

ГОСУДАРСТВЕННОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ МОСКОВСКОЙ ОБЛАСТИ «Международный университет природы, общества и человека «Дубна»
Факультет естественных и инженерных наук
Кафедра прикладной математики и информатики
КУРСОВАЯ РАБОТА
ПО
дисциплине «Теория вероятностей и математическая статистика»
ТЕМА: «Исследование статистической зависимости количества потребления бензина от количества автомобилей»
Выполнил: студент группы 2151
2 курса факультета ЕиИН
Вяземский А. А.
Руководитель:
Иноземцева Н. Г.
(Доктор физмат наук, профессор)
Барминская Л. Г.
(ст. преподаватель)
Дата защиты:________________________
Оценка: ____________________________
___________________________________
(подпись руководителя)
2010
Содержание
Введение 3
Постановка задачи 4
Теоретическая часть 5
Исходные данные и их обработка 15
Корреляционный анализ 17
Регрессия 24
Проверка гипотез статистиками 29
Метод доверительных интервалов 30
Заключение 33
Список литературы 34
Введение
Математическая статистика — наука о математических методах систематизации и использовании статистических данных для научных и практических выводов. Во многих своих разделах математическая статистика опирается на теорию вероятностей, позволяющую оценить надёжность и точность выводов, делаемых на основании ограниченного статистического материала, выборки генеральной совокупности.
Во время статистических наблюдений для каждого объекта в ряде случаев можно измерить значение нескольких признаков. Таким образом, получается многомерная выборка. Если многомерную выборку обработать по значениям отдельного признака, то получится обычная обработка одномерной выборки.
Смысл обработки многомерных выборок состоит в том, чтобы установить связь между признаками. Связи между ними могут быть функциональными, то есть каждому значению одной величины соответствует определенное значение другой величины.
Связь между случайными величинами часто носит случайный характер. Она называется статистической, если изменение одной величины вызывает изменение распределения другой величины. Если среднее значение одной случайной величины функционально зависит от значения другой случайной величины, то такая статистическая зависимость называется корреляционной.
Постановка задачи
Дана выборка, состоящая из 100 пар чисел ( Xi , Yi ), i =1, 2, …, 100.
-
Подобрать пример объекта, для которого Xi , Yi могли бы быть значениями двух признаков, связанных статистической зависимостью. Дать теоретическое обоснование.
-
Построить диаграмму рассеивания. Вычислить выборочные параметры: выборочные средние, выборочные и исправленные дисперсии, средние квадратические отклонения, моды и медианы выборки по X и по Y , корреляционный момент и коэффициент корреляции (по несгруппированной выборке).
-
Построить корреляционную таблицу (7 на 7). Построить полигоны, гистограммы нормированных относительных частот, эмпирические функции распределения по X и по Y, вычислить выборочные параметры (см. п.2) по корреляционной таблице (по сгруппированной выборке).
-
Вычислить параметры для уравнения линейной регрессии Y на X , построить линию регрессии на диаграмме рассеивания.
-
Вычислить параметры для уравнения параболической регрессии, построить найденную параболу на диаграмме рассеивания.
-
Проверить гипотезу о нормальном распределении признака Х.
-
Построить доверительный интервал для математического ожидания по Х.
Теоретическая часть
В данной работе исследуется зависимость потребления бензина в городе от количества автомобилей с помощью методов математической статистики.
Бензин – смесь легких углеводородов с tкип 30-205 °C; прозрачная жидкость, плотность 0,70-0,78 г/см3. Получают главным образом перегонкой или крекингом нефти. Топливо для карбюраторных авто- и авиадвигателей; экстрагент и растворитель для жиров, смол, каучуков.
Автомобиль – транспортная безрельсовая машина главным образом на колесном ходу, приводимая в движение собственным двигателем (внутреннего сгорания, электрическим или паровым). Различают автомобили пассажирские (легковые и автобусы), грузовые, специальные (пожарные, санитарные и др.) и гоночные. Скорость легковых автомобилей до 300 км/ч, гоночных до 1020 км/ч (1993), грузоподъемность грузовых автомобилей до 180 т.
Обычно в любой области науки при изучении двух величин проводятся эксперименты, и задача состоит в том, чтобы на основании экспериментальных точек выявить функциональную зависимость.
