

Управление свободным и занятым дисковым пространством
Учет при помощи организации связного списка
Другой подход - связать в список все свободные блоки, размещая указатель на первый свободный блок в специально отведенном месте диска, попутно кэшируя в памяти эту информацию.
Подобная схема не всегда эффективна. Для трассирования списка нужно выполнить много обращений к диску. Однако, к счастью, нам необходим, как правило, только первый свободный блок.
Иногда прибегают к модификации подхода связного списка, организуя хранение адресов n свободных блоков в первом свободном блоке. Первые n-1 этих блоков действительно используются. Последний блок содержит адреса других n блоков и т. д.
37. Что такое индексные узлы (inode)? Опишите, как они используются в файловой системе. Как называется такая схема размещения файлов и какие ее преимущества и недостатки? Назовите подходы к ее оптимизации. В каких файловых системах это используется?
Все дисковое пространство раздела в файловой системе NTFS логически разделяется на две части: заголовок раздела и логические блоки данных. Заголовок раздела содержит служебную информацию, необходимую для работы файловой системы, и обычно располагается в самом начале раздела. Логические блоки хранят собственно содержательную информацию файлов и часть информации о размещении файлов на диске (т.е. какие логические блоки и в каком порядке содержат информацию, записанную в файл).
Для размещения любого файла на диске используется метод индексных узлов (inode – от index node). Индексный узел содержит атрибуты файла и оставшуюся часть информации о его размещении на диске. Необходимо, однако, отметить, что такие типы файлов, как "связь", "сокет", "устройство", "FIFO" не занимают на диске никакого иного места, кроме индексного узла (им не выделяется логических блоков). Все необходимое для работы с этими типами файлов содержится в их атрибутах.
Перечислим часть атрибутов файлов, хранящихся в индексном узле и свойственных большинству типов файлов. К таким атрибутам относятся:
Тип файла и права различных категорий пользователей для доступа к нему.
Идентификаторы владельца-пользователя и владельца-группы.
Размер файла в байтах (только для регулярных файлов, директорий и файлов типа "связь").
Время последнего доступа к файлу.
Время последней модификации файла.
Время последней модификации самого индексного узла.
Индексные узлы
Наиболее распространенный метод выделения файлу блоков диска - связать с каждым файлом небольшую таблицу, называемую индексным узлом (i-node), которая перечисляет атрибуты и дисковые адреса блоков файла (см. рис 12.4). Запись в директории, относящаяся к файлу, содержит адрес индексного блока. По мере заполнения файла указатели на блоки диска в индексном узле принимают осмысленные значения.
Индексирование поддерживает прямой доступ к файлу, без ущерба от внешней фрагментации. Индексированное размещение широко распространено и поддерживает как последовательный, так и прямой доступ к файлу.
Обычно применяется комбинация одноуровневого и многоуровневых индексов. Первые несколько адресов блоков файла хранятся непосредственно в индексном узле, таким образом, для маленьких файлов индексный узел хранит всю необходимую информацию об адресах блоков диска. Для больших файлов один из адресов индексного узла указывает на блок косвенной адресации. Данный блок содержит адреса дополнительных блоков диска. Если этого недостаточно, используется блок двойной косвенной адресации, который содержит адреса блоков косвенной адресации. Если и этого не хватает, используется блок тройной косвенной адресации.
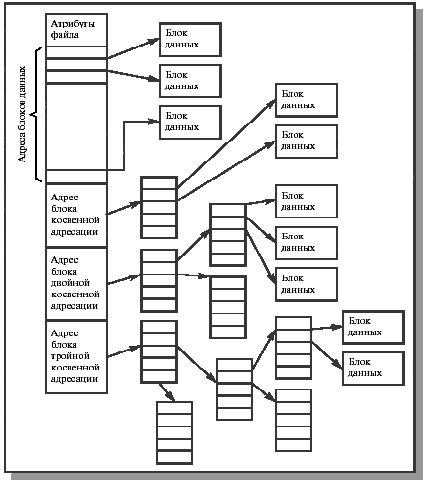
Рис. 12.4. Структура индексного узла
Данную схему используют файловые системы Unix (а также файловые системы HPFS, NTFS и др.). Такой подход позволяет при фиксированном, относительно небольшом размере индексного узла поддерживать работу с файлами, размер которых может меняться от нескольких байтов до нескольких гигабайтов. Существенно, что для маленьких файлов используется только прямая адресация, обеспечивающая максимальную производительность.
Индексируемое размещение
При индексируемом размещении, в отличие от предыдущих, все указатели на блоки файла собраны вместе в индексный блок (i-node, superblock). Используется индексная таблица, ссылающаяся на блоки данных файла. Подобная система используется в системах UNIX, Linux, Solaris.
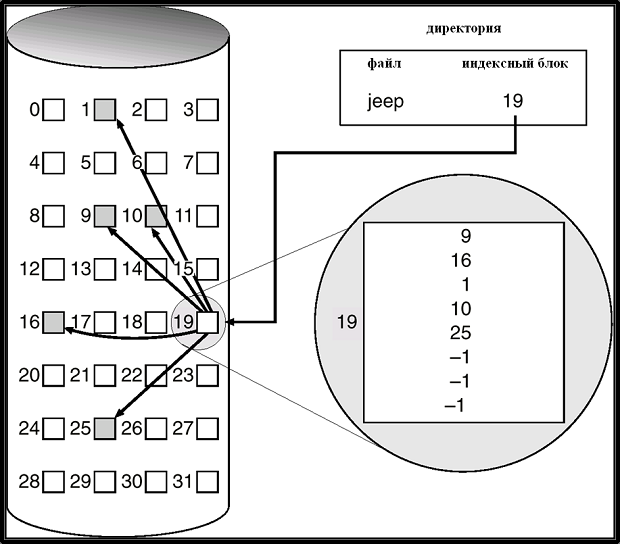
Как видно из схемы, при индексируемом размещении блоки файла могут быть расположены как угодно разрозненно, но индексный блок содержит все ссылки на них. Ссылка на блок данных может быть выбрана непосредственно из индексного блока, без какого-либо поиска.
Определенная опасность такого размещения в том, что на индексный блок ложится критическая нагрузка: если его целостность будет нарушена, файл восстановлению не подлежит. Именно поэтому в UNIX команда rm, удаляющая файл, "фатальна" для него.
Таким образом, при индексируемом размещении файлов необходима индексная таблица. Преимущество такого метода размещения - возможность произвольного доступа; отсутствие внешней фрагментации. Накладными расходами является индексный блок.
При отображении логического адреса в физический, если ограничить максимальный размер файла 256 K словами, а размер блока - 512 слов, то для индексной таблицы требуется только один блок. Логический адрес будет иметь вид (Q, R), где Q - смещение в индексной таблице, R - смещение в блоке.
При отображении логического адреса в физический для файла неограниченной длины (при размере блока – 512 слов) может использоваться ссылочная схема – в список связываются блоки индексной таблицы. В данном случае логический адрес будет иметь вид (Q1, R1), где Q1 = номер блока индексной таблицы; R1 = (Q2, R2), где Q2 - смещение в блоке индексной таблицы, R2 смещение в блоке файла.
В системе UNIX используется комбинированная схема индексного размещения файлов: возможна одноуровневая адресация данных через индексные блоки, двухуровневая (индексные блоки адресуют другие индексные блоки, а те, в свою очередь, - блоки данных), трехуровневая и т.д. Данная схема иллюстрируется на рисунке:
