

Umk_Oed
.pdfh c |
2(h |
h |
) c |
i |
h |
c |
6 ( |
yi 1 yi |
|
yi yi 1 |
), |
(i 1,2,...,n) |
|||
|
|
||||||||||||||
|
i i 1 |
|
i |
|
i 1 |
|
i 1 i 1 |
|
h i 1 |
|
h i |
(2.3) |
|||
|
|
|
|
|
|
|
|
|
|
|
|
||||
c |
0 |
c |
n |
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Система (2.3) имеет трехдиагональную матрицу. Эта система может быть решена методом прогонки или Гаусса. Метод прогонк и рассматривается в пункте 6.7.2 учебного пособия.
После решения системы коэффициенты сплайна di, bi определим через коэффициенты сi с помощью явных формул
d |
|
|
c i |
c i 1 |
, |
|
|
|
|
|
|
|
|||
i |
|
|
hi |
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
h |
|
|
h2 |
|
|
y y |
i 1 |
|
|
|
|
b |
|
i |
c |
|
i |
d |
i |
|
i |
(i= 1,2,…,n). |
|||
|
|
|
|
|
|
|
|||||||||
|
|
|
i |
|
2 |
i |
|
6 |
|
|
hi |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
||||
Существуют специальные виды записи сплайнов на каждом из промежутков [xi ,xi + 1 ] [9], которые позволяют уменьшить число неизвестных коэффициентов сплайна. Вводятся обозначения
|
i 0,1,...,n , |
|
|
|
|
|
|
|
S (xi ) mi , |
|
|
|
|
|
|
||
hi xi 1 xi |
и t (x xi )/hi . |
|
|
|
|
|
|
|
На отрезке [xi ,xi + 1 ] кубический сплайн записывается в виде |
||||||||
S(x) y (1 t)2 (1 2t) y |
t 2 (3 2t) m |
h |
t(1 t)2 |
m |
t 2 |
(1 t)h |
. |
|
i |
i 1 |
i |
i |
|
|
i 1 |
i |
|
Кубический сплайн, записанный в таком виде, на каждом из промежутков [xi ,xi + 1 ] непрерывен вместе со своей первой производной на [a,b].
Выберем mi таким образом, чтобы и вторая производная была непрерывна во всех внутренних узлах. Отсюда получим систему уравнений:
λ |
i |
m |
i 1 |
2m |
μ m |
3( μ |
i |
yi 1 yi |
λ |
i |
yi yi 1 |
) , |
|||||||||||
|
|
|
|||||||||||||||||||||
|
|
|
i |
|
i |
i 1 |
|
|
|
h i |
|
|
|
h i 1 |
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
где μ i |
|
hi 1 |
|
, λi |
1 |
μ i |
|
|
|
|
hi |
, |
|
i 1,2,...,n 1. |
|||||||||
|
h i 1 hi |
|
hi 1 hi |
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
К этим уравнениям добавим уравнения, полученные из граничных |
|||||||||||||||||||||||
условий |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
2m m 3 |
y1 y0 |
, |
m |
n 1 |
2m 3 |
yn yn 1 |
. |
||||||||||||||||
|
|
||||||||||||||||||||||
|
|
0 |
|
|
1 |
|
|
h0 |
|
|
|
|
n |
|
|
hn 1 |
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
В результате получаем аналогичную систему с трехдиагональной матрицей. Решаем систему линейных уравнений относительно коэффициентов mi методом пргонки.

2.2. Сходимость процесса интерполирования кубическими сплайнами
Доказывается, что при неограниченном увеличении числа узлов на одном и том же отрезке [ a,b] S(x) f (x) . Оценка погрешности
интерполяции R(x) f (x) S(x) зависит от выбора сетки и степени
гладкости функции f(x). При равномерной сетке
xi a i h (i=0,1,…,n)
f (x) Sh (x) |
|
|
M |
4 |
h4 |
, |
||
|
||||||||
|
|
|
||||||
|
|
8 |
||||||
|
|
|
|
|
|
|
||
где M |
4 |
max | f IV (x) |. |
|
|||||
|
[a,b] |
|
|
|
|
|||
|
|
|
|
|
|
|||
Другие постановки задачи интерполирования функций.
