

Umk_Oed
.pdfn
X (n) ( X i ) / n .
i 1
Найдем его математическое ожидание
n
M ( X (n)) ( mx ) / n mx .
i 1
Отсюда следует, что X (n) является несмещенной оценкой для
математического ожидания mx .
При рассмотрении закона больших чисел мы убедились, что при увеличении n величина X (n) сходится по вероятности к mx . Тогда эта
оценка является и состоятельной. Определим теперь дисперсию этой оценки:
n
D( X (n)) D( X i ) / n2 Dx / n .
i 1
Эффективность или неэффективность оценки зависит от вида распределения величины Х. Например, доказано, что если величина Х
|
|
|
|
|
|
|
|
|
|
|
D( |
|
(n)) DX / n |
||||
распределена по нормальному закону, то величина |
X |
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
будет минимальной, т.е. оценка X (n) будет эффективной. |
|||||||||||||||||
Перейдем к оценке для дисперсии Dx . Рассмотрим для этого |
|||||||||||||||||
статистическую дисперсию |
|
|
|
|
|
||||||||||||
|
|
|
1 |
n |
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|||||||
D |
|
(n) |
|
( X i X (n))2 X 2 (n) ( X (n))2 . |
(3.15) |
||||||||||||
X |
|
||||||||||||||||
|
|
|
n i 1 |
|
|
|
|
|
|||||||||
|
Величина |
|
2 (n) |
||||||||||||||
Проверим, является ли эта оценка состоятельной. |
X |
||||||||||||||||
есть среднее арифметическое n значений случайной величины X2 и она сходится по вероятности к М(Х2 ). Второе слагаемое сходится по
вероятности к mx2 . Тогда дисперсия DX (n) сходится по вероятности к
M ( X 2 ) mx2 Dx , т.е. оценка DX (n) является состоятельной.
Проверим, является ли оценка DX (n) также и несмещенной. Для этого раскроем выражение (3.15):
|
|
|
|
n |
|
|
|
n |
|
|
|
D |
|
(n) |
( X i2 ) / n ( X i / n)2 |
|
|||||||
X |
|||||||||||
|
|
|
|
i 1 |
|
|
|
i 1 |
|
||
|
|
|
|
n |
|
|
|
n |
|
|
|
|
|
|
|
( X i2 ) / n |
( X i2 ) / n2 |
2 X i X j / n2 (3.16) |
|||||
|
|
|
|
i 1 |
|
|
|
i 1 |
|
i j |
|
|
|
|
|
n 1 |
n |
2 |
|
2 |
|
|
|
|
|
|
|
|
X i |
|
X i X j . |
||||
|
|
|
n2 |
n2 |
|||||||
|
|
|
|
i 1 |
|
|
i j |
|
|||
Найдем математическое ожидание величины (3 .16):
|
|
|
|
) |
n 1 |
n |
2 |
|
|
||
M (D |
|
|
|
|
|
M ( Xi2 ) |
|
M ( X i X j ) . |
(3.17) |
||
X (n) |
n2 |
n2 |
|||||||||
|
|
i 1 |
i j |
|
|||||||

Так как статистическая дисперсия не зависит от того, в какой точке выбрать начало координат, выберем его в точке mx . Тогда
o |
n |
M ( X i2 ) M ( X i2) Dx ; |
M ( X i2 ) nDx ; |
|
i 1 |
o o
M ( Xi , X j ) M ( X i X j ) cov( Xi , X j ) 0 .
Последнее равенство следует из того, что Xi и Xj − независимы. Подставив последние выражения в (3 .17), получим
n 1
M (DX (n) ) n Dx .
Отсюда следует, что статистическая дисперсия не является
n
несмещенной оценкой для Dx . Тогда введя поправку n 1 и умножив статистическую дисперсию на эту величину, получим «исправленную»
дисперсию в качестве оценки для Dx : S 2 (n) |
n |
D |
|
|
|
||
|
|
|
|
|
|||
n 1 |
X (n) |
||||||
|
|
||||||
|
|
|
|
|
|||
|
n |
|
(n))2 |
|
|
|
( X i |
X |
|
||
|
i 1 |
. |
|||
n 1 |
|||||
|
|
||||
При больших значениях n обе оценки - смещенная DX (n) и
несмещенная S2 (n) − будут различаться очень мало и тогда введение поправочного множителя теряет смысл.
