

Классы коллекций
В главе описываются базовые типы данных, которые непосредственно поддерживаются языком программирования C++ и включают примитивные числовые и символьные данные, а также массивы, строки и записи. Эти структурированные типы данных являются примерами коллекции (collections) которые сохраняет данные и предоставляют операции доступа, добавляющие, удаляющие или обновляющие элементы данных. Изучению типов коллекций уделяется основное внимание.
Коллекции подразделяются на две основные категории: линейные и нелинейные. На рис. 4.1 приводятся методы доступа к данным для дальнейшего деления категорий и перечисления структур данных, представленных в этой книге. В данной главе приводится краткий обзор каждой коллекции вместе с описанием ее данных, операций и некоторых случаев практического использования.
Линейная (linear) коллекция содержит список элементов, упорядоченных по положению (рис.4.2). В этом списке имеется первый элемент, второй и т.д. Массив с индексом, отражающим порядок элементов, является основным примером линейной коллекции.
Нелинейная (nonlinear) коллекция определяет элементы без позиционного упорядочения. Например, цепочка управления рабочими на заводе или комплект мячей в сетке – это нелинейные коллекции (рис. 4.3).
Класс SeqList является основным типом коллекций. В данной главе описывается реализация этого класса на базе массива.
Когда C++ реализует коллекции как классы, компилятор требует параметры функции, чтобы иметь специфические типы данных, и выполняет тщательную проверку типа на предмет совместимости. Для наиболее общей реализации типов коллекций вводятся классы шаблонов (template) C++.
Классы шаблонов пишутся с использованием параметризованного имени, такого как Т для типа данных, управляемых коллекцией. Когда объявляется какой-либо объект, фактический тип для Т задается как параметр. Шаблоны являются мощным инструментом C++, позволяющим выполнять параметризованное объявление классов. Например, предположим, что класс коллекции имеет массив из 10 элементов.
Первое объявление определяет массив целых. Версия шаблонов не предполагает определенного типа, а позволяет классу использовать параметризованное имя Т для типа элемента массива. Фактический тип указывается во время объявления объекта.
Объявление 1
class Collection
{
……………………….
int A[10]; //массив целых является данным членом
}
Collection object; //A – это массив целых


Объявление 2
template <class T>
class Collection
{
……………
ТА[10]; //параметризованное объявление массива
//задает Т при объявлении объекта
}
Collection<int> object; //А – это массив целых
Collection<char> object; //A – это массив символов
4.1. Описание линейных коллекций
М

Пример парковочного гаража может служить для сравнения списков с возможным прямым доступом и последовательных списков. Следующая диаграмма описывает гараж, в котором рядом с машинами имеется свободный проход. Служащий может выводить машину 3 из гаража, садясь непосредственно в нее и используя свободный проход.

Следующая диаграмма иллюстрирует гараж с последовательной парковкой, в котором все машины паркуются в один ряд. Служащий имеет только последовательный доступ к машине. Чтобы вывести машину 3, он должен переместить машины 0 – 3 в таком порядке:

К

Массив (array) – это коллекция элементов, имеющих один и тот же тип данных, с прямым доступом посредством целого индекса.
Коллекция Array
Данные
Коллекция объектов одного и того же (однородного) типа.
Операции
Данные в каждом местоположении в массиве доступны непосредственно с помощью целого индекса.
Статический массив (static array) содержит фиксированное количество элементов и задается в памяти во время компиляции. Динамический массив (dynamic array) создается с использованием методов динамического распределения памяти и его размер может быть изменен.
Массив – это структура данных, которая может использоваться для хранения списка. В случае с последовательным списком массив позволяет выполнять эффективное добавление элементов в конец списка. Эта структура менее эффективна при удалении элемента, поскольку мы должны часто сдвигать элементы. Такой же сдвиг происходит, когда новые элементы вставляются в массив, хранящий упорядоченный список.

Существует класс Array, расширяющий концепцию простого массива. Этот класс предоставляет новый индексный оператор, который перед сохранением или возвращением данных проверяет, находится ли соответствующий этим данным индекс в допустимом диапазоне. Класс, реализующий такие безопасные массивы, (safe arrays), позволяет клиенту динамически распределять массив во время исполнения приложения.
Символьная строка (character string) – это массив символов с ассоциированными операциями, которые определяют длину строки, склеивают (конкатенируют) две строки, удаляют подстроку и так далее.
Коллекция String
Данные
Коллекция символов с известной длиной
Операции
Имеются операции для определения длины строки, копирования одной строки в другую или их конкатенации, сравнения двух строк, выполнения сопоставления с образцом, ввода и вывода из строк.
Запись (record) – это базовая структура коллекций для сохранения данных, которые могут состоять из разных типов. Для многих приложений различные элементы данных ассоциированы с одним объектом. Например, авиабилет включает такие данные, как номер рейса, номер места, имя пассажира, стоимость, данные об агенте и так далее. Единственный билетный объект – это набор полей разных типов. Коллекция записи связывает поля при обеспечении прямого доступа к данным в отдельных полях.
Коллекция Record
Данные
Элемент с коллекцией полей, возможно, различных типов.
Операции
Точечный оператор (dot operator) обеспечивает прямой доступ к данным в поле.
Коллекции с последовательным доступом
Б

