

Проведение анализа
Условия задачи такие же, как в и в первой части лабораторной работы.
Введите исходные данные, как показано ниже:
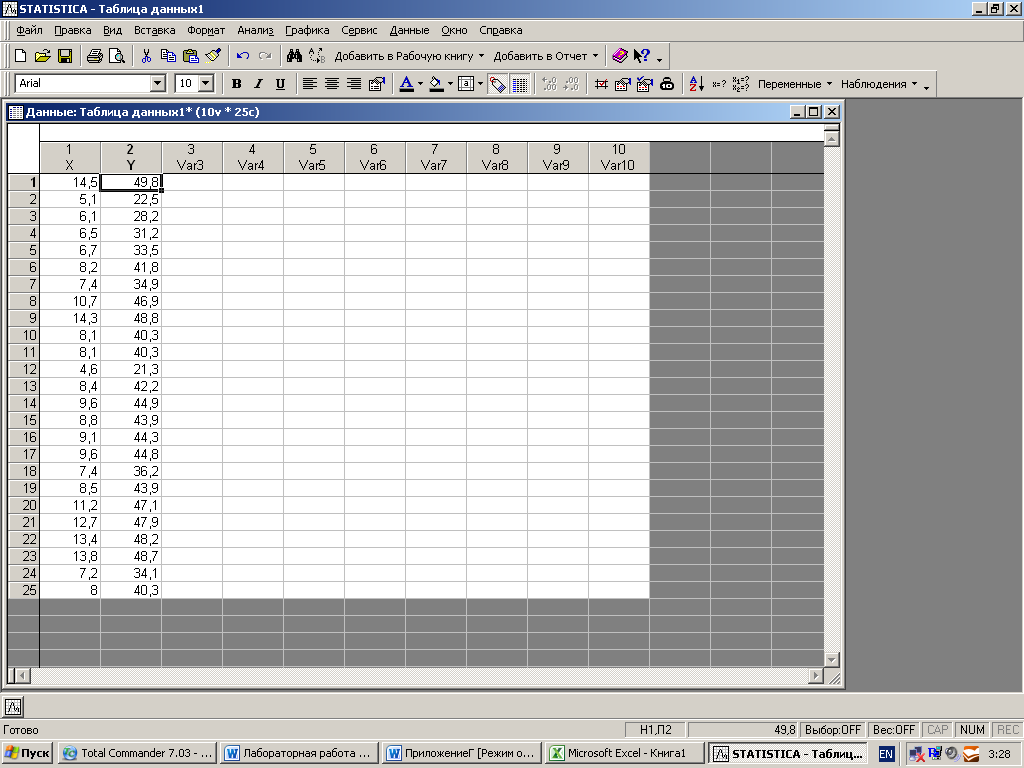
Var1 – независимая переменная –X;Var2 – зависимая переменная – y.
Переименовывать переменные Var1 и Var2не обязательно, иногда это может привести к возникновению ошибки при построении графика криволинейной зависимости во время процедуры нелинейного оценивания. Рекомендуется не менять имя переменной
Проведем анализ в модуле Nonlinear estimation (Нелинейная оценка).
Из Переключателя модулей Statisticaоткройте модульNonlinear estimation (Нелинейное оценивание).