3.8 Доверительный интервал и доверительная вероятность
В предыдущих разделах рассмотрен вопрос об оценках неизвестных параметров распределений одним числом. Такие оценки называются «точечными». В ряде задач требуется не только найти оценку параметра θ, но и оценить его точность и надежность. Требуется знать – к каким
ошибкам может привести замена параметра θ его точечной оценкой ˆ и
θ
с какой степенью надежности можно ожидать, что эт и ошибки не выйдут за известные пределы ?
Такого рода задачи особенно актуальны при малом числе
наблюдений над случайной величиной Х, когда точечная оценка ˆ в
θ
значительной мере случайна и приближенная замена θ на ˆ может
θ
привести к серьезным ошибкам.
Чтобы дать представление о точности и надежности оценки ˆ , в
θ
математической статистике пользуются так называемыми
доверительными интервалами и доверительными вероятностями .
Пусть для параметра θ по данным наблюдений получена
несмещенная оценка ˆ . Чтобы оценить возможную ошибку при замене
θ
θ его оценкой ˆ , возьмем некоторую достаточно большую вероятность
θ
γ(например, γ=0,9; γ=0,95; γ=0 ,99), такую, что событие с вероятностью
γможно считать практически достоверным. Очевидно , что если δ>0 и

ˆ |
тем оценка точнее. Пусть вероятность того, |
||
|θ− θ |<δ, то чем меньше δ, |
|||
ˆ |
ˆ |
ˆ |
ˆ |
что |θ− θ |<δ равна γ: |
P(| θ θ | δ) γ или |
P(θ δ θ θ δ) γ . |
|
Последнее соотношение следует понимать так: вероятность того, что
ˆ |
ˆ |
заключает |
в себе |
(покрывает) неизвестный |
|
интервал (θ δ, θ δ) |
|||||
параметр θ, равна γ. |
|
|
|
|
|
Вероятность |
γ |
называют |
надежностью |
(доверительной |
|
вероятностью) оценки θ |
ˆ |
ˆ |
ˆ |
доверительным |
|
по θ , а интервал (θ δ, θ δ)– |
|||||
интервалом.
Замечание. Ранее мы неоднократно рассматривали вероятность попадания случайной величины X в заданный (неслучайный) интервал.
Здесь же параметр θ не случайная величина, а случайна величина ˆ и
θ
следовательно, случайны границы доверительного интервала. Поэтому
в данном случае |
лучше толковать |
величину γ не как вероятность |
попадания точки θ |
ˆ |
ˆ |
в интервал (θ δ, θ δ), а как вероятность того, что |
||
этот интервал накроет точку θ.
Перейдем к вопросу о нахождении границ доверительного интервала. Для этого рассмотрим задачу о доверительном интервале для математического ожидания.
Предположим, что X1 , X2 , …, Xn являются независимыми и одинаково распределенными случайными величинами с математическим ожиданием m и конечной дисперсий σ 2 , которые неизвестны. Для этих параметров получены оценки:
|
|
n |
|
/ n ; |
S |
2 |
n |
|
|
|
2 |
/(n 1) , |
|
|
|
|
|
||||||||
X (n) xi |
|
(n) (xi X (n)) |
|
|||||||||
|
|
i 1 |
|
|
|
|
i 1 |
|
|
|
|
|
где xi − возможные |
значения |
|
величин |
Xi . Согласно центральной |
||||||||
предельной теореме, при достаточно большом n закон распределения X (n) близок к нормальному. Характеристики этого закона –
математическое ожидание и дисперсия равны соответственно m и σ2 /n (п.3.3). Тогда польз уясь известной формулой (см. п.3 .4.)
