

Радиальный ввод/вывод
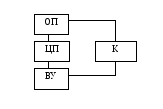
В отличие от магистрального ввода/вывода имеется отдельное адресное пространство. Это значит ВУ может иметь один и тот же адрес, что и ячейка памяти, использующая команды в/в.
Микропроцессоры.
Выделяют два основных направления:
- однокристальные
- секционированные
Секционированные микропроцессоры:
на одном кристалле выполнен полностью микропроцессор (мп) на ограниченное кол-во разрядов ( например 4) Секции соединяются между собой , следовательно происходит наращивание разрядности мп до требуемого числа разрядов. Программирование ведется на микропрограммном уровне.
Однокристальные микропроцессоры:
весь процессор выполнен на одном кристалле. Программирование ведется на уровне машинных команд. На 1-ой ступени развития целиком мп не удавалось выполнить на одном кристалле, тогда мп был разделен «горизонтальными плоскостями» на несколько кристаллов.
Микропроцессоры серии INTEL.
|
м/п |
Год выпуска |
Частота МГц |
Кол-во транзисторов тыс.шт |
Разряд шины |
Размер адресного пространства |
Примечания |
|
Intel 8086 |
1978 |
5-10 |
29 |
Внутр внешн 16/16 |
1Мбайт |
20 разрядов адресная шина |
|
Intel 8088 |
1980 |
5-8 |
29 |
16/8 |
1Мбайт |
Используем в PC-XT |
|
80286 |
1982 |
10-16 |
134 |
16/16 |
16Мбайт |
Шина адреса 24 разряда, исп в PC-AT |
|
80386DX |
1985 |
20-33 |
275 |
32/32 |
4Гбайт |
Шина адреса 32 разряда |
|
80386SX |
1988 |
20-30 |
275 |
32/16 |
4Гбайт |
|
|
80486DX |
1989 |
25-50 |
1200 |
32/32 |
4Гбайт |
|
|
80486DX2 DX4 |
|
До 133 |
|
|
|
|
|
80486SX |
1991 |
До 33 |
1200 |
32/32 |
4Гбайт |
|
|
Pentium |
1993 |
150-200 |
3.1 млн |
32 |
4Гбайт |
|
|
Pentium Pro |
1995 |
150-200 |
5.5 млн +15.5млн или 31млн |
32 |
64Гбайт |
5.5 млн на осн кристалле 15.5млн(КЭШ 256Кб) 31млн(КЭШ 500Кб) |
|
Pentium MMX |
1996 |
166-266 |
4.5 млн. |
32 |
64 Гбайт |
|
|
Pentium 2 |
1997 |
233-466 |
7 млн. |
32 |
64 Гбайт |
|
|
Celeron |
1988 |
266-300 |
|
|
|
|
|
Pentium III |
1999 |
500-1000 |
8.2 млн |
----//---- |
----//---- |
|
|
Pentium IV Prescott |
2000
|
2-3 ГГц
от 3 ГГц |
55 млн
100 млн |
32
|
|
|
|
Pentium M
|
2003 |
1-2 ГГц |
77-144 млн |
32 |
|
|
|
Core Yonah
|
2004
|
1-2 ГГц
|
155 млн
|
32
|
|
|
|
Core 2 Solo |
2006 |
1,6-3 ГГц |
|
64 |
|
|
INTEL 8086,8088
Впервые идет совмещение обработки команд во времени.

Выделяются 2 устройства: операционное устройство (ОУ) и устройство шинного интерфейса (УШИ). УШИ предназначено для вычисления адресов и формирования запросов к памяти (ОП) к ВУ. В УШИ включён буфер команд емкостью 6 байт (очередь команд). Как только в буфере команд освободится 2 байта (внешняя шина данных и ширина выборки ОП 2 байта) УШИ формирует опережающий запрос в память за командами. ОУ выполняет команды, находящиеся в буфере команд. Если требуется обращение к памяти за операндами или по записи результата, то ОУ выставляет запрос к УШИ. Если УШИ свободно, то запрос выполняется сразу же, если УШИ занято выборкой команд, то после получения 2-х очередных байт обрабатывается запрос от ОУ. Т.о. выбор следующей команды начинается не по завершению предыдущей команды, а по наличию 2х свободных байт в буфере команд- принцип опережающей обработки. Снижение производительности происходит из-за появления команд перехода. При появлении команд перехода содержимое буфера обнуляется и буфер команд заполняется с команды, на которую осуществляется переход. Мультиплексированы шины данных и шины адреса.