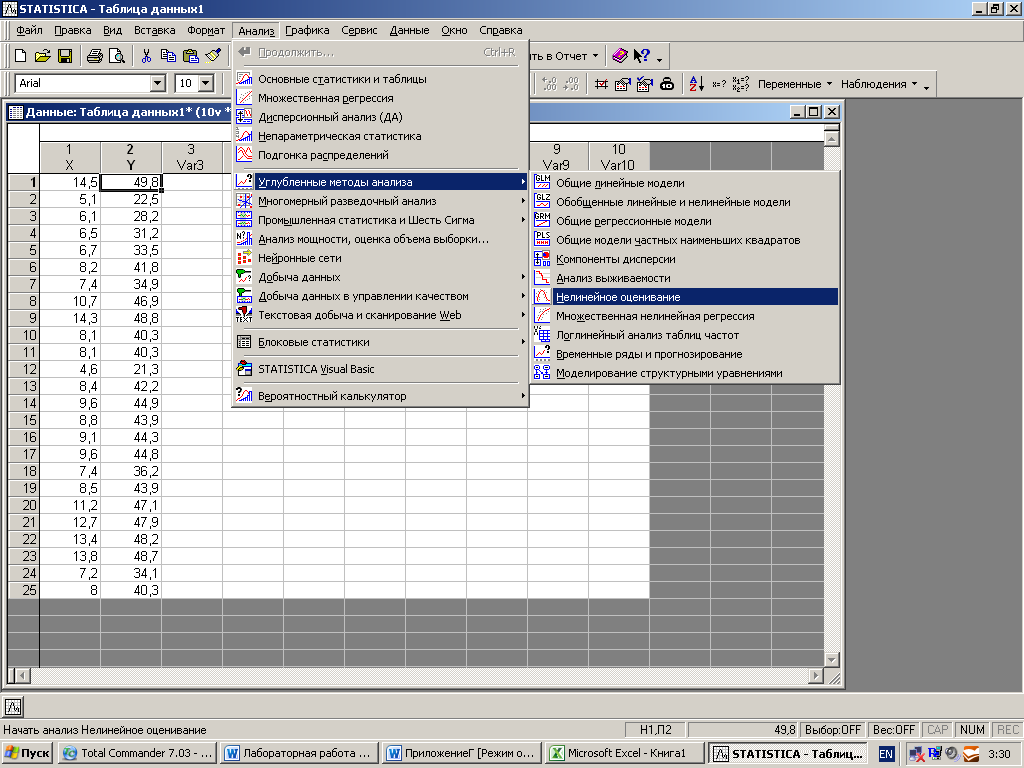
На экране появится стартовая панель модуля. Выберите опцию User specified regression, least squares(Метод наименьших квадратов) и далее щелкните мышью по названию модуля
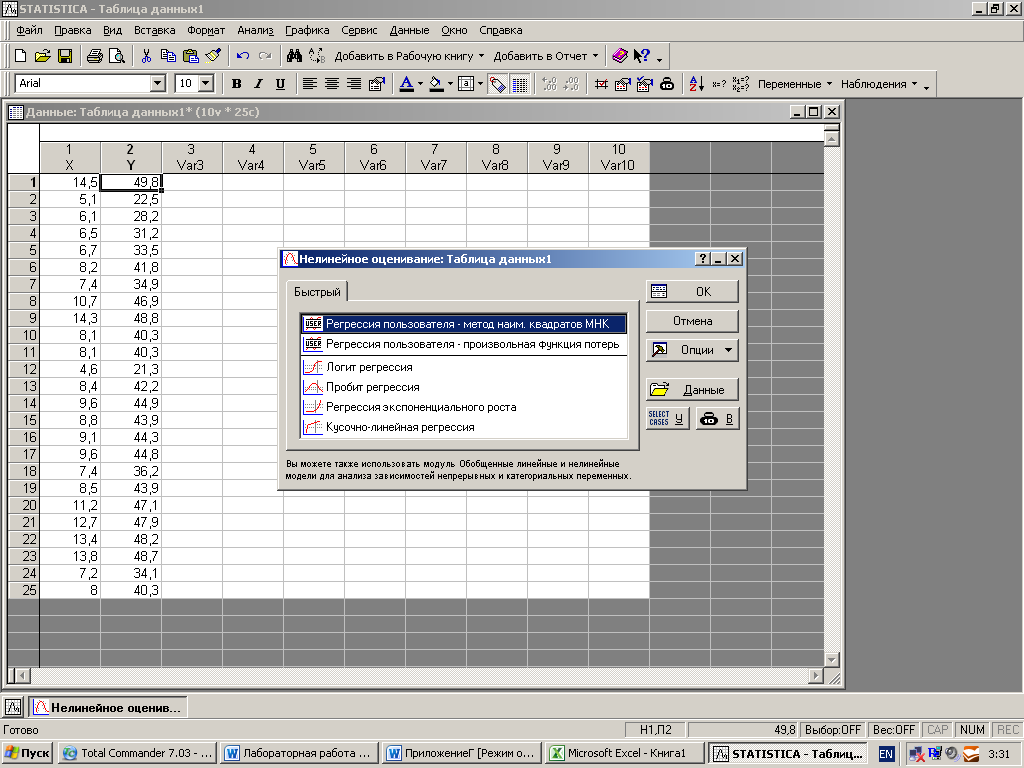
Стартовая панель модуля Nonlinear estimation (Метод наименьших квадратов)
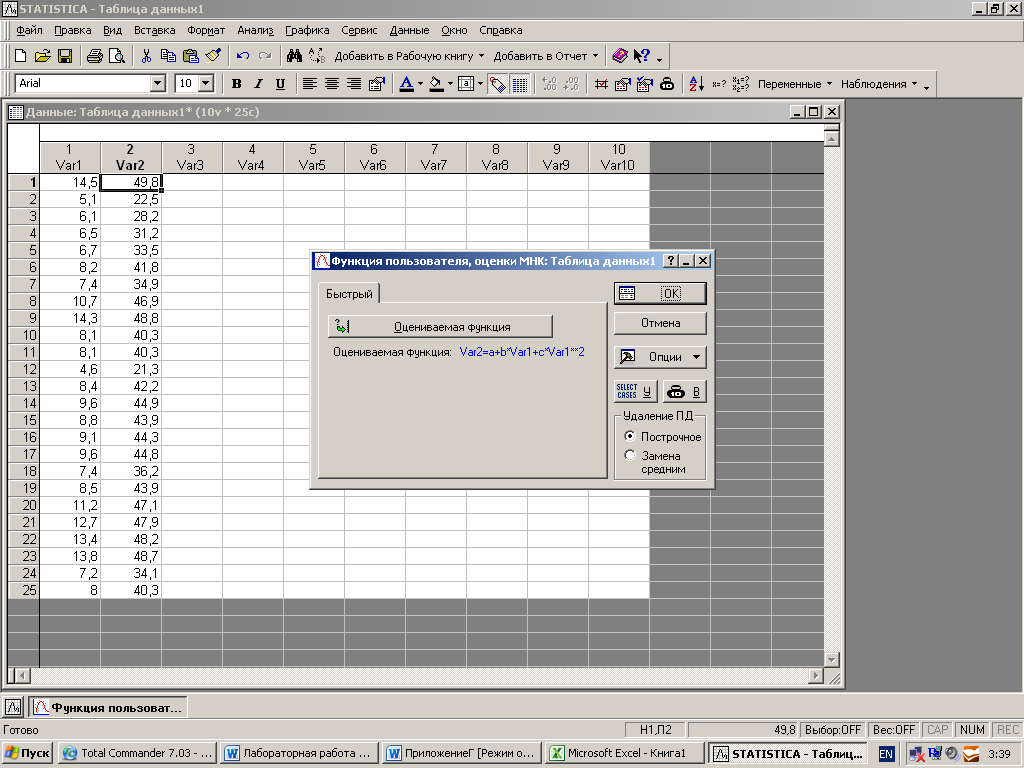
В появившемся окне щелкните мышью по кнопке Function of estimated (Оцениваемая функция)
