

Линейные списки с индексами. Построение и поиск элемента. Способы коррекции
Это последовательные списки, то есть массивы. Обязательно рассортируем их в порядке возрастания. Массив N делят на секции, размер каждой из которых N/I, где I – число секций. Для этой таблицы строится таблица индексов. В ней I строк и 2 столбца. В одном столбце записывается максимальный ключ секции, в другом – адрес начала секции, то есть номер первого элемента секции, а номер – это индекс.
В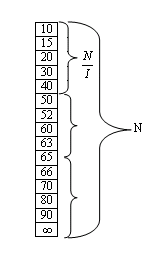 таблице индексов I
строк. Количество строк равно количеству
секций. Всего 2 столбца. В одном столбце
записывается max
путь, в другом адрес начала этой секции.
таблице индексов I
строк. Количество строк равно количеству
секций. Всего 2 столбца. В одном столбце
записывается max
путь, в другом адрес начала этой секции.
Алгоритм поиска элемента с номером k. Ищем в таблице индексов до тех пор, пока ключ k больше ключа в этой таблице. Находим начало секции, в которой нужно искать этот ключ. Перебираем, пока не найдем ключ.
![]()
![]()
![]()
![]()
Для данного примера составим таблицу индексов:
0 |
40 |
5 |
65 |
10 |
∞ |
Коррекция линейного списка:
Удаление элемента. Удаляемый элемент просто помечается.
Вставка элемента. Приходится осуществлять передвижку элементов. Чтобы уменьшить количество передвижек, придумали следующий способ: При первоначальном заполнении каждая секция заполняется не полностью, остается место. Однако, может получиться, что в какой-то момент времени секция получится полностью заполненной. Если такое случится, то проводится операция реорганизации: все помеченные элементы удаляются, свободное пространство из всех секций суммируется и делится поровну между всеми секциями.
Инвертированные списки
Инвертированный список – это таблица, в которой столько строк, сколько значений имеет поле, по которому построен инвертируемый список и два столбца. 1 – значения поля 2 – значение адреса записей в исходной таблице, в которых имеется это значение.
Коррекция инвертированных списков:
Если в исходную таблицу добавляется новый элемент, то он будет записан последним.
Инвертированные списки очень похожи на линейные списки с индексами. Они отсортировывают по значению поля. Над ними можно строить таблицы индексов.
Современные базы данных автоматически составляют список по всем полям.
Построение словаря с использованием деревьев
Пусть задана некоторая последовательность значений, которые могут повторяться. Необходимо подсчитать, сколько раз каждое значение входит в последовательность. Иначе говоря, нужно построить словарь. (Например, для заданного текста подсчитать, сколько раз входит в него каждое из слов).
Если диапазон возможных значений в последовательности конечен и не слишком велик, то это можно сделать с помощью массива, каждый элемент которого представляет собой счетчик для соответствующего значения. Для каждого очередного значения последовательности увеличивается значение его счетчика. Однако если диапазон возможных значений бесконечен или конечен, но слишком велик (например, количество разных слов в тексте), то мы не можем использовать массив, так как неизвестна его длина. В этом случае задача построения частотного словаря может быть решена с помощью дерева поиска.
К каждому узлу дерева добавляется поле счетчика. Для каждого очередного значения в последовательности осуществляется его поиск в дереве. Если такого значения в дереве еще нет (то есть оно встретилось в первый раз), в дереве создается узел, полю счетчика которого присваивается значение 1. Если узел с таким значением найден (значение встретилось уже не в первый раз), то поле счетчика этого узла увеличивается на 1.
После завершения последовательности значений можно выполнить b-обход построенного дерева, распечатывая для каждого узла его значение и величину счетчика, в результате чего получим отсортированный частотный словарь. Рассмотрим процедуру построения такого дерева на примере подсчета частного словаря символов некоторого текста. (Конечно, такую задачу можно решить и с помощью массива, так как количество разных символов в тексте конечно и невелико, но для примера рассмотрим ее решение с помощью дерева поиска).
type ptr = ^node;
node = record
info : char;
count : integer;
llink, rlink : ptr;
end;
procedure InsertAndCount( x : char; var p : ptr);
begin
if p=nil then
begin
new(p);
p^.info := x;
p^.count := 1;
p^.llink := nil;
p^.rlink := nil;
end
else if x<p^.info then InsertAndCount(x, p^.llink)
else if x>p^.info then InsertAndCount(x, p^.rlink)
else p^.count := p^.count+1;
end;
Для последовательности символов фразы <построение частотного словаря> (без учета пробелов) будет построено следующее дерево:

Выполнив b-обход этого дерева, получим словарь:
Символ |
а |
в |
г |
е |
и |
л |
н |
о |
п |
р |
с |
т |
ч |
я |
Частота |
2 |
1 |
1 |
2 |
1 |
1 |
2 |
6 |
1 |
2 |
3 |
3 |
1 |
1 |