Р(|X−m|<δ)=2Φ0 (δ/σ) и заменив в ней Х на X (n) , σ2 на S2 (n)/n, получим
P(| X (n) m | δ) 2Φ0 (δ
 n / S 2 (n)) 2Φ0 (tγ ) ,
n / S 2 (n)) 2Φ0 (tγ ) ,
где tγ δ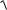
 n / S 2 (n) .
n / S 2 (n) .
Тогда δ tγ 
 S 2 (n) / n и можем записать
S 2 (n) / n и можем записать
P(| X (n) m | tγ 
 S 2 (n) / n ) 2Φ0 (tγ ) .
S 2 (n) / n ) 2Φ0 (tγ ) .
Приняв во внимание, что эта вероятность задана и равна γ, а также найдя значение tγ из равенства Φ0 (tγ )=γ/2 по таблице интеграла Лапласа, можем теперь записать окончательную формулу доверительного интервала для неизвестного математического ожидания:

|
|
(n) t |
|
S 2 (n) / n m |
|
(n) t |
|
S 2 (n) / n . |
|
|
|||||||
X |
γ |
X |
γ |
(3.18) |
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Полученный таким образом интервал называют также 100∙γ − |
|||||||||||||||||
процентным доверительным интервалом для m. |
|
|
|
||||||||||||||
Пример 3.8. |
Произведено 20 опытов над величиной Х; результаты |
||||||||||||||||
приведены в таблице 3 .6. |
|
|
|
|
|
|
|
|
|
|
|
||||||
Табл. 3.6 |
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
i |
|
xi |
|
i |
xi |
i |
|
xi |
|
i |
xi |
|
||
|
|
|
1 |
|
10,5 |
|
6 |
10,6 |
11 |
10,6 |
|
16 |
10,9 |
|
|||
|
2 |
|
10,8 |
|
7 |
10,9 |
12 |
11,3 |
|
17 |
10,8 |
|
|||||
|
3 |
|
11,2 |
|
8 |
11,0 |
13 |
10,5 |
|
18 |
10,7 |
|
|||||
|
4 |
|
10,9 |
|
9 |
10,3 |
14 |
10,7 |
|
19 |
10,9 |
|
|||||
|
5 |
|
10,4 |
|
10 |
10,8 |
15 |
10,8 |
|
20 |
11,0 |
|
|||||
Требуется найти оценку mˆ для математического ожидания m величины X и построить 90-процентный доверительный интервал для m.
Решение. Определим среднее арифметическое
|
|
|
|
|
|
|
|
|
|
1 |
20 |
|
|
|
|
|
|
|
|
X (20) |
10,78. |
|
|||||
|
|
|
|
|
|
|
x |
|
|||||
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
i |
|
|
|
|
|
|
|
|
|
|
|
|
20 i 1 |
|
|
|
Выбрав за |
начало |
отcчета |
x=10 |
находим |
несмещенную оценку |
||||||||
S 2 (20) ( |
13,38 |
0,782 ) |
20 |
|
0,064 . |
|
|
|
|
||||
|
|
|
|
|
|
||||||||
20 |
|
19 |
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|||||||||
Тогда значение |
множителя S 2 (20) / 20 0,0565. |
По таблице интеграла |
|||||||||||
Лапласа находим t0 , 9 0 =1,643. Отсюда доверительный интервал:
10,69<m<10,87.
Пример 3.9. Построим 90 − процентный доверительный интервал для среднего значения m статистической совокуп ности из примера 3 .1. Из п.3.4 имеем следующие оценки X (199) 0,351, S2 (199)=0,081. Отсюда
значения множителя 
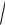 S 2 (199) / n 0,020 . По таблице интеграла Лапласа
S 2 (199) / n 0,020 . По таблице интеграла Лапласа
t =1,643. Отсюда доверительный интервал: 0,318< m<0,384. Доверительный интервал, определенный формулой (3 .18) является
лишь приближенным. Это видно по выкладкам, которые были проделаны при выводе этой формулы. Теперь запишем точное выражение 100∙γ − процентного доверительного интервала для неизвестного математического ожидания m.
