

Базы данных
Назначение и основные компоненты системы баз данных.
Уровни представления баз данных; понятия схемы и подсхемы.
http://mydocx.ru/9-82053.html
Модели данных.
Иерархическая, сетевая и реляционная модели данных; схема отношения.
https://infopedia.su/8x7226.html
http://www.mstu.edu.ru/study/materials/zelenkov/ch_4_1.html#4_1_2
Язык манипулирования данными для реляционной модели;
Реляционная алгебра и язык SQL.
Проектирование реляционной базы данных на основе функциональных зависимостей.
Функциональные зависимости, декомпозиция отношений, транзитивные зависимости,
Проектирование с использованием метода «сущность – связь».
Создание и модификация базы данных.
Поиск, сортировка, индексирование базы данных.
Создание форм и отчетов.
Физическая организация базы данных.
Хешированные, индексированные файлы;
Защита баз данных.
Целостность и сохранность баз данных.
Назначение и основные компоненты системы баз данных.
База данных (БД) – совокупность структурированных взаимосвязанных данных, относящихся к определённой предметной области и организованных таким образом, что эти данные могут быть использованы для решения многих задач многими пользователями.
Система управления базами данных (СУБД) - это совокупность программ и языковых средств, предназначенных для управления данными в базе данных, ведения базы данных и обеспечения взаимодействия её с прикладными программами.
Система БД включает два основных компонента: собственно базу данных и систему управления базами данных – СУБД (рис. 1.6). Большинство СОД включают также программы обработки данных (прикладное программное обеспечение, ППО), которые обращаются к дан-ным через СУБД.

В соответствии с рис. 1.6 СУБД обеспечивает выполнение двух групп функций:
• предоставление доступа к базе данных прикладному программному обеспечению (или квалифицированным пользователям);
• управление хранением и обработкой данных в БД.
Таким образом, обращение к базе данных возможно только через СУБД.
БД предназначена для хранения данных информационной системы. Пользователи обращаются к базе данных обычно не напрямую через средства СУБД, а с помощью внешнего интерфейса – приложения, входящего в состав АИС. Если пользователей можно разделить на группы по характеру решаемых задач, то приложений может быть несколько (по количеству задач или групп пользователей). Например, для библиотеки можно выделить три группы пользователей: читатели, которым нужно осуществлять поиск книг по различным признакам; сотрудники, выдающие и принимающие у читателей книги (библиотекари) и сотрудники отдела комплектации, осуществляющие приём новых книг и списание старых.
Уровни представления баз данных; понятия схемы и подсхемы.
Создание базы данных предполагает интеграцию данных, предназначенных для решения нескольких прикладных задач разных пользователей. Соответственно, при интеграции данных должны учитываться требования к данным каждого пользователя, основанные на его представлении о данных и связях между ними. Далее эти требования должны обобщаться в единое представление, которое и будет служить основой для построения единой базы данных (рис. 2).
Обобщение представлений всех пользователей о данных называется концептуальной моделью (схемой) БД. Концептуальная модель представляет информационное описание предметной области с учетом логических взаимосвязей, поэтому её еще называют инфологической (информационно-логической) моделью. В модели отсутствуют какие-либо понятия, связанные с ЭВМ, памятью ЭВМ, способами размещения данных в памяти ЭВМ, и, по сути, это модель только предметной области.
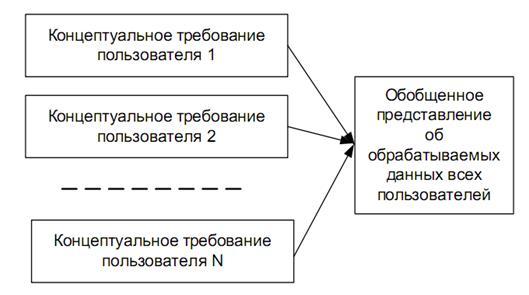
Рис. 2 Обобщение представления пользователей о данных
Как уже отмечалось, для создания базы данных и работы с ней используется система управления базами данных. Каждая конкретная СУБД поддерживает определенный вид данных (форматов записей и отношений), называемый моделью данных СУБД.
