

Различные модели для определения точности и важности.
Как мы уже отмечали ранее, определенные факторы и связанные идеи очень строгих правил были введены в установки четкого интеллектуального анализа данных, чтобы избежать некоторых из этих недостатков от использования поддержки и достоверности. Этот раздел будет посвящен презентации расширению этих идей для нечеткого варианта.
Определение
10. Достоверный
фактор нечеткого ассоциативного правила
(НАП)
![]() это значение
это значение
![]()
Если
![]() ,
то
,
то
![]()
Если
![]() при
условии согласия, что если
при
условии согласия, что если
![]() ,
тогда
,
тогда
![]() и если
и если![]() ,
тогда
,
тогда
![]()
Определение
11. Нечеткое
ассоциативное правило строгое, тогда,
когда его достоверный фактор и поддержка
больше чем определенные пользователем
два порога minCF
и
minsupp
соответственно. Нечеткое ассоциативное
правило
![]() является
очень строгим, если оба и
является
очень строгим, если оба и
![]() и
и
![]() являются
строгими.
являются
строгими.
Наборы
данных
![]() и
и
![]() значение которого «отсутствие A»
(соответственно С)
в транзакции являются определенными
в обычном случае
значение которого «отсутствие A»
(соответственно С)
в транзакции являются определенными
в обычном случае
![]() и
и
![]() .
Логическую основу этого определения
составляет, что правила
.
Логическую основу этого определения
составляет, что правила
![]() и
и
![]() являются тем же знанием.
являются тем же знанием.
4 Приложение.
Отметим, что пункты «элемент» и «транзакция» являются абстрактными понятиями, которые могут быть представлены как некий вид «объекта» и «подмножества объектов» соответственно. В зависимости от конкретных характеристик АП могут обеспечивать различные виды паттернов. В этой секции мы кратко опишем некоторые экземпляры выполнения этой простой идеи.
Нечеткие ассоциативные правила в реляционной базе данных.
Пусть
![]() множество лингвистических лейблов для
атрибута
множество лингвистических лейблов для
атрибута
![]() .
Будем использовать лейблы, чтобы
именовать соответствующие нечеткие
множества
.
Будем использовать лейблы, чтобы
именовать соответствующие нечеткие
множества
![]()
Пусть
![]() .
Тогда множество элементов с лейблами
из L
связаны
с RE
.
Тогда множество элементов с лейблами
из L
связаны
с RE
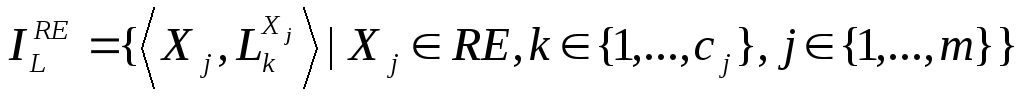
Каждый
экземпляр r
из RE
соотносящийся с FT
множеством обозначим как
![]() с элементами из
с элементами из
![]() .
Каждый кортеж
.
Каждый кортеж
![]() соотносится
с единственной нечеткой транзакцией
соотносится
с единственной нечеткой транзакцией
![]()
![]() ,
,
Такая что
![]()
В этом случае нечеткая транзакция может содержать более одного элемента, соответствующего различным лейблам одного и того же атрибута, потому что это возможно для единственного значения в таблице, чтобы соответствовать более одному лейблу в определенной степени. Тем не менее, наборы элементов ограничены содержанием одного элемента на один атрибут так как в противном случае применение нечетких правил не имело бы смысла.
Пример 3. Пусть r отношения таблицы 5, содержащей возраст и часы рождения 6 человек. Отношение r это экземпляр ER={Age,Hour}.
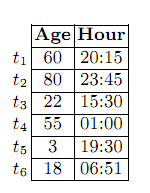
Таблица 5.
Будем использовать множество термов Lab(Age)={Baby, Kid, Very young, Young, Middle Age, Old, Very old} и определим множество термов Lab(Age)={Early morning,
Morning, Noon, Afternoon, Night}.

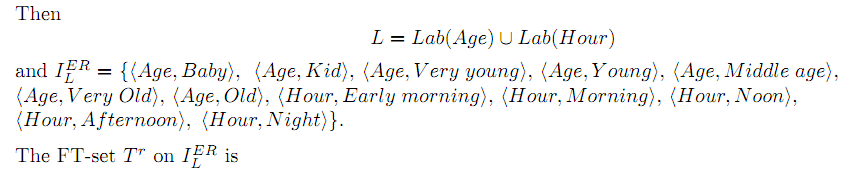
![]()
Столбцы
таблицы 6 определяют нечеткие транзакции
![]() как нечеткие подмножества
как нечеткие подмножества
![]() .
Мы поменяли столбцы и строки местами в
обычном представлении нечетких транзакций
ради пространства. Для примера
.
Мы поменяли столбцы и строки местами в
обычном представлении нечетких транзакций
ради пространства. Для примера
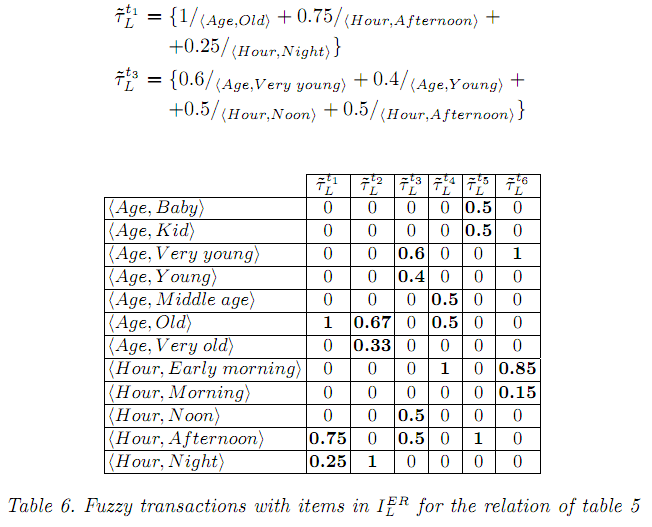
В
таблице 6 строка с элементом
![]() содержит нечеткое множество
содержит нечеткое множество
![]() .
Например
.
Например
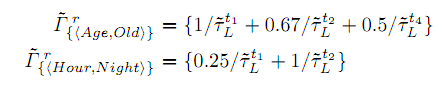
Описание набора элементов с более чем одним нечетким элементом, например
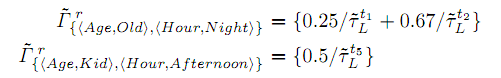
Некоторые
правила, включающиеся нечеткие элементы
в
![]() .
.
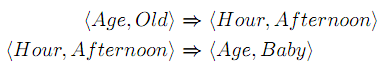
Этот общий подход был проверен на нахождение нечетких ассоциативных правил в нескольких реляционных базах данных.
Заметим, что были рассмотрены только четкие базы данных. Лингвистические термы определенные нечетким множеством в области четких количественных атрибутов. Однако, вполне возможно иметь данные по существу нечеткие, представленные и хранящиеся в одной из существующей нечеткой базы данных. В этих случаях наш подход сохраняется, подходящую работая как в примере разделе 3.2.