1. Если функция периодическая, то используется тригонометрическая интерполяция с периодом l, которая строится с помощью тригонометрического многочлена
Tn (x) a0 |
(ak cos kx |
bk sin kx) , |
|
|
n |
|
|
|
k 1 |
l |
l |
коэффициенты которого находятся из системы уравнений
Tn (xi ) f (xi ) (i= 1,2,…, 2n+1).
2. Выделяют приближение функций рациональными, дробно – рациональными и другими функциями. В данном пособии эти вопросы не рассматриваются.
2.4 Аппроксимация функций методом наименьших квадратов
К такой задаче приходят при статистической обработке экспериментальных данных с помощью регрессионного анализа. Пусть
в результате |
исследования |
некоторой |
величины |
x значениям |
x1 ,x2 ,x3 ,...,xn |
поставлены в |
соответствие |
значения |
y1,y2,y3,...,yn |
некоторой величины у.
Требуется подобрать вид аппроксимирующей зависимости y=f(x), связывающей переменные х и у. Здесь могут иметь место следующие случаи. Во-первых: значения функции f(x) могут быть заданы в достаточно большом количестве узлов; во-вторых: значения таблично заданной функции отягощены погрешностями. Тогда проводить приближения функции с помощью интерполяционного многочлена нецелесообразно, т.к.
- число узлов велико и пришлось бы строить несколько интерполяционных многочленов;
- построив интерполяционные многочлены, мы повторили бы те же самые ошибки, которые присущи таблице.
Будем искать приближающую функцию из следующих соображений:
1)приближающая функция не проходит через узлы таблицы и не повторяет ошибки табличной функции;
2)чтобы сумма квадратов отклонений приближающей функции от таблично заданной в узлах таблицы была минимальной.
у
уn
yn-1 
 отклонения y1
отклонения y1
y0
х0 |
х1 … хn-1 хn |
х |
Рисунок 6 – Графическое изображение отклонений приближающей функции от таблично заданной
Рассмотрим линейную задачу наименьших квадратов. Определение. Уровень погрешности, допускаемый при снятии
характеристики измеряемой величины, называется шумом таблицы. Пусть функция y=f(x) задана таблицей приближенных значений
yi f(xi ), i=0,1,…,n, полученных с ошибками i yi0 yi , где yi0 f (xi) . Пусть даны функции 0( x ), 1( x ),..., m( x ), назовем их базисными
функциями.
Будем искать приближающую (аппроксимирующую) функцию в виде линейной комбинации базисных функций
y Фm (x) c0 0 (x) c1 1(x) ... cm m (x). |
(2.11) |
Такая аппроксимация называется линейной, а Фm (х) – обобщенным многочленом.
Будем определять коэффициенты обобщенного многочлена c0 ,…,cm используя критерий метода наименьших квадратов. Согласно этому критерию вычислим сумму квадратов отклонений таблично заданной функции от искомого многочлена в узлах:
n |
n |
|
m ( yi Фm (xi ))2 |
( yi c0 0 (xi ) ... cm m (xi ))2 . |
(2.12) |
i 0 |
i 0 |
|

Выражение для m можно рассматривать как функцию от неизвестных c0 ,…, cm . Нас интересует, при каких значениях c0 ,…, cm , значение m будет минимально.
Для этого воспользуемся условием существования экстремума функции, а именно, найдем частные производные от m по всем переменным c0 ,…, cm и приравняем их к нулю. Получим систему вида:
∂m∂c0
. .
∂m
∂cm
n |
|
|
|
|
2 ( yi c0 0 |
(xi ) |
... cm m (xi )) 0 (xi ) 0 |
|
|
i 0 |
|
|
|
|
. . . . . . . . |
. . . . . . . |
. |
(2.13) |
|
n |
|
|
|
|
2 ( yi c0 0 |
(xi ) |
... cm m (xi )) m (xi ) 0 |
|
|
i 0 |
|
|
|
|
Система (2.13) – система линейных уравнений относительно c0 ,…,
cm .