Следующий этап разработки базы данных предполагает выбор представления концептуальной модели с помощью модели данных конкретной СУБД. Полученное таким образом представление концептуальной модели называется логической моделью БД. Или другими словами, логическая модель – это концептуальная схема, специфицированная в языке конкретной СУБД. Логическая модель представляет данные и элементы данных вне зависимости от их содержания и среды хранения. Далее разработчик системы средствами СУБД отображает полученную логическую модель БД в память ЭВМ и определяет методы доступа. Полученное представление данных в памяти ЭВМ называется внутренним представлением или структурой хранения. Прикладные программы работают с логической моделью, причем каждому пользователю представляется подмножество этой логической модели (подсхема), отражающее его представление о предметной области. Каждая прикладная программа «видит» и обрабатывает только те данные, которые необходимы именно ей.
Соответствующее «видение» данных прикладными программами (пользователями) представляет собой внешние представления. Взаимосвязь вышеуказанных моделей изображена на рис.3.

Рис.3 Различные представления о данных в БД
На данной схеме выделены три различных уровня описания данных (внешний, концептуальный, внутренний). Эти уровни формируют так называемую трехуровневую архитектуру ANSI/SPARC, предложенную в 1975 г. Комитетом планирования стандартов и норм SPARC (Standards Planning and Requirements Committee) Национального института стандартизации США (American National Standards Institute – ANSI). Основная цель этой архитектуры состоит в отделении пользовательского представления о данных в базе данных от их физического представления. Использование таких представлений о данных позволяет обеспечить выполнение основного требования к БД – независимости программ и данных.
При изменении прикладных программ может измениться соответствующее внешнее представление, но логическая модель данных не изменяется.
Теория схем – это теория знаний, их репрезентаций и использования. Согласно теории схем, все знания упакованы в определенные структуры (элементы), они-то и называются схемами.
Схема также есть сеть (а возможно, и дерево) подсхем, последние репрезентируют различные аспекты концептуального содержания закодированного схемой понятия. Как пример рассмотрим схему понятия “лицо”. Она расчленяется на ряд подсхем, репрезентирующих отдельные части лица: нос, рот, глаз. Каждая подсхема в свою очередь распадается на конфигурацию подсхем. глаз-схема, например, содержит подсхемы зрачек, глазное яблоко и т.д. Как выполнение полной процедуры зависит от успешной реализации ее подпроцедур, так и пригодность схемы зависит от пригодности каждой составляющей ее подсхемы.
Модели данных. Иерархическая, сетевая и реляционная модели данных; схема отношения
Система баз данных поддерживает в памяти ЭВМ модель предметной области. Однако результат моделирования зависит не только от предметной области, но и от используемой СУБД, поскольку каждая система предоставляет свой инструментарий для отображения предметной области [17].
Этот инструментарий принято называть моделью данных. В то же время результат отображения предметной области в терминах модели данных называется моделью баз данных.
Модель данных определяется тремя компонентами:
. допустимой организацией данных;
. ограничениями целостности (семантической);
. множеством операций, допустимых над объектами модели данных.
Иерархическая модель представляет собой совокупность элементов, расположенных в порядке их подчинения от общего к частному и образующих перевернутое по структуре дерево (граф).
К основным понятиям иерархической структуры относятся уровень, узел и связь. Узел - это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину, не подчиненную никакой другой вершине и находящуюся на самом верхнем - первом уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т. д. уровнях. Количество деревьев в базе данных определяется числом корневых записей. К каждой записи базы данных существует только один иерархический путь от корневой записи.
В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом.
Реляционная модель данных объекты и связи между ними представляет в виде таблиц, при этом связи тоже рассматриваются как объекты. Все строки, составляющие таблицу в реляционной базе данных, должны иметь первичный ключ. Все современные средства СУБД поддерживают реляционную модель данных.
Эта модель характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
1. Каждый элемент таблицы соответствует одному элементу данных.
2. Все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип и длину.
3. Каждый столбец имеет уникальное имя.
4. Одинаковые строки в таблице отсутствуют;
5. Порядок следования строк и столбцов может быть произвольным.