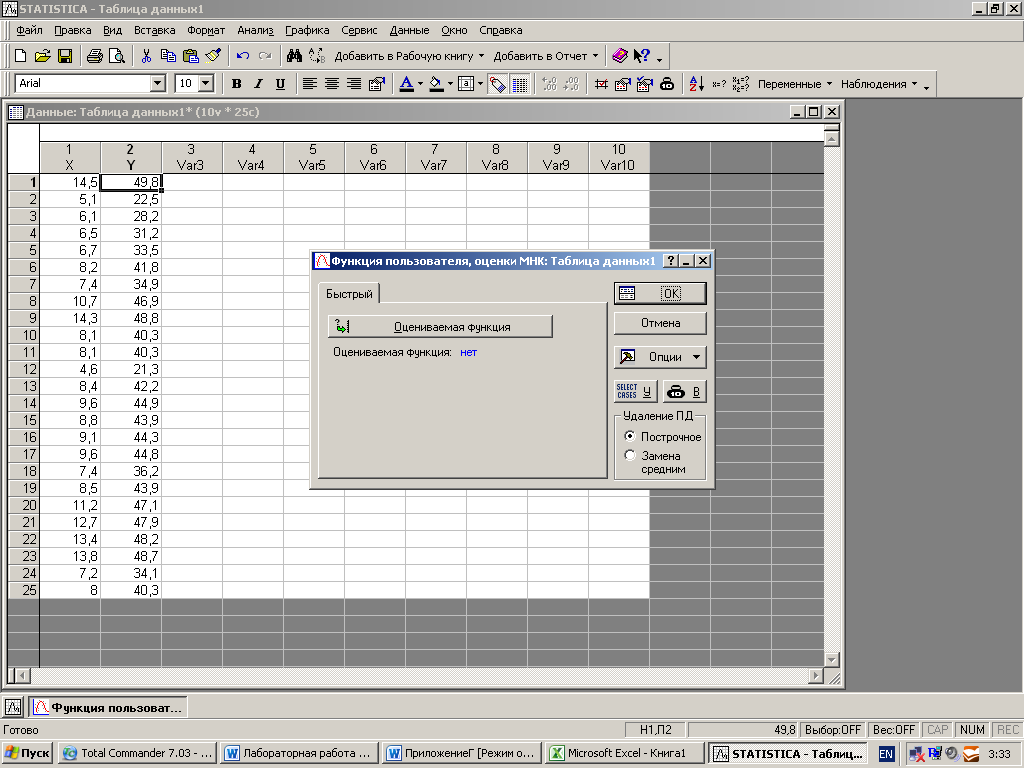
Панель ввода функции
В окне с клавиатуры введите предполагаемую функцию.
В отличие от подобной операции в табличном редакторе MS Excel в Statistica 6 вы можете ввести любую формулу, связывающую зависимую и независимую переменные.
В данном случае предполагается, что наиболее подходящей функцией является полином второй степени типа:
![]() или
в конкретном случае:
или