Чтобы систему (1.13) записать компактно, ведем определение. Определение. Скалярным произведением функций f на g на
множестве точек |
x0 ,..., xn |
называется выражение |
|
||||||
|
|
|
|
|
|
|
n |
|
|
|
|
|
|
( f , g) f (xi ) g(xi ) . |
|
||||
|
|
|
|
|
|
i 0 |
|
||
Тогда систему (1.13) можно записать в виде: |
|
||||||||
c0 ( 0 , 0 ) c1( 0 , 1) ... cm ( 0 , m ) ( 0 , y) |
|
||||||||
c ( , |
0 |
) c ( , ) ... c |
m |
( , |
m |
) ( , y) |
|
||
0 1 |
|
1 1 1 |
|
1 |
1 |
(2.13а) |
|||
|
|
|
|
|
|
|
|
. |
|
. . . . . . . . . . . . . . . |
|
||||||||
c0 ( m , 0 ) c1( m , 1 ) ... cm ( m , m ) ( m , y)
Системы (2.13) или (2.13а) будем называть нормальной системой уравнений.
Решив ее, мы найдем коэффициенты c0 ,…,cm и следовательно, найдем вид аппроксимирующего многочлена. Напомним, что это возможно, если базисные функции линейно независимы, а все узлы различны.
Осталось определить степень многочлена m. Прямому вычислению поддаются только значения среднеквадратичного отклонения m ,
анализируя которые будем выбирать степень многочлена. Алгоритм выбора степени многочлена m.
В случае, когда m=n мы получим интерполяционный многочлен, поэтому выберем m<<n. Так же необходимо задать числа ε1 и ε2 , учитывая следующее:
1) 1 >0 и 2 >0 должны быть такими, чтобы m находилось между ними;
2)первоначально m выбирают произвольно, но учитывая условие, что m<<n;
3)выбрав m, строят системы (2.13) и (2 .13a), решив которые, находят c0 ,…, cm ;
4)используя найденные коэффициенты, вычисляется m и
проверяется, попало ли оно в промежуток между 1 и 2 . Если попало, то степень многочлена выбрана правильно, иначе
а) если m > 1 , то степень необходимо уменьшить хотя бы на единицу;
б) если m < 2 , то степень необходимо увеличить хотя бы на
единицу.
5) затем строим приближающую функцию .
Очень часто для приближения по методу наименьших квадратов используются алгебраические многочлены степени m n, т.е. k ( x ) x k . Тогда нормальная система (2 .13) принимает следующий вид:
m |
|
n |
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
( |
x j k ) c |
j |
y x k |
, (k= 0,1,…,m). |
(2.14) |
||||||||||||
j 0 |
|
i |
|
|
|
i |
|
|
i |
|
|
|
|
|
|
||
i 0 |
|
|
|
|
|
i 0 |
|
|
|
|
|
|
|
|
|
||
Запишем систему (2 .14) в развернутом виде в двух наиболее |
|||||||||||||||||