Пусть X1 , X2 , …, Xn являются нормально распределенными
|
|
|
|
(n) m |
|
имеет |
случайными величинами. Тогда случайная величина T |
X |
|||||
|
|
|
|
|
||
|
|
|
|
|||
|
|
|
S 2 (n) / n |
|||
распределение Стьюдента с n−1 степенями свободы. Плотность этого
|
|
|
|
|
Γ (n / 2) |
|
t 2 |
) |
n |
||
|
|
|
(t) |
|
(1 |
|
|
||||
распределения имеет вид |
S |
n 1 |
|
2 . |
|||||||
|
|
|
|
||||||||
|
|
|
|
(n 1)π Γ ((n 1) / 2) |
|
n 1 |
|
|
|||
|
|
|
|
|
|
|
|
||||

В этом случае также говорят, что случайная величина T имеет t – распределение с n−1 степенями свободы.
Точный (для любого n≥2) 100∙γ – процентный доверительный интервал для m определяется как
|
|
(n) t |
|
S 2 |
(n) / n m |
|
(n) t |
|
S 2 |
|
|
X |
n 1,γ |
X |
n 1,γ |
(n) / n, |
(3.19) |
||||||
|
|
|
|
|
|
|
|
|
|
||
где tn 1, γ − |
верхняя критическая точка для t – |
распределения с n−1 |
|||||||||
степенями свободы определяется из условия
tn 1, γ
2 Sn 1 (t) dt γ .
0
Таким образом, при выводе формулы (2 .19) использована случайная величина T.
Таблица значений критических точек tn 1,γ приведена в приложении
(табл.5).
Пример 3.10. Построить 90%-й доверительный интервал для m по данным примера 3 .8. Ранее были определены оценки: X (20) 10,78 , S2 (20)=0,064, а также величина

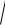 S 2 (20) / 20 0,0565.
S 2 (20) / 20 0,0565.
По таблице значений tn 1, γ находим значение t1 9 ; 0 , 9 =1,729. Тогда 90%-й
доверительный интервал будет 10,68< m<10,88.
Таким образом, доверительный интервал, определяе мый формулой (3.19) шире, чем (3.18). Этот факт иллюстрирует и рис. 3.13, где приведены графики плотности t − распределения с 4 -мя степенями свободы и стандартного нормального распределения.
f(x) |
Стандартное нормальное |
|
распределение |
|
t-распределение с 4-мя |
|
степенями свободы |
0 |
tγ tn-1,γ x |
Рис.3.13
Кривая t − распределения меньше поднимается вверх и имеет боле е длинные хвосты, чем кривая нормального распределения и поэтому для
любого конечного n справедливо неравенство tn 1, γ tγ . В тех случаях,
когда n довольно небольшое число, разница между (3.18) и (3.19) будет ощутимой.
Выше мы рассматривали задачу построения доверительного интервала для неизвестного математического ожидания. Точно также

определяется доверительный интервал для дисперсии D. Только при его получении используется случайная величина U=(n−1)S2 (n)/D, которая имеет распределение χ 2 с n−1 степенями свободы (см.п.2 .5). Выразим
случайную величину – оценку S2 (n) через U: S 2 (n) U D . Зная закон n 1
распределения величины U, можно найти для нее доверительный интервал с надежностью γ. Доверительный интервал построим таким образом, чтобы вероятности выхода величины U за пределы интервала вправо и влево (заштрихованные площа ди на рис.3.14) были одинаковы и равны
1 .
2 2
Воспользуемся таблицей значений χ 2кр (α, r) для случая r=n−1 и в
соответствующей строке найдем два значения χ 2 : одно, отвечающее вероятности α1 =α/2; другое – вероятности α2 =1−(α/2). Обозначим эти
значения χ12 и χ22 , причем χ12 будет правым концом доверительного интервала, а χ22 −левым.
fr(U)
0 χ 22 |
χ12 |
U |
доверительный интервал
Рис. 3.14
Таким образом, построим доверительный интервал для дисперсии с границами D1 и D2 , который накрывает точку D с вероятностью γ:
P(D1 D D2 ) γ .
