

Глава. Введение в теорию кодирования.
Будем
называть ![]() исходным алфавитом, а
исходным алфавитом, а ![]() кодовым алфавитом (выходным).
кодовым алфавитом (выходным).
Определение.
Кодирование будем называть функцию
![]() ,
отображение алфавита
,
отображение алфавита ![]() в множество слов
в множество слов ![]() ,
причем различным буквам в алфавите
,
причем различным буквам в алфавите ![]() должны соответствовать различные слова
из множества слов
должны соответствовать различные слова
из множества слов ![]() в алфавите
в алфавите ![]() .
.
Определение.
Пусть ![]() некоторое исходное слово в алфавите
некоторое исходное слово в алфавите
![]() .
Тогда кодирующим словом, согласно
кодированию
.
Тогда кодирующим словом, согласно
кодированию ![]() ,
называют слово
,
называют слово ![]() ,
полученное соединением соответствующих
кодовых слов (побуквенное кодирование
исходного слова):
,
полученное соединением соответствующих
кодовых слов (побуквенное кодирование
исходного слова):![]()
Пример.
Исходный алфавит ![]() ,
выходной алфавит
,
выходной алфавит ![]() .
Функция
.
Функция ![]() .
Т.к. образы различны, то имеем по
определению кодирование. Слова
.
Т.к. образы различны, то имеем по
определению кодирование. Слова ![]() и
и ![]() ,
соответствующие отдельным буквам, будем
называть кодовыми. Ну и для примера,
закодируем слово:
,
соответствующие отдельным буквам, будем
называть кодовыми. Ну и для примера,
закодируем слово: ![]() .
.
Определение.
Кодирование называют корректным
(правильным), если различным исходным
словам будут соответствовать различные
кодирующие слова, согласно кодированию
![]() .
.
Приведенный
пример является корректным кодированием,
т.к. кодовые слова имеют одну и ту же
длину. Действительно, по образу в данной
кодировке можно определить исходное
слово, считывая образ слева направо и
сворачивая кодовые слова в исходные
буквы:
![]()
![]()
Пример.
Исходный алфавит ![]() ,
кодовый алфавит
,
кодовый алфавит ![]() .
Функция
.
Функция 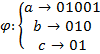 .
Данное кодирование будет некорректно,
т.к. слово 01001 можно раскодировать
по-разному:
.
Данное кодирование будет некорректно,
т.к. слово 01001 можно раскодировать
по-разному:
![]()
![]()
Определение. Суффиксным кодированием называют кодирование, при котором никакое кодовое слово не начинается ни на какое другое кодовое слово.
Утверждение. Каждое суффиксное кодирование является корректным.
Исходное слово можно восстановить по закодированному слову однозначным образом, читая слово слева направо и сворачивая кодовые слова в исходные буквы. Т.к. ни одно кодовое не является началом другого кодового слова, то такое декодирование корректно.
Аналогично можно ввести понятие постфиксного кодирования.
Определение. Постфиксным кодированием называют кодирование, при котором ни одно из кодовых слов не является концом никакого другого кодового слова.
Утверждение. Постфиксное кодирование корректно.
Доказательство аналогично предыдущему утверждению.
Теория кодирования.
![]() – исходный алфавит из
– исходный алфавит из ![]() букв,
букв, ![]() – кодовый алфавит из
– кодовый алфавит из ![]() букв,
букв, ![]() – функция кодирования,
– функция кодирования, ![]() .
.
Различным
буквам сопоставляются различные слова.
Применим следующие обозначения:
![]() – длины кодовых слов, равные
– длины кодовых слов, равные ![]() соответственно.
соответственно.
![]() – общая длина кодовых слов.
– общая длина кодовых слов.
![]() – максимальное число кодовых слов,
которые размещаются в некотором другом
кодовом слове.
– максимальное число кодовых слов,
которые размещаются в некотором другом
кодовом слове.
Критерий
однозначности кодирования.
Если кодирование некорректное, то
обязательно найдется пара различных
слов в исходном алфавите ![]() ,
длина которых не превосходит
,
длина которых не превосходит
![]()
![]()
![]() и которые отображаются в одно и то же
кодирующее слово.
Таким образом, для
проверки корректности кодирования
достаточно перебрать лишь только
исходные слова, длина которых не
превосходит
и которые отображаются в одно и то же
кодирующее слово.
Таким образом, для
проверки корректности кодирования
достаточно перебрать лишь только
исходные слова, длина которых не
превосходит![]() и посмотреть на кодирующие слова. Если
среди кодирующих слов найдутся одинаковые,
то кодирование некорректное. А если
среди кодирующих все слова различны,
то кодирование корректно.
и посмотреть на кодирующие слова. Если
среди кодирующих слов найдутся одинаковые,
то кодирование некорректное. А если
среди кодирующих все слова различны,
то кодирование корректно.
Доказательство (принадлежит Маркову).