Постреляционные модели данных:

Иерархическая модель
Сетевая модель

Реляционная модель
Отношение — фундаментальное понятие реляционной модели данных. По этой причине модель и называется реляционной (от лат. relatio — «отношение», «зависимость», «связь»).
Понятие «схема отношения» соответствует описанию структуры таблицы.

Язык манипулирования данными для реляционной модели; Реляционная алгебра и язык SQL.
Манипулирование данными в РМД осуществляется с помощью операций реляционной алгебры (РА) или реляционного исчисления [1]. Реляционная алгебра основана на теории множеств, а реляционное исчисление базируется на математической логике.
Реляционная алгебра - это язык операций, выполняемых над отношениями - таблицами реляционной базы данных. Операции реляционной алгебры позволяют на основе одного или нескольких отношений создавать другое отношение без изменения самих исходных отношений. Полученное другое отношение обычно не записывается в базу данных, а существует в результате выполнения SQL-запроса. Для каждой операции реляционной алгебры будет дана её реализация в виде запросов на языке SQL.
Операция выборки
Операция
выборки работает с одним отношением ![]() и
определяет результирующее отношениеR,
которое содержит только те кортежи (или
строки, или записи), отношения
и
определяет результирующее отношениеR,
которое содержит только те кортежи (или
строки, или записи), отношения ![]() ,
которые удовлетворяют заданному условию
(предикатуP).
,
которые удовлетворяют заданному условию
(предикатуP).
Таким образом, операция выборки - унарная операция - и записывается следующим образом:
![]() ,
,
где P - предикат (логическое условие).
Запрос SQL
SELECT * from R3 WHERE A3>'d0'
Теперь посмотрим, что получится в результате выполнения этой операции реляционной алгебры и соответствующего ей запроса SQL. В таблице ниже дано одно отношение, с которым работает эта операция.
|
R3 | |||
|
A1 |
A2 |
A3 |
A4 |
|
3 |
hh |
yl |
ms |
|
4 |
pp |
a1 |
sr |
|
1 |
rr |
yl |
ms |
Просматриваем столбец А3 и устанавливаем, что предикату A3>'d0' удовлетворяют записи в первой и третьей строках исходного отношения (так как номер буквы y в алфавите больше номера буквы d). В результате получаем следующее новое отношение, в котором две строки:
|
R | |||
|
A1 |
A2 |
A3 |
A4 |
|
3 |
hh |
yl |
ms |
|
1 |
rr |
yl |
ms |
Комбинировать всевозможные логические условия для выборок Вам поможет материал "Булева алгебра (алгебра логики)".
А в материалах раздела "Программирование PHP/MySQL" Вы найдёт немало примеров комбинаций различных логических условий для выборок из базы данных.
Операция проекции
Операция
проекции (![]() )
работает, как и операция выборки, только
с одним отношением
)
работает, как и операция выборки, только
с одним отношением![]() и
определяет новое отношениеR,
в котором есть лишь те атрибуты (столбцы),
которые заданы в операции, и их значения.
и
определяет новое отношениеR,
в котором есть лишь те атрибуты (столбцы),
которые заданы в операции, и их значения.
Запрос SQL
SELECT DISTINCT A4, A3 from R3
Пусть вновь дано то же отношение R3:
|
R3 | |||
|
A1 |
A2 |
A3 |
A4 |
|
3 |
hh |
yl |
ms |
|
4 |
pp |
a1 |
sr |
|
1 |
rr |
yl |
ms |
Из исходного отношения выбираем только столбцы А4 и А3 и видим, что строки со значениями - первая и третья - идентичны. Исключаем дубликат (за это отвечает ключевое слово DISTINCT в SQL-запросе, которое говорит, что нужно выбрать только уникальные записи) и получаем следующее новое отношение, в котором два атрибута и две строки (записи):
|
R | |
|
A4 |
A3 |
|
ms |
yl |
|
sr |
a1 |
Операция объединения
Результатом
объединения двух множеств (отношений)
А и В (![]() )
будет такое множество (отношение) С,
которое включает в себя те и только те
элементы, которые есть или во множестве
А или во множестве В. Говоря упрощённо,
все элементы множества А и множества
В, за исключением дубликатов, образующихся
за счёт того, что некоторые элементы
есть и в первом, и во втором множестве.
