

Нисходящий распознаватель с подбором альтернатив
В реальных трансляторах задача построения дерева вывода решается посредством некоторого автомата, на выходе которого выводится результат разбора. Существует несколько алгоритмов подобной процедуры. Одним из наиболее распространенных является нисходящее распознавание с подбором альтернатив.
Для его реализации используется распознаватель, включающий устройство управления (УУ в виде автомата) и два стека: стек L1 автомата и дополнительный стек L2. Данный автомат характеризуется одним основным состоянием q и дополнительным состоянием возврата b.
Н а
вход распознавателя поступает текст
из терминальных символов и считывающая
головка в начальный момент находится
в крайнем левом положении, т.е. напротив
первого символа цепочки. также в этот
момент в стеке L1
находится целевой символ грамматики
S.
а
вход распознавателя поступает текст
из терминальных символов и считывающая
головка в начальный момент находится
в крайнем левом положении, т.е. напротив
первого символа цепочки. также в этот
момент в стеке L1
находится целевой символ грамматики
S.
В конечный момент стек L1 пуст, а считывающая головка находится за последним символов входной цепочки.
Неформально работа рассматриваемого автомата включает два основных действия:
Если на верхушке основного стека L1 находится нетерминальный символ А и в грамматике есть правило вида А , то в стеке символ А можно заменить на цепочку (рис. 8.2). Головка распознавателя при этом не сдвигается. Такой шаг распознавания называется подбором альтернатив.
Е
 сли
на верхушке стека находится терминальный
символ а VT
и он совпадает с текущим символом
входной цепочки, то данный символ можно
выбросить из стека и передвинуть головку
считывания на один шаг вправо (рис.
8.3). Этот шаг называется выбросом.
сли
на верхушке стека находится терминальный
символ а VT
и он совпадает с текущим символом
входной цепочки, то данный символ можно
выбросить из стека и передвинуть головку
считывания на один шаг вправо (рис.
8.3). Этот шаг называется выбросом.

Рассматриваемый автомат является недетерминированным, т.е., если набор продукций грамматики Р допускает правила вида А 1 2 3 . . ., то у автомата на данном шаге существует несколько альтернатив.
Автомат реализует левосторонний вывод, посему в грамматике не должно быть левых рекурсий А ... А ..., так как автомат может войти в бесконечный цикл.
При разборе распознаватель должен хранить информацию о пройденном пути (какие альтернативы и на каком шаге были выбраны).
Более формально данный распознаватель предполагает:
Входная цепочка имеет вид = a1a2 ... an, = n.
Все альтернативы для нетерминальных символов вида А 1 2 3 . . . k пронумерованы.
В алгоритме есть дополнительное состояние back (назад), предназначенное для возврата назад к уже прочитанной части цепочки.
Для хранения уже перебранных альтернатив используется дополнительный стек L2, в котором может храниться следующая информация:
символы а VT входного языка автомата;
номера продукций, т.е. символы вида Аj (A VN, Aj - j-я альтернатива для данного нетерминального символа).
Основной стек L1.
Оба стека представляются в виде цепочки. Но в стек L1 символы помещаются слева, а в L2 - справа. Теперь текущее состояние распознавателя на каждом шаге описывается четверкой (К, i, L1, L2), где К = {k, b};
i - положение считывающей головки во входной цепочке символов (1<nn+1);
L1 - содержимое основного стека автомата;
L2 - содержимое дополнительного стека.
Начальное состояние распознавателя: (k, 1, S, ), где S - целевой символ.
Алгоритм распознавания включает шесть разновидностей шагов:
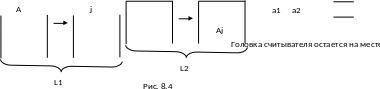
В1 (разрастание). Реализуется переход вида (k, i, A, ) (k, i, j, Aj)
Такой шаг выполняется, если наверху L1 нетерминальный символ А (рис. 8.4) и выбирается первая альтернатива Аj j. Очевидно, что этот вариант должен быть первым при запуске разбора.
В2 (успешное сравнение). Реализуется переход вида (k, i, а, ) (k, i+1, , а), если наверху стека символ а VТ и этот же символ является текущим во входной строке (см. рис. 8.5).

В3 (завершение). Если текущее состояние имеет вид (k, i, , (состояние k и стек L1 пуст)) то проводится анализ на предмет завершения алгоритма. Если считывающая головка вышла за пределы входной строки, то алгоритм распознавания успешно завершен (рис. 8.6). В противном случае надо возвращаться назад. Имеет место переход (k, i, , ) (b, i, , ).


В4 (неуспешное сравнение). Реализуется переход вида (k, i, а, ) (b, i, a, ), если наверху стека символ аVТ, но текущим во входной строке является другой терминальный символ (рис. 8.7). В этом случае надо идти назад.
В5 (возврат по входу). Надо идти назад. Реализуется переход вида (b, i, , a) (b, i-1, a, ).

В6 (другая альтернатива). Здесь возможны три подварианта.
а) Переход вида (b, i, j, Aj) (k, i, j+1, Aj+1), если имеет место продукция (Аj+1), т.е. не перебраны все варианты продукций у нетерминального символа. (Переход к другой продукции);
б) Выдача сигнала об ошибке, если А = S и не существует больше альтернатив для S.
в )
Последний вариант - переход в состояние
(b, i, j,
Aj)
(k,
i, А,
): пройдены все
возможные альтернативы для данного
нетерминального символа, и теперь надо
возвращаться к нетерминальному символу
слева, чтобы потом подняться еще выше
назад (рис. 8.9).
)
Последний вариант - переход в состояние
(b, i, j,
Aj)
(k,
i, А,
): пройдены все
возможные альтернативы для данного
нетерминального символа, и теперь надо
возвращаться к нетерминальному символу
слева, чтобы потом подняться еще выше
назад (рис. 8.9).
Если распознавание завершилось успешно, то в стеке L2 будет сохранен весь пройденный путь.
В качестве примера работы данного распознавателя рассмотрим начало нисходящего разбора предложения, проанализированного в предыдущей лабораторной работе. Естественно, что сохраняется введенная грамматика и нумерация ее продукций. Перечень первых двадцати шагов распознавателя, состояние распознавателя на каждом шаге и комментарий, объясняющий выбор разновидности шага, представлены в таблице. При этом надо помнить, что исходное состояние распознавателя описывается четверкой (k, 1, S, ).