в конкретном случае:
![]()
В нижней части рисунка приведен перечень алгебраических и функциональных символов, которые воспринимаются программой.
Нажмите OK. Затем еще разOK.

Ввод функции
Результат обработки:
Нажмите OK.
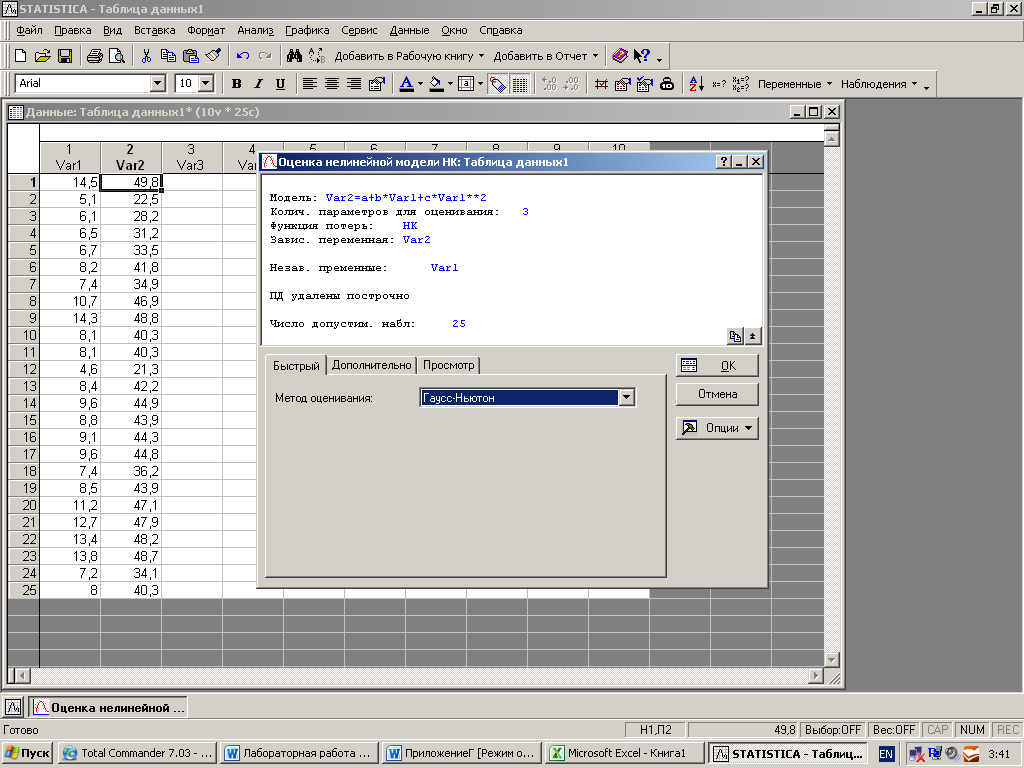
Верхняя часть окна информирует о модели, методе, количестве взятых в анализ пар. В середине окна выберите метод аппроксимации. Например: Gauss–Newton (Гаусс-Ньютон). НажмитеOK.