МИКРОПРОЦЕССОР 8088
Внешняя шина данных 8 разрядов для совместимости с ранее разработанными ВУ. Для реализации плавающей точки в м/п 8086 и в 8088 для повышения производительности на материнской плате мог отдельно устанавливаться мп, аппаратно реализующий операции с плавающей точкой.
|
Тип операции |
8087 Мкс
|
8086 и 8088 эмуляция мкс
|
|
+ |
17-18 |
1600
|
|
* |
27 |
2100 |
|
√ |
36 |
19000 |
|
Exp x |
130 |
17100 |

INTEL 80286
1.В отличие от 8086/8088 шина адреса и шина данных не мультиплексированы во времени ( своя ША и ШД)
2. Разработчики предусмотрели реальный и защищенный режим. В защищённом режиме имеется возможность использования мультипрограммирования.
3. Конвейерная обработка команд
 Конвейерная
обработка на уровне команд:
Конвейерная
обработка на уровне команд:
К аждый
этап машинной команды обрабатывается
на отдельном блоке. На 1-м такте 1-я команда
подается на первый блок, то есть реализует
1-й этап(выборка команды из памяти). Во
2-м такте 1-я команда переходит на 2-й этап
, а 2-я команда поступает на первый этап.
В 3-ем такте, 1-я команда на 3 этапе, 2-я
команда на 2-ом этапе, 3-я команда на 1-ом
этапе. Т.е. конвейер команд аналогичен
технологическому конвейеру. После
заполнения конвейера каждый такт на
конвейере заканчивает обрабатываться
очередная команда. Поэтому говорят, что
за первый такт выполняется 1 команда.
Потеря производительности происходит
в следствие команд перехода, когда
содержимое конвейера обнуляется и в
следствии информационных конфликтов
аждый
этап машинной команды обрабатывается
на отдельном блоке. На 1-м такте 1-я команда
подается на первый блок, то есть реализует
1-й этап(выборка команды из памяти). Во
2-м такте 1-я команда переходит на 2-й этап
, а 2-я команда поступает на первый этап.
В 3-ем такте, 1-я команда на 3 этапе, 2-я
команда на 2-ом этапе, 3-я команда на 1-ом
этапе. Т.е. конвейер команд аналогичен
технологическому конвейеру. После
заполнения конвейера каждый такт на
конвейере заканчивает обрабатываться
очередная команда. Поэтому говорят, что
за первый такт выполняется 1 команда.
Потеря производительности происходит
в следствие команд перехода, когда
содержимое конвейера обнуляется и в
следствии информационных конфликтов
R
 1
+ R2 R1
1
+ R2 R1


R 3
+ R1 R3
3
+ R1 R3
До тех пор пока результат для 1-й команды не будет записан в R1 вторая команда не может считывать операнды из R1 т.е. происходит блокирование конвейера. Для м/п INTEL 80286 число ступеней конвейера равно 4.
INTEL 80386 DX
Первый 32-х разрядный м/п. Уже в PC впервые поддерживается Windows. Работает как в реальном , так и в защищенном режиме. Поддерживается виртуальный режим м/п 8086 ( если параллельно запущенно несколько задач. то каждая задача обрабат. на м/п 8086
INTEL 80386 SX
Уменьшены внешние шины данных с 32 до 16 разрядов, было вызвано совместимостью с ВУ, которые работали с м/п 80286
INTEL 80486 DX
-
Впервые сопроцессор с плавающей точкой был встроен в кристалл м/п. В предыдущих моделях сопроцессор с плавающей точкой реализован на отдельном кристалле. Сопроцессор стал работать на тактовой частоте основного процессора и произошло увеличение производительности в 2 раза.
-
Внутрь самого кристалла был встроен КЭШ 1-го уровня, его емкость 8 Кбайт. КЭШ 2-го уровня располагалась отдельно на материнской плате и его объем 256Кбайт и 512Кбайт. Впервые КЭШ на материнской плате стал использоваться совместно с 80386 микропроцессором.
-
Был усовершенствован механизм обработки команд, используется 5-ти ступенчатый конвейер, в среднем обеспечивается обработка 1-й команды за 1 такт.
DX2 – удвоение тактовой частоты
DX4 – утроение тактовой частоты
PENTIUM
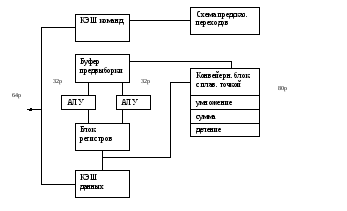
-
Впервые появился отдельно КЭШ команд и КЭШ данных, каждый по 8Кбайт.
