

-
Побудова моделі Decision Tree Mining Model:

Рис. Налаштування для побудови дерев рішень

Рис. Візуалізація моделі дерева рішень
-
Побудова моделі Hierarchical Clustering Mining Model

Рис. Налаштування для побудови моделі Hierarchical Clustering Mining Model
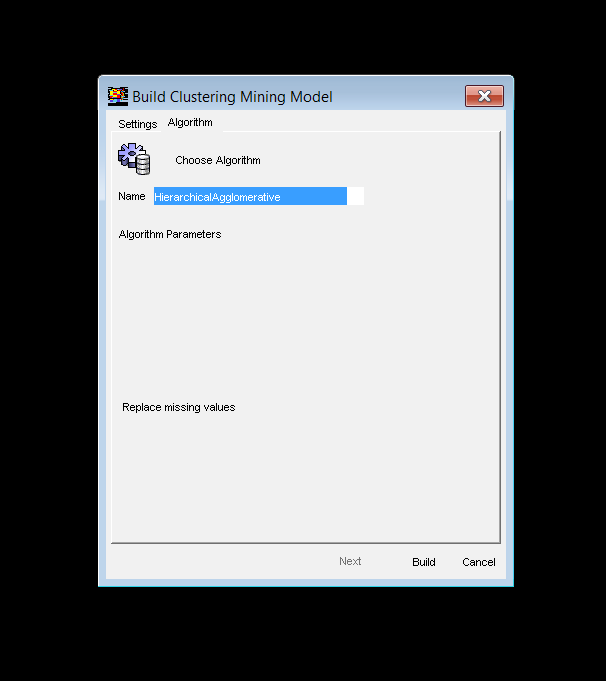
Рис. Налаштування для побудови моделі Hierarchical Clustering Mining Model

Рис. модель Hierarchical Clustering Mining Model
-
Побудова Vector Machine Model


Support Vector Machine Model Report
Meta data
Relation: systema_pogshennya.symbolic
Contains 5 attributes:
-
процентная_ставка, type = categorical
-
высокая
-
средняя
-
низкая
-
-
период_предоставления, type = categorical
-
десять_лет
-
двадцать_лет
-
тридцать_лет
-
-
прописка, type = categorical
-
киевская
-
не_киевская
-
-
история_клиента, type = categorical
-
позитивная
-
негативная
-
отсутствует
-
-
ипотечный_кредит, type = categorical
-
давать
-
не_давать
-
Number of support vectors: 14
-
высокая,десять_лет,не_киевская,негативная,не_давать
-
высокая,двадцать_лет,киевская,негативная,не_давать
-
высокая,тридцать_лет,киевская,позитивная,давать
-
высокая,десять_лет,киевская,позитивная,давать
-
высокая,двадцать_лет,киевская,позитивная,давать
-
высокая,двадцать_лет,не_киевская,негативная,не_давать
-
высокая,десять_лет,не_киевская,отсутствует,не_давать
-
высокая,тридцать_лет,киевская,позитивная,давать
-
высокая,тридцать_лет,киевская,позитивная,давать
-
высокая,тридцать_лет,не_киевская,отсутствует,не_давать
-
высокая,тридцать_лет,киевская,позитивная,давать
-
высокая,двадцать_лет,не_киевская,негативная,не_давать
-
высокая,десять_лет,не_киевская,негативная,не_давать
-
высокая,десять_лет,не_киевская,негативная,не_давать
Number of coefficients: 14
-
1.0
-
1.0
-
1.0
-
0.5286220512935731
-
1.0
-
-1.0
-
-1.0
-
-1.0
-
-1.0
-
-0.5286220512935731
-
-1.0
-
-1.0
-
-1.0
-
-1.0
Absolute coefficient: 0.24987490475177765
Найгіршими варіантами здійснення операції давати чи не давати є пункти з позитивним числами. А найкращими варіантами є пункти з негативними числами.
Найгіршим варіантом не_давати є пункт 6.7.8.9.11.12.13.14.15, а найкращим варіантом є пункти 1.2.3.4.5.
Реализация алгоритмов построения unsupervised моделей