простых случаях m =1 и m =2. |
|
|
|
|
|
|
|
|
|
||||||||
В случае многочлена первой степени P1 (x)=c0 +c1 x, нормальная |
|||||||||||||||||
система имеет вид |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
(n 1) c |
n |
|
|
|
|
n |
|
|
|
|
|||||
|
|
( x |
i |
) c |
y |
i |
|
|
|||||||||
|
|
|
|
|
|
0 |
i 0 |
|
1 |
|
i 0 |
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(2.15) |
|||
|
|
|
n |
|
|
|
|
n |
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
||||
|
|
( x i ) c0 ( x i |
) c1 yi x i . |
|
|
||||||||||||
|
|
i 0 |
|
|
|
|
i 0 |
|
|
|
|
i 0 |
|
|
|
||
Для многочлена второй степени P2 (x)=c0 +c1 x+c2 x2 , нормальная |
|||||||||||||||||
система имеет вид |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
(n 1)c |
n |
|
|
|
|
n |
|
|
|
|
|
n |
|
|
|||
( x )c |
( x2 )c |
y |
|
|
|||||||||||||
|
|
0 |
i 0 |
i |
|
|
1 |
i 0 |
|
i |
2 |
|
|
i |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
i 0 |
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
n |
2 |
)c1 |
n |
|
|
3 |
|
|
n |
|
(2.16) |
|||
( xi )c0 |
( xi |
( xi )c2 |
yi xi . |
||||||||||||||
i 0 |
|
|
i 0 |
|
|
|
|
i 0 |
|
|
|
i 0 |
|
|
|||
n |
2 |
|
n |
|
3 |
|
n |
|
4 |
|
|
|
n |
2 |
|
||
( xi |
)c0 ( xi |
|
)c1 ( xi |
)c2 yi xi |
|
||||||||||||
i 0 |
|
|
i 0 |
|
|
|
|
i 0 |
|
|
|
i 0 |
|
|
|||
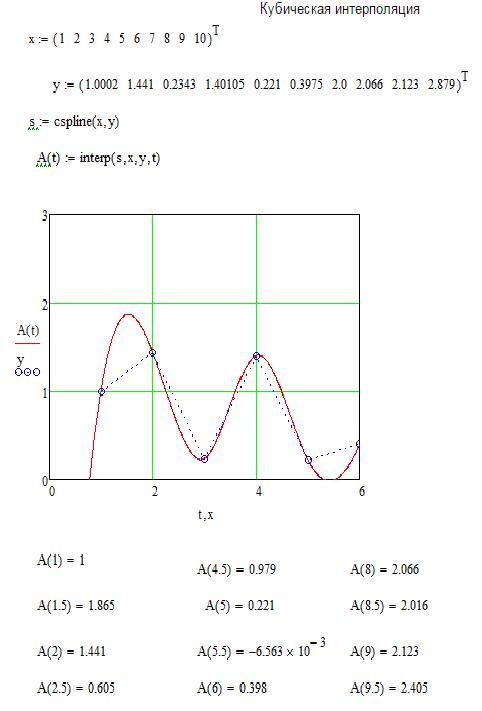
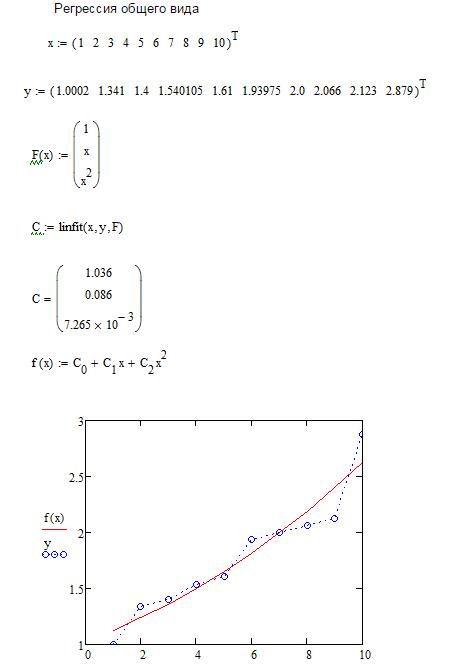
Задание №1 на самостоятельную работу. Для данных, приведенных в таблице: 1) выполнить интерполяцию сплайном 3 -го порядка; 2) выполнить аппроксимацию данных по методу наименьших квадрат ов с подбором аппроксимирующей функции.
Пример выполнения заданий приведен ниже.
Лекции 3, 4. ЭЛЕМЕНТЫ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ Основные задачи математической статистики
Математические законы теории вероятностей не являются лишь абстрактными, лишенными физического содержания. Они представляют собой математическое выражение реальных закономерностей в массовых случайных явлениях природы. В основе таких понятий, как события и их вероятности, случайные величины, их законы распределения и числовые характеристики лежит опыт; каждое исследование случайных явлений методами теории вероятностей опирается на экспериментальные опытные данные или систему наблюдений.