-
Впервые появляется суперскалярная обработка команд. В структуре имеется 2 АЛУ, которые параллельно обрабатывают независимые команды.
-
Впервые аппаратно реализован блок предсказания переходов.
-
Операции с плавающей точкой обрабатываются в конвейерном режиме.
PENTIUM PRO
1. В кристалле встроен КЭШ 1-го уровня на 16 Кбайт и КЭШ 2-го уровня либо на 256Кбайт либо на 512Кбайт. КЭШ 2-го уровня работает на тактовой частоте самого м/п, т.к встроена в кристалл.
2. В следующей модели фирма Intel отказалась от встроенного КЭШ 2-го уровня в кристалле, т.к. увеличился процент брака.
3. В Pentium Pro используют 14-ступенчатый конвейер.
4. В Pentium Pro (c него начинается серия Р6) используется конвейер с изменяемой последовательностью команд. Зависимая команда, поступающая на вход конвейера , не сдерживает выполнение следующей за ней независимой команды в окне просмотра. В предыдущих моделях зависимая команда блокировала выполнение всех следующих за ней команд.
PENTIUM MMX
Структура соответствует Pentium, однако увеличен КЭШ 1-го уровня до 32Кбайт (16 КЭШ команд +16 КЭШ данных)
Добавлено 57 новых команд для обработки видео изображения.
PENTIUM 2
Это есть Pentium Pro + Pentium MMX. Однако КЭШ 2-го уровня вынесен из кристалла и помещен на подложку в одном корпусе с основным кристаллом, работал на 0.5 тактовой частоте.
CELERON
Из подложки удален КЭШ 2-го уровня. Резко падает производительность системы. Начиная с модели 300А и выше, встраивается КЭШ внутрь кристалла на 128 Кбайт, который работает на частоте ЦП.
PENTIUM III
Структура Pentium 2 , добавлены команды для обработки видео изображения.
PENTIUM 4
В последующих моделях Pentium III КЭШ встраивается в кристалл на 256 Кбайт. Все Pentium 4 : КЭШ в кристалле.
-
КЭШ 1-го уровня включает в младших моделях 8Кбайт данных, 12 Кбайт КЭШ, которая хранит микрокоманды. КЭШ 2-го уровня встроен в кристалл
-
Число ступеней конвейера 20.(гиперконвейерная обработка) В КЭШ 1-го уровня поступают декодированные команды( хранится в КЭШ 1-го уровня микропрограмма), и за 1 такт декодирует одновременно 3 команды. В КЭШ хранится несколько цепочек микрокоманд. Если направление перехода выбрано не верно, происходит обращение в КЭШ 1-го уровня и выбирается другая цепочка микрокоманд.
-
Память расширена до 16 Кбайт( в последних моделях)
-
Существует 2 параллельно работающих АЛУ. С 2002г. Pentium 4 оснащается специально BIOS, который поддерживает гипертрейдинг: т.к. число блоков конвейера велико, то одновременно часть блоков может простаивать. Потому эти свободные блоки загружаются другой задачей.
PRESCOTT
31 ступень конвейера (гиперконвейрная обработка). КЭШ в кристалле увеличена до 1 Мб. КЭШ 3-го уровня 2Мб помещен на материнскую плату. Появляется новая обработка – гипертрейдинг. Чтобы заполнить 20-30 ступеней в КЭШ 1-го уровня находятся трассы микропрограмм. Гипертрейдинг – это псевдомультипрограммный режим, т.е на свободные блоки конвейера запускают вторую задачу, т.е одновременно обрабатываются 2 задачи.
PENTIUM D
На одной подложке (кристалле) помещены 2 ядра Prescott (каждый со своим КЭШ), отключив гипертрейдинг.
PENTIUM M
КЭШ 1-го уровня увеличена до 64 Кб. (архитектура P6 (продолжение Pentium III) 32Кб команд, 32Кб данных. КЭШ 2-го уровня 1-2Мб встроен в кристалл. Количество обрабатываемых блоков 9 штук)
CORE 2
КЭШ 1-го уровня увеличен до 2-4 Мб. КЭШ команд 32 Мб, КЭШ данных 32 Кб. Добавляется четвертый простой декодер. Число обрабатываемых блоков 11 штук : АЛУ с фиксированной точкой 3 штуки по 64 разряда, 2 шт. АЛУ с плавающей точкой 128р. Команды видеорежима 3 блока 128р. 3 блока обращения к памяти. Intel впервые в Core и Core 2 для двуядерных процессоров использовал общую КЭШ 2-го уровня. В Core 2 имеется связь между отдельными ядрами.