Бібліотека алгоритмів.
Apriori TID на основании реализации алгоритма Apriori в Xelopes

Алгоритм KMeans

Дивизимный алгоритм кластеризации
Аггломеративный алгоритм кластеризации
Контрольные вопросы
-
Что такое unsupervised модели.
UnsupervisedMiningModel є базовою моделлю для всіх керував моделі інтелектуального аналізу даних і, отже, не містить спеціальних реалізації моделі. Він не забезпечує реалізацію applyModel метод. Реалізація applyModelFunction має дуже загальний характер. Давайте подивимося, як вона працює. UnsupervisedMiningModel містить класифікатор як внутрішня мінлива класифікатора. класифікатора представлена через простий інтерфейс класифікатором (вже згадувалося вище), які У свою чергу, містить метод застосовується:
public interface Classifier
{
public double apply(MiningVector miningVector) throws MiningException;
} Таким чином, applyModelFunction метод SupervisedMiningModel просто викликає застосовувати в класифікатор:
public double applyModelFunction(MiningVector miningVector)
throws MiningException
{
// Run inner transformations (e.g. missing values replacement,
outlier treatment):
if (miningTransform != null) {
MiningVector transMiningVec = miningTransform.transform(
miningVector);
transMiningVec.setMetaData( miningTransform.transform(
miningVector.getMetaData()) );
miningVector = transMiningVec;
};
// Apply classifier:
return classifier.apply( miningVector );
}
Наступні зауваження важливі для правильного застосування керував моделі інтелектуального аналізу даних для Нові дані: 1. MiningVector передається applyModelFunction повинні мати ті ж мета-дані, як потік гірської введення даних для навчання. Тим більше, вона повинна містити класифікація атрибутів, навіть якщо вона не містить значущих цінностей. 2. З еквівалентності мета-даних в 1. Крім того, він випливає, що якщо навчання даних була перетворена зовнішні перетворення, перш ніж buildModel був викликаний метод, Потім miningVector (одного і того ж мета-дані в якості навчальних даних) також повинні бути перетвориться ж зовнішньої трансформації. Найпростіше це можна зробити, наступна конструкція:
MiningVector miningVector = miningVector0;
if ( modelMetaData.isTransformed() ) {
miningVector = modelMetaData.getMiningTransformationActivity().
transform(miningVector0);
};
Тут miningVector0 є видобуток вектора, забив який має той же мета-дані в якості навчальних даних. Тепер miningVector є вектором, який насправді передається applyModelFunction. ModelMetadata є мета-дані контролюється видобуток Модель (зберігається в гірській настройки моделі). Якщо мета-даних не було трансформуються, ми можемо працювати з вихідними даними, в іншому випадку до miningVector0 ж зовнішні перетворення, щоб навчання дані повинні бути застосовані. Таким же чином, статична і динамічних перетворень може бути застосована до видобутку вхідні потоки гірських векторів щоб бути зарахований. 3. Метод застосовується в XELOPES 1,0-раніше підтримується у версії 1.1. Він закликає applyModelFunction методом внутрішньо. Метод застосовується позначений як застарілий і applyModelFunction повинні використовуватися замість цього. 4. Метод applyModel кидає виняток у SupervisedMiningModel (а також в більшість її реалізації), так як потрібно функціональність вже повністю знаходиться в applyModelFunction.
Деякі керував моделі інтелектуального аналізу даних, особливо дерева рішень, мають менш обмежувальним Вимоги по мета-дані нових векторів даних (наприклад, різна кількість атрибутів, немає цільового атрибута потрібно). Тим не менш, особливо з-за перетворення, які в основному використовується, переконайтеся, що мета-дані з додатків і навчальних даних має таку ж структуру (Використовується також трансформувати методи пакет Transform для цього).