Операция объединения реляционной
алгебры идентична операцииобъединения
множеств, которая также описана в
материале "Множества и операции над
множествами".
)
будет такое множество (отношение) С,
которое включает в себя те и только те
элементы, которые есть или во множестве
А или во множестве В. Говоря упрощённо,
все элементы множества А и множества
В, за исключением дубликатов, образующихся
за счёт того, что некоторые элементы
есть и в первом, и во втором множестве.
Операция объединения реляционной
алгебры идентична операцииобъединения
множеств, которая также описана в
материале "Множества и операции над
множествами".
Запрос SQL
SELECT A1, A2, A3 from R1 UNION SELECT A1, A2, A3 from R2
Теперь посмотрим, что получится в результате выполнения этой операции реляционной алгебры и соответствующего ей запроса SQL. Теперь даны два отношения, так как операция объединения - бинарная операция:
|
R1 |
|
R2 | ||||
|
A1 |
A2 |
A3 |
A1 |
A2 |
A3 | |
|
Z7 |
aa |
w11 |
X8 |
pp |
k21 | |
|
B7 |
hh |
h15 |
Q2 |
ee |
h15 | |
|
X8 |
pp |
w11 |
X8 |
pp |
w11 | |
Объединяем строки первого и второго отношения и видим, что третья строка, которая является третьей и в первом, и во втором отношении - идентичны, поэтому её включаем в новое отношение только один раз. Получаем следующее отношение:
|
R | ||
|
A1 |
A2 |
A3 |
|
Z7 |
aa |
w11 |
|
B7 |
hh |
h15 |
|
X8 |
pp |
w11 |
|
X8 |
pp |
k21 |
|
Q2 |
ee |
h15 |
Важно следующее: операция объединения может быть выполнена только тогда, когда два отношения обладают одинаковым числом и названиями атрибутов (столбцов), или, говоря формально, совместимы по объединению.
Операция пересечения
Результатом
пересечения двух множеств (отношений)
А и В (![]() )
будет такое множество (отношение) С,
которое включает в себя те и только те
элементы, которые есть и во множестве
А, и во множестве В. Операция пересечения
реляционной алгебры идентична
операциипересечения
множеств, которая также описана в
материале "Множества и операции над
множествами".
)
будет такое множество (отношение) С,
которое включает в себя те и только те
элементы, которые есть и во множестве
А, и во множестве В. Операция пересечения
реляционной алгебры идентична
операциипересечения
множеств, которая также описана в
материале "Множества и операции над
множествами".
Запрос SQL
SELECT A1, A2, A3 from R1 INTERSECT SELECT A1, A2, A3 from R2
В некоторых диалектах SQL отсутствует ключевое слово INTERSECT. Его заменой, например, в MySQL и других, является INNER JOIN. О том, как работает оператор SQL JOIN вообще и его разновидности INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN и FULL OUTER JOIN - на уроке SQL JOIN - соединение таблиц базы данных.
Запрос MySQL
SELECT * from R1 INNER JOIN R2 WHERE
R1.A1 = R2.A1 AND
R1.A2 = R2.A2 AND
R1.A3 = R2.A3
Теперь посмотрим, что получится в результате выполнения этой операции реляционной алгебры и соответствующего ей запроса SQL. Вновь даны два отношения R1 и R2:
|
R1 |
|
R2 | ||||
|
A1 |
A2 |
A3 |
A1 |
A2 |
A3 | |
|
Z7 |
aa |
w11 |
X8 |
pp |
k21 | |
|
B7 |
hh |
h15 |
Q2 |
ee |
h15 | |
|
X8 |
pp |
w11 |
X8 |
pp |
w11 | |
Просматриваем все записи в двух отношениях, и обнаруживаем, что и в первом, и во втором отношении есть одна строка - та, которая является третьей и в первом, и во втором отношении. Получаем новое отношение:
|
R | ||
|
A1 |
A2 |
A3 |
|
X8 |
pp |
w11 |
Операция разности
Разность
двух отношений R1 и R2 (![]() )
состоит из кортежей (или записей, или
строк), которые имеются в отношении R1,
но отсутствуют в отношении R2. Отношения
R1 и R2 должны быть совместимы по объединению.