Потребуем также одновременного выполнения условия
|
|
|
|
|
P(χ |
2 |
U χ 2 ) γ . |
|
|
|
|
|||
|
|
|
|
|
|
2 |
|
1 |
|
|
|
|
|
|
Учитывая, что |
неравенства U χ 2 |
|
и U χ 2 |
равносильны |
||||||||||
|
|
|
|
|
|
|
|
1 |
|
|
2 |
|
||
неравенствам |
|
(n 1)S 2 (n) |
D |
|
и |
|
(n 1)S 2 (n) |
D , |
|
|||||
|
χ12 |
|
|
|
|
χ |
22 |
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
||||
то следующий интервал |
|
|
|
|
|
|
|
|
|
|
|
|||
|
(n 1)S |
2 (n) |
D |
(n 1)S 2 (n) |
|
|
|
|
(3.20) |
|||||
|
|
χ12 |
|
|
χ 22 |
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
||||
является 100∙γ − процентным доверительным интервалом для неизвестной дисперсии.
Пример 3.11. Найти 90%-й доверительный интервал дл я дисперсии в условиях примера 3 .8, если известно, что величина Х распределена нормально.
Решение. Имеем γ=0,9; α=0,1; α/2=0,05. По таблице значений χ 2 (α,r) при r=n−1=19 находим
для α1 α2 0,05: χ12 30,1; для α2 1 α2 0,95: χ22 10,11.
Учитывая, что S2 (20)=0,064, используя формулу (3 .20), получим 90%-й доверительный интервал для дисперсии: 0,04< D<0,12.
3.9 Связь между доверительным интервалом и проверкой гипотез о среднем значении
В п.8.8 были даны два вида доверительных интервалов для неизвестного среднего значения m величины X; формула (3.18) − для приближенного доверительного ин тервала; а формула (3 .19) − для точного. Более правильной будет следующая интерпретац ия доверительного интервала.Если будет построено большое количество независимых 100∙γ – процентных доверительных интервалов, каждый из которых основывается на n разных наблюдениях, где n − достаточно большое число, то доля интервалов, которые содержат ( покрывают) m, будет равна γ. Эта доля и называется покрытием для доверительного интервала.
На покрытие доверительного интервала (3 .19) оказывает влияние вид распределения величин Xi . В таблице 3.7 представлена оценка покрытия для 90%-х доверительных интервалов, основанная на 500 независимых экспериментах, при разных объемах выборок n (5, 10, 20 и 40) и таких распределениях как: нормальное, экспоненциальное, «хи – квадрат» с одной степенью свободы, логнормальное ( ey , где Y - стандартная нормальная случайная величины), а также гиперэкспоненциальное, функция распределения которого
F(x) 0,9(1 e 2x ) 0,1(1 e 2x /11) .
Табл. 3.7
Распределение |
Аcимме |
n=5 |
n=10 |
n=20 |
n=40 |
|
трия |
||||||
|
|
|
|
|
||
Нормальное |
0,00 |
0,910 |
0,902 |
0,898 |
0,900 |
|
Экспоненциальное |
2,00 |
0,854 |
0,878 |
0,870 |
0,890 |
|
Хи-квадрат |
2,83 |
0,810 |
0,830 |
0,848 |
0,890 |
|
Логнормальное |
6,18 |
0,758 |
0,768 |
0,842 |
0,852 |

Гиперэкспоненциальн |
6,43 |
0,584 |
0,586 |
0,682 |
0,774 |
|
ое |
||||||
|
|
|
|
|
Например, значение 0,878 при n=10 для экспоненциального распределения получено следующим образом. Десять наблюдений сгенерировали по экспоненциальному распределению с известным средним значением m, а 90%-й доверительный интервал построили по выражению (3.19) и определили, содержит ли этот интервал среднее значение m (это один эксперимент). Затем всю процедуру повторили 500 раз, и доля интервалов, содержащих значение m, в 500-х доверительных интервалах составила 0,878.