В верхней части появившегося окна результатов показаны значения корреляционного отношения и его квадрата, 0,988 и 0,977. Это указывает на сильную корреляционную связь между переменными.
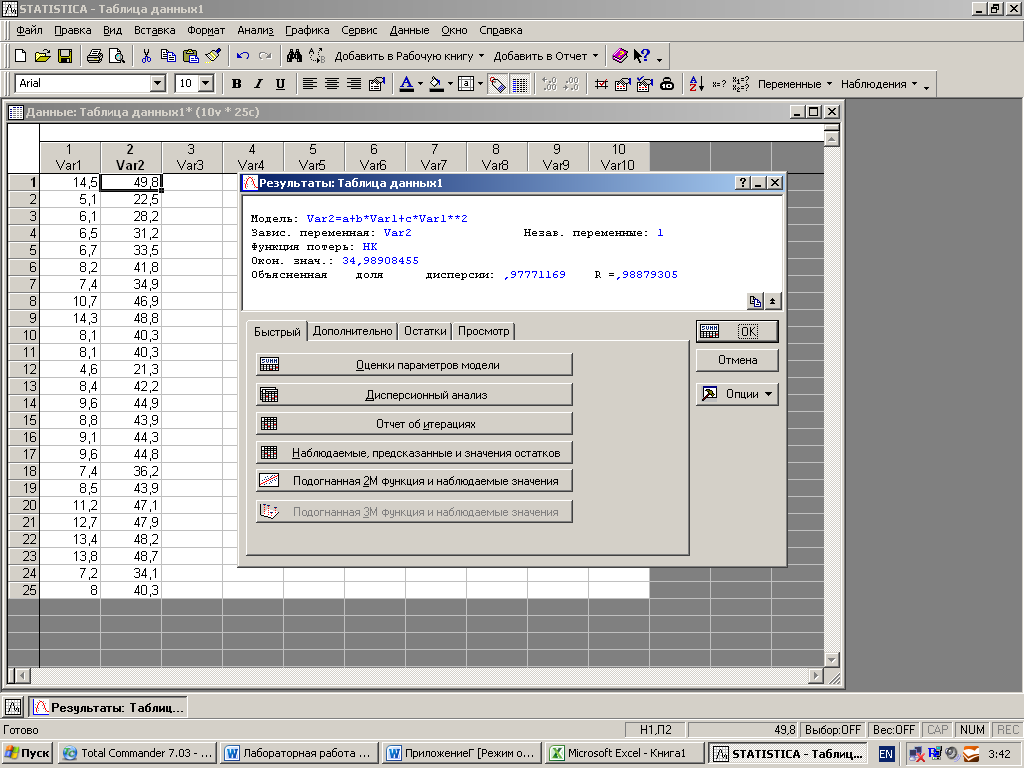
Окно результатов
В окне результатов щелкните мышью по кнопке Summary Parameters & standard errors(Оценки параметров модели). Полученные результаты подкрашены красным цветом, что свидетельствует о достоверности аппроксимации функцией:
![]()
|
Модель: Var2=a+b*Var1+c*Var1**2 (Таблица данных1) Зав. Пер. : Var2 Уров. значимости: 95.0% ( альфа=0.050) | ||||||
|
|
Оценка |
Стандарт |
t-знач. |
p-уров. |
Ниж. Дов |
Вер. Дов |
|
a |
-23,4071 |
3,010054 |
-7,7763 |
0,000000 |
-29,6496 |
-17,1646 |
|
b |
11,4636 |
0,641511 |
17,8697 |
0,000000 |
10,1332 |
12,7940 |
|
c |
-0,4507 |
0,032066 |
-14,0558 |
0,000000 |
-0,5172 |
-0,3842 |
В столбце Estimate (Оценка) показаны значения коэффициентов:a, b, c. Далее указаны стандартные ошибки,t–критерийпри 22 степенях свободы, уровень значимости меньше 0,05, верхний и нижний пределы достоверности.