Операция разности реляционной алгебры
идентична операцииразности
множеств, которая также описана в
материале "Множества и операции над
множествами".
)
состоит из кортежей (или записей, или
строк), которые имеются в отношении R1,
но отсутствуют в отношении R2. Отношения
R1 и R2 должны быть совместимы по объединению.
Операция разности реляционной алгебры
идентична операцииразности
множеств, которая также описана в
материале "Множества и операции над
множествами".
Запрос SQL
SELECT A1, A2, A3 from R2 EXCEPT
SELECT A1, A2, A3 from R1
Установим, что получится в результате выполнения этой операции реляционной алгебры и соответствующего ей запроса SQL. Вновь даны два отношения R1 и R2:
|
R1 |
|
R2 | ||||
|
A1 |
A2 |
A3 |
A1 |
A2 |
A3 | |
|
Z7 |
aa |
w11 |
X8 |
pp |
k21 | |
|
B7 |
hh |
h15 |
Q2 |
ee |
h15 | |
|
X8 |
pp |
w11 |
X8 |
pp |
w11 | |
Из отношения R2 исключаем строку, которая есть также в отношении R2 - третью - и получаем новое отношение:
|
R | ||
|
A1 |
A2 |
A3 |
|
X8 |
pp |
w11 |
|
Q2 |
ee |
h15 |
Операция декартова произведения
Операция
декартова произведения (![]() )
определяет новое отношение R, которое
является результатом конкатенации
каждого кортежа отношения R1 с каждым
кортежем отношения R2.
)
определяет новое отношение R, которое
является результатом конкатенации
каждого кортежа отношения R1 с каждым
кортежем отношения R2.
Запрос SQL
SELECT * from R3, R4
Установим, что получится в результате выполнения этой операции реляционной алгебры и соответствующего ей запроса SQL. Даны два отношения R3 и R4:
|
R3 |
|
R4 | ||||
|
A1 |
A2 |
A3 |
A4 |
A5 |
A6 | |
|
3 |
hh |
yl |
ms |
3 |
hh | |
|
4 |
pp |
a1 |
sr |
4 |
pp | |
|
1 |
rr |
yl |
ms |
|
| |
В новом отношении должны присутствовать все атрибуты (столбцы) двух отношений. Сначала первая строка отношения R3 сцепляется с каждой из двух строк отношения R4, затем вторая строка отношения R3, затем третья. В результате должно получиться 3 Х 2 = 6 кортежей (строк). Получаем такое новое отношение:
|
R | |||||
|
A1 |
A2 |
A3 |
A4 |
A5 |
A6 |
|
3 |
hh |
yl |
ms |
3 |
hh |
|
3 |
hh |
yl |
ms |
4 |
pp |
|
4 |
pp |
a1 |
sr |
3 |
hh |
|
4 |
pp |
a1 |
sr |
4 |
pp |
|
1 |
rr |
yl |
ms |
3 |
hh |
|
1 |
rr |
yl |
ms |
4 |
pp |
Операция деления
Результатом
операции деления (![]() )
является набор кортежей (строк) отношения
R1, которые соответствуют комбинации
всех кортежей отношения R2. Для этого
нужно, чтобы в отношении R2 была часть
атрибутов (можно и один), которые есть
в отношении R1. В результирующем отношении
присутствуют только те атрибуты отношения
R1, которых нет в отношении R2.
)
является набор кортежей (строк) отношения
R1, которые соответствуют комбинации
всех кортежей отношения R2. Для этого
нужно, чтобы в отношении R2 была часть
атрибутов (можно и один), которые есть
в отношении R1. В результирующем отношении
присутствуют только те атрибуты отношения
R1, которых нет в отношении R2.
