

2.4 Проблемы однозначности и эквивалентности грамматик
Грамматика, в которой для любой цепочки порождаемого языка существует единственная цепочка вывода, называется однозначной. Грамматика также называется однозначной, если для каждой цепочки символов языка, заданного этой грамматикой, существует единственное дерево вывода. В противном случае грамматика называется неоднозначной.
Рассмотрим некоторую грамматику G ( {+, – , *, /, (, ), x, y}, {S}, P, S):
P: S → S+S | S–S | S*S | S/S | (S) | x | y
Грамматика определяет язык арифметических выражений с четырьмя основными операциями: сложение, вычитание, умножение, деление и скобками.
Для цепочки, принадлежащей данному языку, x*y+x можно построить два варианта левостороннего вывода:
S => S+S => S*S+S => x*S+S => x*y+S => x*y+x
S => S*S => x*S => x*S+S => x*y+S => x*y+S
С точки зрения формального языка, заданного грамматикой, не имеет значения, какая цепочка вывода и какое дерево вывода из возможных вариантов будут построены. Однако в реальных языках структура предложения и его значение (смысл) взаимосвязаны. Это справедливо как для естественных языков, так и для языков программирования. Для языков программирования, которые несут смысловую нагрузку, имеет принципиальное значение то, какая цепочка вывода будет построена для того или иного предложения языка.
Например, если принять во внимание, что рассмотренная здесь грамматика определяет язык арифметических выражений, то с точки зрения семантики арифметических выражений порядок построения дерева вывода соответствует порядку выполнения арифметических действий. В арифметике, как известно, при отсутствии скобок умножение всегда выполняется раньше сложения (умножение имеет более высокий приоритет), но в рассмотренной выше грамматике это ниоткуда не следует — в ней все операции равноправны. Поэтому с точки зрения арифметических операций приведенная грамматика имеет неверную семантику — в ней нет приоритета операций, а кроме того, для равноправных операций не определен порядок выполнения (в арифметике принят порядок выполнения действий слева направо), хотя синтаксическая структура построенных с ее помощью выражений будет правильной.
Такая ситуация называется неоднозначностью в грамматике. Естественно, для построения компиляторов и языков программирования нельзя использовать грамматики, допускающие неоднозначности.
Однозначность — это свойство грамматики, а не языка. Для некоторых языков, заданных неоднозначными грамматиками, иногда удается построить эквивалентную однозначную грамматику (однозначную грамматику, задающую тот же язык).
Например, для рассмотренной грамматики арифметических выражений существует эквивалентная ей однозначная грамматика вида:
G’ ( {+, – , *, /, (, ), x, y}, {S, Т, Е}, P’, S):
P’: S → S+T | S–T | T
T→ T*E | T/E | E
E→ (S) | x | y
Для арифметического выражения x*y+x в этой грамматике можно построить единственный левосторонний вывод:
S => S+T => T+T => T*E+T => E*E+T => x*E+T => x*y+T => x*y+E => x*y+x
В таком случае необходимо решить проблемe: доказать что две имеющиеся грамматики эквивалентны (задают один и тот же язык).
К сожалению, доказано, что проблема эквивалентности грамматик в общем случае с помощью алгоритма неразрешима. Это значит, что не только до сих пор не существует алгоритма, который бы позволял проверить, являются ли две заданные грамматики эквивалентными, но и доказано, что такой алгоритм в принципе не существует, а значит, он никогда не будет создан.
Точно так же неразрешима в общем виде и проблема однозначности грамматик. Это значит, что не существует (и никогда не будет существовать) алгоритм, который бы позволял для произвольной заданной грамматики G проверить, является ли она однозначной или нет. Однако, неразрешимость проблем эквивалентности и однозначности грамматик в общем случае не означает, что они не разрешимы вообще. Для многих частных случаев эти проблемы решены.
2.5 Распознаватели, общая схема распознавателей.
В числе прочих задач компилятор должен определить принадлежность некоторого текста к конкретному языку. В отношении исходной программы компилятор выступает в роли распознавателя, а человек, создавший программу – в роли генератора цепочек этого языка.
Распознаватель – это специальный алгоритм, позволяющий для
некоторой цепочки символов определить, принадлежит ли она заданному языку. Это один из способов задания языка.
Распознаватель входит в состав компилятора и является частью
программного обеспечения компьютера.