Как следует из таблицы 3.7, для отдельного распределения покрытие становится ближе к 0,90 по мере возрастания n, что следует из центральной предельной теоремы. Кроме того, для конкретного n покрытие уменьшается по мере увеличения асимметрии. Следовательно, чем больше асимметрия у распределения, тем больший объем выборки необходим для получения удовлетворительного (близкого к 0,90) покрытия.
Далее рассмотрим следующую задачу. Допустим, что величины X1 , X2 ,…, Xn являются нормально распределенными (или приближенно нормально распределенными) и что следует проверить нулевую гипотезу Н0 , согласно которой m=m0 , где m0 - заданное гипотетическое
значение m. Интуитивно ясно, что если X (n) m0 является большой
величиной, то гипотеза Н0 не может быть истиной ( X (n) – точечная
несмещенная оценка m).
Воспользуемся статистикой (функцией величины Xi ), распределение
которой известно, когда гипотеза Н0 истинна. Отсюда следует, что если |
|||||||
|
|
|
|
X(n) m / |
|
|
|
гипотеза Н0 |
истинна, статистика t |
n |
S 2 |
(n) / n будет иметь t − |
|||
|
|
0 |
|
|
|
||
распределение с n−1 степенями свободы. Тогда «двусторонний» критерий проверки гипотезы Н0 : m=m0 при конкурирующей гипотезе Н1 : m≠m0 будет иметь следующую форму:
t |
n-1,γ |
, то H |
0 |
опровергается; |
|
|
|
|
|
(3.21) |
|||
если | tn | |
|
|
|
|
принимается, |
|
|
|
, то H |
|
|
||
t |
n 1, γ |
0 |
|
|||
|
|
|
|
|
||
где tn − 1 , γ – критическая точка t – распределения.
Отрезок числовой оси, соответствующий опровержению Н0 , а именно: множество всех х, для которых |x|> tn − 1 , γ , называется критической областью критерия, а вероятность попадания статистики tn в критическую область при условии, что гипотеза Н0 является истиной, равна α и называется уровнем значимости критерия. Как правило, выбирается уровень α, равный 0,05 или 0,1 0. Критерий проверки гипотезы (3 .21) называется t – критерий, а критические

значения tn − 1 , γ мы уже использовали при построении довер ительных интервалов по формуле (3 .19).
При проверке гипотезы встречаются два вида ошибок.
1. Если отвергнуть гипотезу Н0 тогда как она верна, допускают ошибку первого рода. Вероятность ошибки первого рода равна уровню значимости α и, следовательно, находит ся под контролем исследователя.
2. Если же принимать гипотезу Н0 тогда, когда она ложна, допускают ошибку второго рода. Вероятность ошибки второго рода для заданного уровня α и объема выборки n обозначается β. Она зависит от того, что в действительности пр авильно (в сравнении с Н0 ), и может быть неизвестна.
Мощностью критерия называют величину δ=1−β. Она равна вероятности опровержения гипотезы Н0 , когда она ложна, а верна конкурирующая гипотеза. (Желательно, чтобы критерий имел высокую мощность).
При заданном α мощность критерия можно увеличить только путем увеличения числа опытов n и только так можно добиться уменьшения ошибок первого и второго рода.
Так как мощность критерия может быть невелика и неизвестна, далее, когда статистика tn не будет попадать в критическую область, будем считать, что гипотеза Н0 не опровергается (вместо « Н0 принимается»).
Когда Н0 не опровергается, часто точно неизвестно, правильна Н0 или ложна, поскольку критерию недостает мощности, чтобы обнаружить различия между нулевой гипотезой Н0 и тем, что в действительности правильно. В этом состоит главный недостаток критериев проверки гипотез.