Запрос SQL
SELECT DISTINCT A1, A4 from R5 WHERE
NOT EXIST (SELECT * from R6 WHERE NOT EXIST
R6.A2 = R5.A2 AND
R6.A3 = R5.A3)
Давайте посмотрим, что получится в результате выполнения этой операции реляционной алгебры и соответствующего ей запроса SQL. Даны два отношения R5 и R6:
|
R5 |
|
R6 | ||||||
|
A1 |
A2 |
A3 |
A4 |
|
A2 |
A3 | ||
|
2 |
S3 |
4 |
sun |
|
R4 |
8 | ||
|
3 |
X8 |
7 |
kab |
|
X8 |
7 | ||
|
3 |
R4 |
8 |
kab |
|
|
| ||
Комбинации всех кортежей отношения R6 соответствуют вторая и третья строки отношения R5. Но после исключения атрибутов (столбцов) А2 и А3 эти строки становятся идентичными. Поэтому в новом отношении присутствует эта строка один раз. Новое отношение:
|
R | |
|
A1 |
A4 |
|
3 |
kab |
Проектирование реляционной базы данных на основе функциональных зависимостей. Функциональные зависимости, декомпозиция отношений, транзитивные зависимости.
проект реляционной базы данных - это набор взаимосвязанных отношений, в которых определены все атрибуты, заданы первичные ключи отношений и заданы еще некоторые дополнительные свойства отношений, которые относятся к принципам поддержки целостности.
Системный анализ и словесное описание информационных объектов предметной области.
Проектирование инфологической модели предметной области - частично формализованное описание объектов предметной области в терминах некоторой семантической модели, например, в терминах ЕR-модели.
Даталогическое или логическое проектирование БД, то есть описание БД в терминах принятой даталогической модели данных.
Физическое проектирование БД, то есть выбор эффективного размещения БД па внешних носителях для обеспечения наиболее эффективной работы приложения.
Проектирование схемы БД может быть выполнено двумя путями:
путем декомпозиции (разбиения), когда исходное множество отношений, входящих в схему БД заменяется другим множеством отношений (число их при этом возрастает), являющихся проекциями исходных отношений;
Классическая технология проектирования реляционных баз данных связана с теорией нормализации, основанной на анализе функциональных зависимостей между атрибутами отношений. Понятие функциональной зависимости является фундаментальным в теории нормализации реляционных баз данных.
Функциональная зависимость – зависимость значения одного столбца от другого, но никак не наоборот. Т.е., если в отношении R, содержащем атрибуты А и В, атрибут В функционально зависит от атрибута А, то каждое отдельное значение атрибута А связано только с одним значением атрибута В (причем в качестве А и В могут выступать группы атрибутов).
Пр.: Учебный план (№*, дисциплина, семестр, кол-во часов, форма отчетности, препод.) Дисциплина, семестр и форма отчетности функционально зависят от №
Смысл нормализации – устранение избыточности, противоречивости и непоследовательности моделей данных.
Нормальная форма — свойство отношения в реляционной модели данных, характеризующее его с точки зрения избыточности, которая потенциально может привести к логически ошибочным результатам выборки или изменения данных. Нормальная форма определяется как совокупность требований, которым должно удовлетворять отношение.
Процесс проектирования с использованием декомпозиции представляет собой процесс последовательной нормализации схем отношений, при этом каждая по следующая итерация соответствует нормальной форме более высокого уровня ц обладает лучшими свойствами по сравнению с предыдущей.
каждая следующая нормальная форма в некотором смысле улучшает свойства предыдущей;
при переходе к следующей нормальной форме свойства предыдущих нормальных форм сохраняются.
Отношение находится в первой нормальной форме тогда, когда соблюдается атомарность кортежей, то есть нет перечисления в отдельном кортеже.
Отношение находится во второй нормальной форме тогда и только тогда, когда оно находится в первой нормальной форме, и когда функциональные зависимости выносятся в отдельную таблицу (отношения) – должность и зарплата в отдельной таблице, например.
Отношение находится в третьей нормальной форме тогда и только тогда, когда оно находится во второй нормальной форме и не содержит транзитивных зависимостей.
Транзитивная зависимость. Если для атрибутов А, В и С некоторого отношения существуют функциональные зависимости А→В, В→С, говорят, что атрибут С связан транзитивной зависимостью с атрибутом А через атрибут В (при этом атрибут А не должен функционально зависеть ни от атрибута В, ни от атрибута С).