Если мы рассматриваем слабо формализованные системы, которые трудно поддаются однозначным и точным описаниям, связь между величинами X и Y изначально корреляционная. Это связано, что Y зависит не только от X, но и от других параметров.
В этом случае, задача состоит в том, чтобы приближённо свести корреляционную связь к функциональной с помощью подбора такой функции, которая максимально возможным способом была бы близка к экспериментальным точкам. Такая функция называется функцией регрессии.
Обычно вид самой функции угадывается, но она зависит от некоторых параметров. Задача статистического и корреляционного анализа состоит в нахождении этих параметров. Для этого и используется метод наименьших квадратов.
Приведем основные определения и понятия из курса теории вероятностей и математической статистики, которые будут задействованы и использованы в данной работе.
Математическая статистика – наука, которая занимается обработкой данных. Во многих своих разделах математическая статистика опирается на теорию вероятностей, позволяющую оценить надежность и точность выводов, делаемых на основании ограниченного статистического материала (выборки).
Статистика – это наука, которая занимается получением, обработкой, а также анализом данных и публикацией информации, характеризующей количественные закономерности жизни общества в неразрывной связи с их качественным содержанием. В более узком смысле статистика – это совокупность данных о каком-либо процессе или явлении. Задача математической статистики состоит в создании методов сбора и обработки статистических данных для получения научных и практических выводов. Установление закономерностей, которым подчинены массовые случайные явления, основано на изучении методами теории вероятностей статистических данных – результатов наблюдений.
Генеральной совокупностью называют совокупность объектов, из которых производится выборка.
Для того чтобы по данным выборки можно было судить об изучаемом признаке генеральной совокупности, необходимо, чтобы объекты выборки правильно его представляли; т.е. выборка должна быть репрезентативной (представительной). В силу закона больших чисел можно утверждать, что выборка будет репрезентативной, если ее осуществлять случайно: каждый объект выборки отобран случайно из генеральной совокупности, если все объекты имеют одинаковую вероятность попасть в выборку.
Выборочной совокупностью (выборкой) называют совокупность случайно отобранных объектов.
Репрезентативность – главное свойство выборки, состоящее в близости ее характеристик (состава, средних величин и т.д.) к соответствующим характеристикам генеральной совокупности, из которой отобрана выборка.
Таким образом, статистическими методами пользуются для выявления закономерностей наблюдений и для проверки соответствия построенных теорий реальных явлений с их фактическим протеканием.
Как уже было сказано выше, существует тесная связь между математической статистикой и теорией вероятностей.
Теория вероятностей – раздел математики, в котором по данным вероятностям одних случайных событий находят вероятности других событий, связанных каким–либо образом с первыми. Теория вероятностей изучает также случайные величины и случайные процессы. Одна из основных задач теории вероятностей состоит в выяснении закономерностей, возникающих при взаимодействии случайных факторов.
У
нас имеется выборка случайных значений,
объем которой равен
 Объемом
совокупности
называют число объектов этой совокупности.
Объемом
совокупности
называют число объектов этой совокупности.
Случайной называют величину, которая в результате испытания примет одно и только одно возможное значение, наперед не известное и зависящее от случайных причин, которые заранее не могут быть учтены.
Случайной величиной называется результат эксперимента или серии опытов, когда результат имеет непредсказуемое численное значение, т.е. событием является непредсказуемое число. Случайные величины бывают двух видов: дискретные и непрерывные.
Дискретной называют случайную величину, которая принимает отдельные, изолированные возможные значения с определенными вероятностями.
Наблюдаемые
значения xi
называются вариантами.
Частотой
 называется число, которое показывает,
сколько раз встречается данный вариант.
Относительной
частотой
называется отношение частоты
называется число, которое показывает,
сколько раз встречается данный вариант.
Относительной
частотой
называется отношение частоты
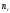 к объему выборки
n.
к объему выборки
n.
Математическим ожиданием M(X) дискретной случайной величины называют сумму произведений всех ее возможных значений на их вероятности:

