

18. Последовательный поиск
Последовательный метод поиска называют также методом последовательного перебора. Это самый универсальный, наиболее простой и самый длительный метод поиска. Последовательный поиск можно использовать при любом способе организации информационного массива, для любых структур данных, при любой форме аргумента поиска. В процессе поиска осуществляется последовательное обращение к каждой записи массива и при этом определяется, удовлетворяет ли данная запись критерию выдачи.
При одноаспектном поиске по совпадению в неупорядоченном информационном массиве сопоставление ключей записей и аргумента поиска продолжается до тех пор, пока не будут просмотрены все N записей массива. Записи с искомыми ключами выдаются пользователю или передаются прикладным программам для дальнейшей обработки.
Последовательный поиск в массиве из N записей требует в среднем (N + 1)/2 сравнений (единица в числителе появляется при нечетном N). В худшем случае, когда искомая запись окажется последней в массиве или ее не будет там вовсе, потребуется N сравнений.
Последовательный поиск — единственно возможный в неупорядоченных неструктурированных массивах. Однако следует помнить, что при больших объемах информационных массивов этот поиск будет настолько длительным, что может оказаться совершенно непригодным. Точнее, в таком случае непригодным оказывается не метод поиска, а организация информационного массива. Большие массивы информации обязательно должны быть либо упорядочены, либо, что еще лучше, структурированы.
Процедура последовательного поиска в неупорядоченном массиве может быть несколько ускорена.
Любой алгоритм поиска содержит блок проверки на окончание массива. Проверка обычно осуществляется всякий раз перед обращением к очередной записи. Однако проверка на окончание массива может осуществляться не при каждом сравнении. Для этого в конец массива включается (N + 1)-я фиктивная запись с ключом, равным искомому. Тогда проверка на окончание массива осуществляется лишь при совпадении аргумента поиска со значением ключа текущей записи. Если эта запись находится внутри массива, то поиск заканчивается удачно и нужная запись считается найденной. Если же эта запись оказалась (N+1)-й, то поиск считается неудачным, т.е. нужной записи нет в массиве.
Последовательный поиск в неупорядоченном массиве потребует меньше времени, если для массива организован общий справочник Так как объем справочника существенно меньше объема основного массива, то и поиск в нем будет происходить быстрее.
19. Ускоренные методы поиска. Двоичный поиск. Блочный поиск
Двоичный поиск, или, как его еще называют, бинарный или дихотомический поиск, является одним из самых быстрых. Первое обращение осуществляется к записи, расположенной в середине массива, упорядоченного по возрастанию значений ключей записей . После сравнения ключа записи (К) с аргументом поиска (А) определяется, к какой части массива следует обращаться дальше. Если значение ключа записи больше значения аргумента поиска, то следующее обращение осуществляется к записи, расположенной в середине первой части массива. В противном случае обращение происходит к записи, расположенной в середине второй части массива. Указанная процедура повторяется для 1/4, 1/8, 1/16 т.д. массива до тех пор, пока не будет найдена искомая запись или не станет пустым интервал, в котором осуществляется поиск.
Недостаток метода в том, что между каждыми двумя обращениями необходимо выполнять вычисления для определения адреса или номера следующей записи, которую следует читать.
Чтобы найти нужную запись в массиве из N записей, в среднем требуется [log2N] - 1 сравнений. В худшем случае понадобится [log2N] + 1 сравнений.
Блочный
поиск
состоит
в том, что массив, упорядоченный по
возрастанию значений ключей записей,
разбивается
на определенное число блоков.
Для поиска потребуется наименьшее
время, если число блоков равно
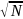 .
Здесь
N
— общее
число записей в массиве. Число записей
в блоке при этом также равно
.
.
Здесь
N
— общее
число записей в массиве. Число записей
в блоке при этом также равно
.
В процессе поиска аргумент поиска А сравнивается последовательно с последними записями блоков. Если при сравнении оказывается, что значение аргумента поиска А меньше, чем ключ последней записи очередного блока, то ключи всех записей этого блока последовательно сравниваются с А. При нахождении нужной записи она передается на дальнейшую обработку. Если нужная запись не найдена, то в алгоритме можно предусмотреть выдачу сообщения о неудачном окончании поиска. Схема блочного поиска приведена на рис. 12.2.
Число записей в последнем блоке массива может оказаться не равным числу записей в остальных блоках, поэтому поиск элемента в последнем блоке (его последовательный просмотр) удобно описывать отдельным алгоритмом.
Для нахождения нужной записи требуется сравнений. В худшем случае понадобится 2 сравнений. Худшим окажется тот случай, когда нужная запись оказывается в последнем блоке и занимает в нем первую позицию (при последовательном просмотре этого блока с конца) или последнюю позицию (при последовательном просмотре этого блока с начала). В массиве из 10000 записей при этом потребуется 199 просмотров.
Возможны различные модификации этого алгоритма. Так, очередное обращение может осуществляться не в конец блока, а в его начало, т.е. к его первой записи. Последовательный просмотр текущего блока также возможен с его конца или начала. Ускоренные методы поиска дают хорошие результаты только при последовательном представлении данных и фиксированной длине записей. При использовании для хранения данных связанного представления на вычисление адреса или номера очередной записи необходимо дополнительное время. Ускоренные методы Поиска следует применять лишь к массивам, хранящимся в ОП ЭВМ. При поиске в массивах данных, хранящихся на ВЗУ, между двумя последовательными сравнениями потребуется перемещение носителя или механизма доступа.
Поиск, аналогичный блочному, обеспечивается системой многоуровневого справочника (см. п. 13.3). Однако при этом расходуется дополнительная память для хранения справочника и затрачивается машинное время на его ведение.