Пример: Учебный план (семестр*, Дисциплина*, форма отчетности*, кол-во часов, ФИО препод., должность) ФИО препод. зависит от первичного ключа, а должность зависит от ФИО преподавателя → должность преподавателя связана транзитивной зависимостью с первичным ключом через ФИО преподавателя.
Проектирование с использованием метода «сущность – связь».
Метод сущность-связь или метод «ER-диаграмм»: ER – аббревиатура от слов Essence(сущность)иRelation(связь). Основными понятиями метода сущность-связь являются:
- сущность,
- атрибут сущности,
- ключ сущности,
- связь между сущностями,
- степень связи,
- класс принадлежности экземпляров сущности,
- диаграммы ER-экземпляров,
- диаграммы ER-типа.
Сущность представляет собой объект, информация о котором хранится в БД. С помощью сущности моделируется класс однотипных объектов. Экземпляры сущности отличаются друг от друга и однозначно идентифицируются. Сущность имеет имя, уникальное в пределах моделируемой системы. Например, ПРЕПОДАВАТЕЛЬ, ПРЕДМЕТ, СТУДЕНТ, ГРУППА.
Атрибут – это свойство сущности. Например, для сущности СТУДЕНТ атрибутами являются Фамилия, Номер_зачетной_книжки.
Ключ сущности – неизбыточный набор атрибутов, используемый для идентификации конкретного экземпляра сущности. Например, Номер_зачетной_книжки для сущности СТУДЕНТ. Ключевые атрибуты изображаются на диаграмме подчеркиванием.
Связь двух и более сущностей – предполагает зависимость между атрибутами этих сущностей. Название связи обычно представляется глаголом. Например, ПРЕПОДАВАТЕЛЬ ВЕДЕТ ПРЕДМЕТ, СТУДЕНТ ПОСЕЩАЕТ ЗАНЯТИЯ. Связи показывают, каким образом сущности относятся или взаимодействуют между собой. Связь может существовать между двумя разными сущностями или между сущностью и ей же самой (рекурсивная связь).
Связи делятся на три типа множественности: один-к-одному (1:1), один-ко-многим(1:М), многие-ко-многим (М:М).
Тип связи много-ко-многим является временным типом связи, который допустим на ранний этапах создания промежуточной сущности.
Рис. Пример связи многие ко многим.

Между двумя сущностями может быть задано сколько угодно связей с разными смысловыми нагрузками. Например, между сущностями СТУДЕНТ и ПРЕПОДАВАТЕЛЬ можно установить две смысловые связи: «дипломное проектирование» и «лекции».
Каждая связь может иметь одну из двух модальностей: может и должен. Модальность может означает, что экземпляр одной сущности может быть связан с одним или несколькими экземплярами другой сущности, а может быть и не связан ни с одним экземпляром. Модальность должен означает, экземпляр одной сущности обязан быть связан не менее чем с одним экземпляром другой сущности. Связь может иметь разную модальность с разных концов. Необязательность связи (может) обозначается пустым кружочком на конце связи, а обязательность (должен) - перпендикулярной линий, перечеркивающей связь.
|
| |
|
|
|

Диаграммы "Сущность-Связь"

Прямоугольник – сущность
Ромб – связь
Кружок – атрибут.
Создание и модификация данных, Поиск, сортировка, индексирование базы данных
Создание и модификация базы данных
Для создания базы данных необходимо:
1. Открыть СУБД MS Access .
2. В появившемся диалоговом окне Miсrosoft Access включаем режим «Новая база данных» и нажать кнопку OK
3. В поле Папкадиалогового окна Файл новой базы данных выбираем папку, в которой будет сохранен создаваемый файл базы данных.
4. Задаем Имя файла новой базы данных и нажимаем кнопку Создать
5.Перейти на вкладку Таблицы и нажать кнопку Создать
6. Выбираем режим Конструктор и нажимаем кнопку ОК
7. В столбце Имя полядиалогового окна конструктора таблиц вводим имена полей таблицы
8. Выполняем команду: Вид - режим таблицы.