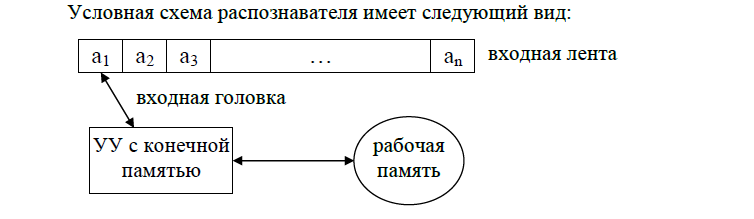
Основные компоненты распознавателя:
входная лента – линейная последовательность клеток, или ячеек, каждая из которых содержит ровно один символ входного алфавита;
входная (считывающая) головка обозревает одну входную ячейку; на каждом шаге работы может сдвигаться на одну ячейку вправо, влево или оставаться на месте;
устройство управления (УУ), которое координирует работу
распознавателя, имеет некоторое множество состояний и конечную
память;
внешняя (рабочая) память может хранить некоторую информацию в процессе работы распознавателя и может иметь неограниченный объем.
Алфавит распознавателя конечен; он включает в себя все допустимые символы входных цепочек, а также некоторый дополнительный алфавит символов, которые могут обрабатываться УУ и храниться в рабочей памяти распознавателя.
В процессе своей работы распознаватель может выполнять некоторые элементарные операции, такие как чтение входного символа, сдвиг головки, доступ к рабочей памяти для чтения или записи информации, изменение состояния УУ.
Работа распознавателя состоит из последовательности шагов, или
тактов. То, каким должен быть этот такт, определяется текущим входным символом, состоянием УУ и символом, извлеченным из памяти. Итак, Такт состоит из следующих моментов:
входная головка распознавателя сдвигается на одну ячейку вправо, влево
или остается на месте;
в память помещается некоторая информация;
изменяется состояние УУ.
В процессе работы распознавателя происходит смена конфигураций.
Конфигурация распознавателя (мгновенное описание) определяется
следующими параметрами:
состояние УУ;
содержимое входной ленты и положение считывающей головки в ней;
содержимое внешней памяти.
Конфигурация называется начальной, если УУ находится в начальном
состоянии, входная головка обозревает самый левый символ на входной ленте, а память имеет заранее установленное начальное содержимое.
Конфигурация называется заключительной, если УУ находится в одном из множества заключительных состояний, а входная головка обозревает правый концевой маркер или сошла с ленты.
Распознаватель допускает входную цепочку символов, если, находясь в начальной конфигурации, в которой данная цепочка записана на входной ленте, он может проделать конечную последовательность шагов, заканчивающуюся одной из его заключительных конфигураций.
Некоторые виды распознавателей могут из начальной конфигурации
проделать различные последовательности шагов, из которых, может быть, лишь некоторые (или даже одна) приведут к заключительной конфигурации.
В таком случае входная цепочка является допущенной.
(q0, α, Z0) ˫* ( qf, λ, Zf)
q0 – начальное состояние УУ
α - цепочка символов
Z0 – начальная внешняя память
qf - заключительное состояние
λ – пустое значение, значит УУ прочитал полностью всю цепочку
Если это получится, то цепочка будет считаться распознанной
Язык, определяемый распознавателем – это множество всех цепочек, которые допускает этот распознаватель.
2.6 Задание языка регулярным выражением V+ α β → ∈ λ Ɐ
Регулярные выражений используют для порождения бесконечных цепочек языка.
Регулярное множество и регулярное выражение для некоторого алфавита V определяется рекурсивно следующим образом:
0 – регулярное выражение, обозначает пустое регулярное множество;
λ – регулярное выражение, обозначает регулярное множество { λ };
Ɐ a ∈ V a – регулярное выражение, обозначает регулярное множество {a};
если p и q – произвольные регулярные выражения, обозначающие
регулярные множества P и Q, то p+q, pq, p* – регулярные выражения, обозначающие соответственно регулярные множества P∪Q, PQ, P*; ничто другое регулярным выражением и регулярным множеством не является.
Иными словами, регулярные множества – это цепочки символов над заданным алфавитом, построенные с использованием операций объединения, конкатенации и замыкания.
При записи регулярных выражений используются круглые скобки, как для обычных арифметических выражений. При отсутствии скобок операции выполняются слева направо с учетом приоритета. Наивысшим приоритетом обладает операция итерации ( обозначается как * - действия повторяются многократно) , затем конкатенации ( «знак умножения» - объединение множест), потом + (выбор «или»).
Все регулярные языки представляют собой регулярные множества. Два регулярных выражения α и β эквивалентны: α = β, если они обозначают одно и то же множество.
Например, α1 = (0+1)*, α2 = (0*1*)*. α1 = α2
П. (0+1)*
L = { λ, 0, 1, 00, 01, 10, 11…..}
G ( {0,1}, {S}, P, S )
S → 0S | 1S | λ