Разработка методов регистрации, описания и анализа
статистических (экспериментальных) данных, получаемых в результате наблюдения массовых случайных явлений и составляет предмет науки
–математической статистики.
Взависимости от характера решаемого практического вопроса и от объема экспериментального материала задачи математической
статистики можно разделить на типичные.
1. Задача определения закона распределения случайной величины по статистическим данным.
На практике нам всегда приходится иметь дело с ограниченным количеством экспериментальных данных, в связи с этим результаты наблюдений и их обработки всегда содержат больший или меньший элемент случайности. При этом важно уметь выделить как постоянные и устойчивые признаки явления, так и случайные, проявляющиеся в данной серии наблюдений только за счет ограниченного объема экспериментальных данных. В связи с этим возникает характерная задача группировки, сглаживания или выравнивания статистических данных, представления их в компактном виде с помощью аналитических зависимостей.
2. Задача проверки правдоподобия гипотез.
Статистические данные могут с большим или меньшим правдоподобием подтверждать или не подтверждать справедливость той или иной статистической гипотезы. Например, ставится такой вопрос: согласуются или нет данные эксперимента с гипотезой о том, что данная случайная величин а или признак подчинены тому или иному закону распределения? Другой подобный вопрос: указывают ли данные наблюдений на наличие объективной зависимости случайной величины от одной или нескольких случайных величин? Для решения подобных вопросов существуют ме тоды проверки статистических гипотез с помощью критериев согласия.
3. Задача определения неизвестных параметров распределения.
Часто при обработке статистических данных нет необходимости определения законов распределения исследуемых случайных величин
(признаков). Или же характер закона распределения известен заранее (до опыта). Тогда возникает более узкая задача обработки данных – определить только некоторые числовые характеристики случайной величины, оценить их точность и надежность.
Таким образом, здесь перечислены только те задачи математической статистики, которые наиболее важны по своим практическим применениям.
3.2 Статистическая совокупность и статистическая функция распределения
Предположим, что изучается некоторая случайная величина Х, закон распределения которой неизвестен и требуется определить этот закон по данным наблюдений (опытным данным). Совокупность наблюдений Х1 , Х2 , …, Хn и представляет собой статистическую совокупность. Иногда говорят, что получена выборка объема n. При большом n весь диапазон значений Хi делят на k интервалов (разрядов) и подсчитывают количество значений mi , приходящихся на i-й интервал.
Это число делят на общее число наблюдений n и получают частоту, соответствующую данному интервалу: pi mi / n. Для контроля: сумма
частот всех интервалов равна единице. Тем самым значения Хi будут отсортированы в порядке возрастания. Таблица с указанием разрядов и соответствующих им частот значений Хi называется статистическим рядом. Таким образом, мы получаем сгруппированные данные.
Определение. Статистической функцией распределения
случайной величины Х называется частота события Х<х в данной статистической совокупности:
Fn (x)=p *(X<x).
Для того, чтобы найти значение статистической ф ункции распределения при данном х, достаточно подсчитать число опытов, в которых величина Х приняла значение меньше х, и разделить на общее число n произведенных опытов. Статистическая функция распределения любой случайной величины (дискретной или непрерыв ной) представляет собой ступенчатую функцию, скачки которой соответствуют наблюденным значениям случайной величины и по величине равны частотам этих значений. Но при больших значениях n (когда сотни скачков), построение функции Fn (x) трудоемко и себя не оправдывает. Другой способ построения Fn (x) будет рассмотрен ниже.
При увеличении числа опытов n, согласно теореме Бернулли, частота события сходится по вероятности к вероятности этого события. Следовательно, при увеличении n статистическая функция распределения Fn (x) сходится по вероятности к подлинной функции распределения F(x) случайной величины Х. По сути самого определения