9. В появившемся диалоговом окне нажимаем кнопку Да для сохранения структуры базы данных)
В поле Имя таблицы диалогового окна Сохранение введем имя таблицы (по умолчанию Таблица 1)
При появлении диалогового окна - предупреждения нажимаем кнопкуДа для создания ключевого поля.
10. После перехода в Режим таблицы вводим записи в созданную таблицу
Для модификации структуры базы данных выполняем следующие действия:
1. Выполняем команду Вид - Конструктор.
2. В панели Конструктора таблиц вводим имена новых полей, тип данных, формат поля:
Поиск, сортировка.
Обработка данных средствами МS Ассеss включает в себя следующие направления:
сортировка — выстраивание данных в нужном порядке;
поиск данных — извлечение записей данных из списка в соответствии с некоторыми требованиями (критериями).
Средства сортировки, фильтрации, поиска и замены данных реализованы в МS Ассеss как автоматически создаваемые запросы. Данные операции производятся с таблицами или запросами, открытыми в режиме таблицы. Сортировку и поиск данных можно выполнить, используя соответствующие команды:
§ для сортировки записей следует применять команду Сортировкав меню Записи(далее необходимо выбрать в сортировки — По возрастаниюлибо По убыванию);
§ для отмены сортировки воспользоваться командой Удалить фильтрв меню Записи.
При фильтрации отбор данных происходит из таблицы или запроса с учетом некоторого критерия отбора..
Различают фильтры трех видов.
фильтр по выделенному фрагменту. Критерием отбора в данном фильтре является значение или части значения поля таблицы. Это наиболее быстрый способ отбора данных. Недостаток данного вида фильтрации — отбор записей по значению только одного поля.
Обычный фильтр — это отбор записей по значению нескольких полей. Для задания критерия отбора заполняется специальная форма (бланк).
установить критерии отбора, используя логические операции И, ИЛИ, НЕ, а также различные выражения; следует помнить, что если в одной из вкладок окна бланка критериев отбора заполнены критерии для нескольких полей, то критерии объединяются с помощью логической операции И;воспользоваться командой Применить фильтр в Меню Фильтр(либо кнопкой на панели инструмент» Фильтр).
За упорядочивание строк, выгружаемых в SQL-запросе, отвечает предложение ORDER BY. Оно располагается в самом конце запроса:
|
1 2 3 |
SELECT <Перечень столбцов> FROM <Перечень таблиц> ORDER BY <Условие сортировки> |
В условии сортировки указываются столбцы, по которым будут упорядочены полученные строки таблицы:
|
1 |
ORDER BY col1, col2 |
Расширенный фильтр представляет собой отбор записей в соответствии с критерием отбора для различных полей таблицы, включающий сортировки по данным полям Расширенный фильтр аналогичен расширенному фильтру в MS Ехcel.
Индексирование данных
МS Ассеss автоматически индексирует таблицу по значению Ключа. Однако может потребоваться создание дополнительных индексов по значениям других полей. Индексы позволяют ускорить поиск данных в тех полях таблицы, по которым она проиндексирована.
Каждая таблица МS Ассеss может иметь до 32-х индексов, 5 из них могут быть составным (в составной индекс может входить до 10-ти полей). Не следует создавать индексы для каждого поля таблицы и всех их комбинаций, т. к. это может существенно замедлить процесс заполнения таблицы (при изменении или добавлении записи автоматически обновляются все индексы).
Чтобы проиндексировать таблицу, необходимо:
1. Открыть таблицу в режиме конструктора.
2. Выделить необходимое поле в бланке структуры таблицы .
3. В нижней части окна конструктора установить значение "Да" для свойства Индексированное поле(на вкладке Общиев разделе Свойства)и выбрать из списка способ индексирования

Рис.25. Задание составного индекса
Для задания составного индекса открыть окно Индексы(нажать кнопку на панели инструментов Конструктор таблиц),а затем в поле Индексввести имя индекса и последовательно задать имена полей, входящих в составной индекс ( рис.25). При необходимости можно определить порядок сортировки для каждого поля составного индекса
Физическая организация базы данных. Хешированные, индексированные файлы;
Защита баз данных. Целостность и сохранность баз данных.