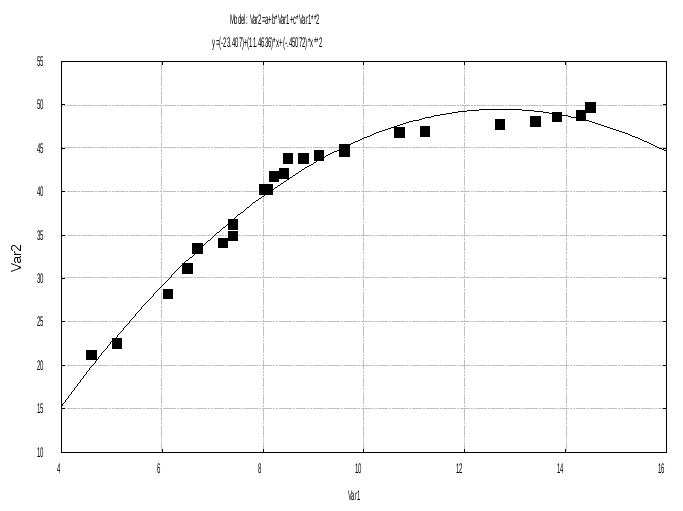
Вернитесь в окно Результаты(кнопка внизу слева). Щелкните мышью по кнопкеFitted 2D function & observed vals(Подогнанная 2М функция). На рисунке вы увидите графическую интерпретацию корреляционной связи исходных массивов в виде заданной функции:

В окне результатов в режиме Quick(Быстрый) нажмите кнопкуAnalysis of Variance(Дисперсионный анализ). Результат выполненной операции представлен в виде таблицы, и свидетельствует о достоверности регрессии (F = 8806,2 при р < 0,00..).
|
Модель: Var2=a+b*Var1+c*Var1**2 (Таблица данных1) Зав. Пер. : Var2 | |||||
|
|
Сум. квадратов |
СС |
Сред. квадраты |
F-Значение |
Р-знач. |
|
Регрессия |
42016,29 |
3,00000 |
14005,43 |
8806,160 |
0,00 |
|
Остатки |
34,99 |
22,00000 |
1,59 |
|
|
|
Сумма |
42051,28 |
25,00000 |
|
|
|
|
Привед. сумма |
1569,84 |
24,00000 |
|
|
|
|
Регрессия с Приведенной Суммой |
42016,29 |
3,00000 |
14005,43 |
214,118 |
0,00 |
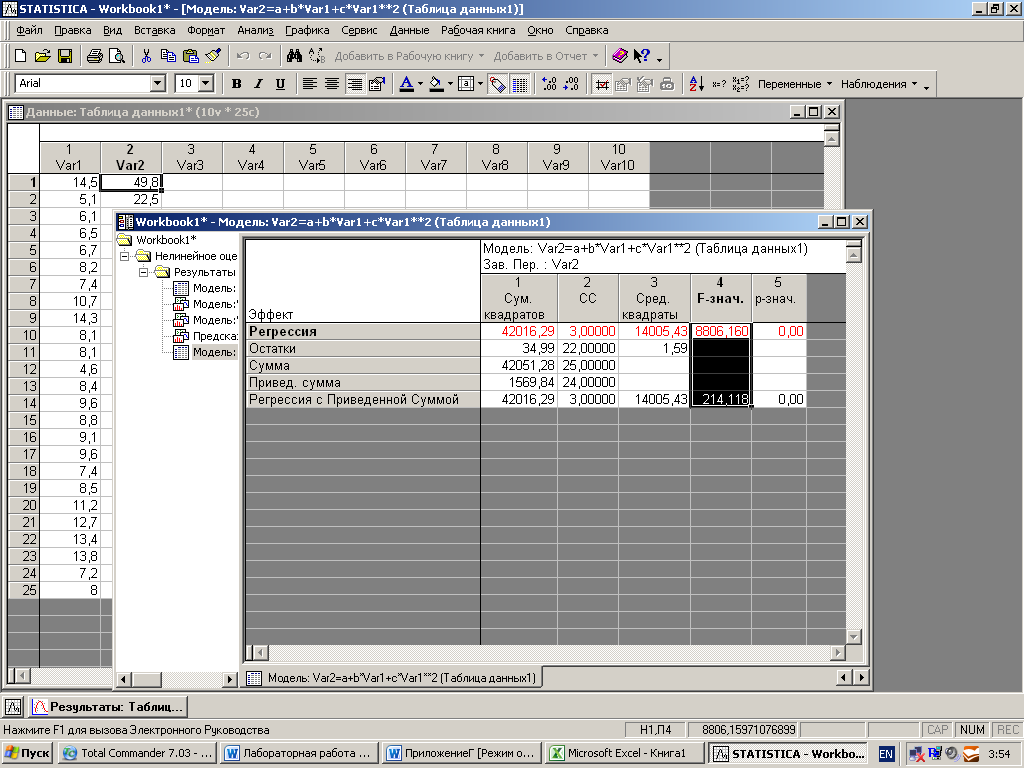
Результат анализа вариантов
В окне Результаты… перейдите в режим просмотра остатков Residuals(Остатки). Щелкните мышью по кнопкеObserved, predicted, residual vals(Наблюдаемые, предсказанные, остатки). Результаты выполненной операции представлены на рисунке

В окне Результаты… для оценки адекватности модели щелкните мышкой по кнопке Observed vs. Predicted(Предсказанные и наблюдаемые значения).
Из рисунка видно, массивы наблюдаемых
и предсказанных значений описываются
линейной функцией
![]() .
