,6 + 12.34 = 59,94.
= 35,3 - 60
Следовательно, значения ниже 35,3 будут считаться пониженным уровнем личностной тревожности (по сравнению со средневыборочным), а значения выше 60 – повышенным уровнем. Соответственно, испытуемые, которые в результате данного психодиагностического исследования получили балл, ниже 33,5 – обладают пониженным уровнем ЛТ, а те участники, чей балл оказался выше 60 – имеют повышенный уровень личностной тревожности.