Далее сравним критерий проверки гипотез (3.21) и доверительный
интервал (3.19). Проверяя гипотезу Н0 : m=m0 |
при Н1 : m≠m0 , мы требуем, |
|||||
|
|
|
|
/ |
|
в |
чтобы вероятность попадания критерия |
|
(n) m |
S 2 (n) / n |
|||
X |
||||||
|
0 |
|
|
|
||
двустороннюю критическую область (3 .21) была равна уровню значимости α, следовательно, вероятность попадания критерия в область принятия гипотезы (− tn − 1 , γ , tn − 1 , γ ) равна 1−α=γ. Другими словами, с надежностью γ выполняется неравенство
tn 1,γ Х (n) m0 / 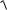
 S 2 (n) / n tn 1,γ ,
S 2 (n) / n tn 1,γ ,
или равносильное неравенство
Х (n) tn 1,γ 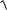
 S 2 (n) / n m Х (n) tn 1,γ
S 2 (n) / n m Х (n) tn 1,γ 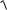
 S 2 (n) / n .
S 2 (n) / n .
Таким образом, мы получим доверительный интервал (3.19) для оценки неизвестного математического ожидания m нормального распределения с надежностью γ.
Замечание. Хотя построение доверительного интервала для m и двусторонней критической области для проверки гипотезы Н0 : m=m0 и

приводят к одинаковым результатам, их истолкование различно. Двусторонняя критическая область определяет границы (критические точки), между которыми заключена доля, равная γ=(1−α) наблюдаемых критериев, найденных при повторении опытов. Доверительный же интервал определяет границы (концы интервала), между которыми заключена доля покрытия, равная γ, попавших в него значений оцениваемого параметра (см. пояснение к табл.3 .7).
Пример 3.12. Возьмем данные из примера 3 .8. Предположим, что они получены из нормального распределения с неизвестным средним значением m. Проверим для этих данных на уровне α=0,01 нулевую гипотезу Н0 : m=10,5, при конкурирующей гипотезе Н1 : m=10,8.
|
|
|
|
|
|
(20) 10,5 |
|
10,78 10,5 |
4,96 1,73 t |
|
|
Поскольку t |
|
X |
|
, |
|||||||
20 |
|
|
|
|
|
|
|||||
|
|
|
|
S 2 (20) / 20 |
|
0,0565 |
19; 0,9 |
|
|||
|
|
|
|
|
|
|
|
||||
мы опровергаем гипотезу Н0 . Этого следовало ожидать, так как значение m0 =10,5 не попадает в доверительный интервал для m: 10,68 < m < 10,88, построенный с надежностью γ=0,90 в прим ере 3.10.
3.11 Точечные оценки для числовых характеристик многомерных случайных величин
В предыдущих пунктах мы рассмотрели задачи, связанные с оценками для числовых характеристик одномерной случайной величины при ограниченном числе опытов и построением для них доверительных интервалов.
Аналогичные вопросы возникают и при обработке ограниченного числа наблюдений над двумя и более случ айными величинами.
Рассмотрим сначала случай двумерной случайной величины ( X,Y). Пусть нами получены результаты n независимых опытов над величиной (X,Y) в виде пар значений ( x1 ,y1 ), (x2 ,y2 ),…,(xn ,yn ). Требуется найти оценки для числовых характеристик: мат ематических ожиданий mx , my , дисперсий Dx , Dy , ковариации cov(X,Y), коэффициента корреляции ρ( х, у) и коэффициентов регрессии β х у , βу х .
Оценки для математических ожиданий и дисперсий будут такими же, как и в случае одномерной величины. Несмещенными оценками для математических ожиданий будут средние арифметические:
|
|
n |
|
|
n |
|
X |
(n) ( xi ) / n; |
Y |
(n) ( yi ) / n, |
|
|
|
i 1 |
|
|
i 1 |
а для элементов ковариационной матрицы -
S 2 |
n |
|
|
|
(n))2 /(n 1); |
S 2 |
n |
|
|
|
(n))2 |
|
(n) |
(x |
|
Х |
(n) ( y |
i |
Y |
/(n 1); |
|||||
x |
i 1 |
i |
|
|
|
y |
i 1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
n
σˆxy coˆv( X ,Y ) (xi Х (n))( yi Y (n)) /(n 1).
i 1
Оценкой коэффициента корреляции будет величина