Коллекция List
Данные
Произвольная коллекция объектов одного и того же (однородного) типа.
Операции
Для ссылки на отдельные элементы мы должны идти по списку от его начальной точки, проходя от элемента к элементу до достижения нужного местоположения.
Вставки и удаления изменяют размер списка.
Коллекция линейного списка может иметь любое количество элементов и подразумевает, что эта коллекция будет расширяться или сужаться по мере добавления новых элементов в список или удаления резидентных элементов. Эта структура списка является ограничивающей, когда необходим доступ к произвольным элементам, так как в ней нет прямого доступа. Для доступа к элементам списка необходимо выполнять прохождение элементов от начальной точки в списке. В зависимости от используемого метода, мы можем перемещаться одним из двух способов: слева направо или в обоих направлениях. В этой главе разрабатывается класс, который реализует последовательный список, используя массив. Результирующий список ограничивается размером массива.
Список покупок является примером последовательного списка. Покупатель первоначально создает список, записывая названия товаров. Делая покупки, он вычеркивает названия из списка, когда товары найдены или больше не нужны.
Упорядоченный линейный список (ordered linear list) – это линейный список, данные которого упорядочены относительно друг друга. Например, список
3, 5, 6, 12, 18, 33 расположен в числовом порядке, а список
1, 6, 2, 5, 8 – нет.
Бинарный поиск, описываемый в этой главе, является алгоритмом, использующим упорядоченный список.
Стеки и очереди – это особые версии линейного списка с ограниченным доступом к элементам данных. В стеке (stack) элементы добавляются и удаляются только в один конец списка, называемый вершиной (top). Полка для подносов в столовой – это знакомый пример. Операция удаления элемента из списка называется извлечением из стека (popping the stack). О добавлении элемента в список говорится как о помещении (pushing) элемента в стек.
П
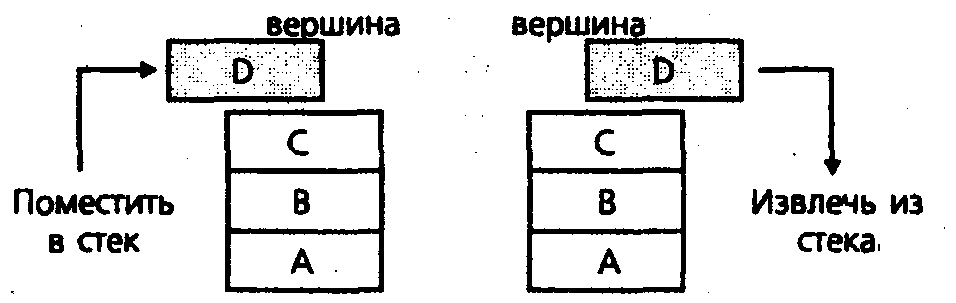
Коллекция Stack
Данные
Список элементов, которые могут быть доступны только на вершине списка.
Операции
Список поддерживает операции push и pop. Push добавляет новый элемент в вершину списка, и pop удаляет элемент из вершины списка.
Стеки вводятся в ряд приложений, которые включают оценку выражений, рекурсию и прохождение дерева. В этих случаях мы просматриваем элементы и затем обращаемся к ним в порядке LIFO. При помощи стека компиляторы передают параметры функциям, а также используют стек для хранения локальных переменных.
О

Коллекция Queue
Данные
Список элементов с доступом в начале и в конце списка.
Операции
Добавление элемента в конец списка и удаление элемента из начала списка.
Очередь является полезной коллекцией для ведения списков очередников. Моделью очереди является очередь обслуживания в банке или обслуживание покупателей в продовольственном отделе. Очереди находят машинное применение в моделирующих исследованиях и осуществляют планирование заданий в рамках операционной системы.
Для некоторых приложений структура очереди изменяется, устанавливая очередность элементов. При удалении объекта из списка определяется элемент с наивысшим приоритетом. Эта коллекция, называемая очередью приоритетов (priority queue), имеет операции insert (вставить) и delete (удалить). Где вставляются данные, является несущественным. Важным является то, что операция delete выбирает элемент с наивысшим приоритетом. В больничном отделении скорой помощи используется очередь приоритетов. Пациенты обслуживаются в порядке поступления, если только их состояние не является угрожающим для жизни, что дает им наивысший приоритет и первоочередной доступ к экстренной медицинской помощи.
Коллекция Queue Priority
Данные
Список элементов, такой, что каждый элемент имеет приоритет.
Операции
Добавление элемента в список. При удалении элемента извлекается элемент с наивысшим приоритетом.
Очереди приоритетов используются для планирования заданий в рамках операционной системы. Задания с наивысшим приоритетом должны выполняться в первую очередь. Очереди приоритетов используются также в моделировании, управляемом прерываниями (event-driven simulation). Например, в практическом приложении в следующей главе выполняется моделирование потока клиентов в банк и из банка. Каждый тип события (появление или уход) вставляется в очередь приоритетов. Самое раннее по времени событие удаляется и обслуживается первым.
В машинной системе файл (file) – это внешняя коллекция, которая имеет ассоциированную структуру данных, называемую потоком (stream). Мы приравниваем file к его stream и сосредоточиваем внимание на потоке данных. Прямой доступ осуществляется только к дисковому файлу, ленточные же файлы являются последовательными. Операция read удаляет данные из потока ввода, а операция write добавляет новые данные в конец потока вывода. Файл часто используется для хранения большого количества данных. Например, во время компиляции программы генерируются большие таблицы и часто сохраняются во временных файлах.
Коллекция file
Данные
Последовательность байтов, ассоциированная с внешним устройством. Данные перемещаются посредством потока к устройству и из него.
Операции
Открытие файла, считывание данных из файла, запись данных в файл, поиск указанного адреса в файле (прямой доступ), закрытие файла.
Универсальная индексация
М


Обычный словарь – это коллекция слов и их определений. Вы ищете слово, используя его как ключ. В структурах данных, коллекция, называемая словарем (dictionary), состоит из набора пар ключ-значение, называемых ассоциациями (associations).
Н
![]()