Дисперсией
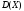 дискретной
случайной величины называют математическое
ожидание квадрата отклонения случайной
величины от ее математического ожидания:
дискретной
случайной величины называют математическое
ожидание квадрата отклонения случайной
величины от ее математического ожидания:

Средним квадратическим отклонением случайной величины X называют квадратный корень из дисперсии:
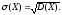
Модой
 называют
варианту, которая имеет наибольшую
частоту.
называют
варианту, которая имеет наибольшую
частоту.
Последовательность вариантов в возрастающем порядке – вариационным рядом.
Медианой
 называют
варианту, которая делит вариационный
ряд на две части, равные по числу вариант.
называют
варианту, которая делит вариационный
ряд на две части, равные по числу вариант.
Начальным моментом порядка k случайной величины X называют математическое ожидание величины Xk:
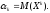
В частности, начальный момент первого порядка равен математическому ожиданию:

Центральным моментом порядка k
случайной величины X называют
математическое ожидание величины
 :
:

В частности, центральный момент первого порядка равен нулю:

центральный момент второго порядка равен дисперсии:

центральный момент третьего порядка равен:

Исправленной выборочной дисперсией называют произведение выборочной дисперсии на исправитель:

Выборочным исправленным средним квадратическим отклонением называют квадратный корень от исправленной выборочной дисперсии:

Корреляционное
поле и корреляционная таблица
являются вспомогательными средствами
при анализе выборочных данных. При
нанесении на координатную плоскость
двумерных выборочных точек получают
корреляционное поле. Для численной
обработки результатов обычно группируют
и представляют в форме корреляционной
таблицы. В каждой клетке корреляционной
таблицы приводятся численности
 тех пар (X,
Y),
компоненты которых попадают в
соответствующие интервалы группировки
по каждой переменной.
тех пар (X,
Y),
компоненты которых попадают в
соответствующие интервалы группировки
по каждой переменной.
Корреляция (от позднелатинского correlatio – соотношение) в мат. статистике – вероятностная (статистическая) зависимость между величинами, не имеющая, вообще говоря, строго функционального характера.
Корреляционным
моментом
 случайных величин X
и Y
называют математическое ожидание
произведения отклонений этих величин
случайных величин X
и Y
называют математическое ожидание
произведения отклонений этих величин
 .
.
Для вычисления корреляционного момента используют формулу:


Две случайные величины Y и X называются коррелированными, если их корреляционный момент отличен от 0; Y и X называются некоррелированными величинами, если их корреляционный момент равен 0.
Коэффициентом
корреляции
 случайных величин X
и Y
называют отношение корреляционного
момента к произведению средних
квадратических отклонений этих величин
случайных величин X
и Y
называют отношение корреляционного
момента к произведению средних
квадратических отклонений этих величин
 .
.
Гистограммой
частот
называется столбчатая диаграмма,
состоящая из прямоугольников, основаниями
которых служат частичные интервалы
длиной h,
а высоты равны частоте
 .
.
Гистограммой относительных частот называется диаграмма, на которой изображены столбцы, при этом ось Х – это интервалы, а ось Y – это относительная частота встречаемости:

Полигоном
частот
называется ломаная, отрезки которой
соединяют точки
 .
Для построения полигона на оси абсцисс
откладывают варианты
.
Для построения полигона на оси абсцисс
откладывают варианты
 ,
а на оси ординат – соответствующие им
частоты
,
а на оси ординат – соответствующие им
частоты
 .
.
Полигоном
относительных частот
называют ломаную, отрезки которой
соединяют точки
 .
Для построения полигона на оси абсцисс
откладывают варианты
.
Для построения полигона на оси абсцисс
откладывают варианты
 ,
а на оси ординат – соответствующие им
относительные частоты
,
а на оси ординат – соответствующие им
относительные частоты
 .
.
Функцией распределения называют функцию, определяющую вероятность того, что случайная величина Х в результате испытания примет значение, меньшее х:

Функцией распределения выборки является эмпирическая функция распределения.
Эмпирической
функцией
распределения называют функцию
 ,
определяющую для каждого значения х
относительную частоту события Х
< х:
,
определяющую для каждого значения х
относительную частоту события Х
< х:

где
 – число вариантов, меньших х;
n – объем
выборки.
– число вариантов, меньших х;
n – объем
выборки.