При этомk= 1 икоэффициент парной
корреляцииблизок к 1.
.
При этомk= 1 икоэффициент парной
корреляцииблизок к 1.

Визуализация результатов анализа
Вывод по общему анализу предполагаемой зависимости: корреляция и регрессия достоверны, так как F = 8806,2 и ta= 7,8, tb= 17,9 и tc=14,1 (t-статистика для каждого коэффициента), что существенно выше критических значений при р < 0,00..
В результате эксперимента исследователь формирует модель (тип зависимости, приблизительную математическую формулу, степень зависимости), по которой он может с определенной вероятностью предсказывать поведение зависимого объекта, при изменении внешнего воздействия.
Ни в коем случае нельзя строить предположения, используя значения х, которых нет в пределах собранных вами данных.
Задание для выполнения
Исходные данные представлены в виде таблицы:
|
X |
Y |
|
33,3 |
0,03 |
|
7,1 |
0,2 |
|
11,2 |
0,13 |
|
14,3 |
0,08 |
|
17,2 |
0,06 |
|
22,2 |
0,05 |
|
34,7 |
0,03 |
|
11,2 |
0,1 |
|
3,7 |
0,37 |
|
33,8 |
0,03 |
|
10,9 |
0,12 |
|
13,1 |
0,08 |
|
18,1 |
0,07 |
|
20,1 |
0,06 |
|
23,4 |
0,05 |
|
30,1 |
0,04 |
|
27 |
0,04 |
|
25,4 |
0,04 |
|
25,6 |
0,04 |
|
30,1 |
0,04 |
|
27,7 |
0,04 |
|
26 |
0,05 |
|
23,2 |
0,05 |
|
19 |
0,06 |
|
32,1 |
0,03 |
|
16,8 |
0,07 |
|
12,1 |
0,09 |
|
9,3 |
0,17 |
|
6,7 |
0,26 |
|
21,5 |
0,05 |
Необходимо произвести анализ согласно вышеописанному алгоритму и сделать выводу о предполагаемой зависимости между переменными.
Результаты скопировать в отдельный документ Word.