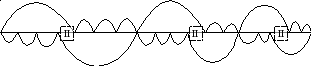
Рассмотрим
кодирование слова минимальной длины,
которое допускает, по крайней мере, две
различных расшифровки, т.е. для которого
найдется, по крайней мере, два различных
исходных слова, кодирующим для которых
является данное слово. Рассмотрим две
различных его расшифровки. Кодовые
слова первой расшифровки обведены
сверху, а кодовые слова второй расшифровки
– снизу. Разрежем кодирующее слово по
границам кодовых слов. В результате
получим слова-отрезки. Эти слова разобьем
на две группы:
1-ая ![]() – слова, которые являются кодовыми;
2-ая
– слова, которые являются кодовыми;
2-ая
![]() – слова, которые не являются кодовыми,
т.е. все остальные.
– слова, которые не являются кодовыми,
т.е. все остальные.
Слова 2-ой группы являются либо началом кодовых слов второй расшифровки и концом кодовых слов первой расшифровки, либо началом кодовых слов первой расшифровки и концом кодовых слов второй расшифровки.
Слова 2-ой группы попарно различны. Если бы это было не так, т.е. существовали два одинаковых слова 2-ой группы, то вырежем участок между двумя одинаковыми словами 2-ой группы вместе с одним из этих слов и соединим полученные два слова. Тогда не трудно видеть, что полученное слово также допускает две дешифровки, что противоречит минимальности некорректного данного слова.
Посчитаем,
какое максимальное число слов во 2-ой
группе может быть. Во 2-ой группе есть
непустые начала кодовых слов, которые
отличны от самих кодовых слов. Первое
слово имеет длину ![]() и поэтому число рассмотренных начал
для него есть
и поэтому число рассмотренных начал
для него есть ![]() ,
для второго кодового слова число начал
равно
,
для второго кодового слова число начал
равно ![]() ,
и так для каждого, а для последнего –
,
и так для каждого, а для последнего –
![]() .
Суммируя данные величины, получаем, что
число слов во 2-ой группе не более чем
.
Суммируя данные величины, получаем, что
число слов во 2-ой группе не более чем
![]() .
.
Слова
второй группы разбивают исходное слово
на не более чем
![]() кусков.
кусков.
Теперь
разобьем слова 2-ой группы на пары
соседних и рассмотрим последовательность
слова ![]() .
Таких пар слов не больше, чем
.
Таких пар слов не больше, чем
![]() (в случае нечетного числа слов, последнее
непарное слово – дополнительное).
Число кодовых слов в каждом из полученных
(в случае нечетного числа слов, последнее
непарное слово – дополнительное).
Число кодовых слов в каждом из полученных![]() не более
не более![]() по обеим кодировкам. Согласно одному
разбиению в одной половине уложатся не
более одного кодового слова, а в другой
– не более
по обеим кодировкам. Согласно одному
разбиению в одной половине уложатся не
более одного кодового слова, а в другой
– не более![]() (согласно второму разбиению ситуация
симметрична).
(согласно второму разбиению ситуация
симметрична).
Поэтому
общее число кодовых слов, которое
содержится в начальном слове не более
чем
![]() .
Что и требовалось показать.
.
Что и требовалось показать.
Критерий префиксного кодирования (Мак-Миллана).
Определение.
Кодирование ![]() называют типа
называют типа ![]() ,
если существует
,
если существует ![]() штук кодовых слов единичной длины,
штук кодовых слов единичной длины, ![]() кодовых слов из двух букв,
кодовых слов из двух букв, ![]() слов из трех букв, …,
слов из трех букв, …, ![]() слов длины
слов длины ![]() .
.
Критерий.
Префиксное корректное кодирование типа
![]() существует тогда и только тогда,
когда
существует тогда и только тогда,
когда

![]() – мощность кодирующего алфавита.
– мощность кодирующего алфавита.
Доказательство.
Необходимость.
Пусть ![]() – корректное кодирование типа
– корректное кодирование типа ![]() .
Покажем справедливость формулы
.
Покажем справедливость формулы ![]() .
.
Перепишем
формулу ![]() в виде:
в виде:
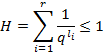
![]() – длины кодовых слов. Возведем сумму
– длины кодовых слов. Возведем сумму
![]() в степень
в степень ![]() :
:
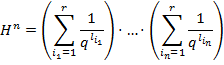 ,
т.е. возьмем
,
т.е. возьмем ![]() произведений таких сумм
произведений таких сумм
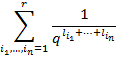 здесь
параметры
здесь
параметры
![]() независимо друг от друга пробегают
множество от
независимо друг от друга пробегают
множество от![]() до
до ![]() :
:
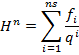 ,
где
,
где ![]() – число представлений числа
– число представлений числа ![]() в виде суммы
в виде суммы ![]() с помощью группировки слагаемых. Т.к.
кодирование корректно, то
с помощью группировки слагаемых. Т.к.
кодирование корректно, то ![]() .
.
Действительно,
![]() – это общее число слов в кодирующем
алфавите длины
– это общее число слов в кодирующем
алфавите длины
![]() ,
а каждое решение уравнения
,
а каждое решение уравнения![]() будет соответствовать некоторому
кодирующему слову, которых, в силу
корректности, не может быть больше чем
общее число слов длины
будет соответствовать некоторому
кодирующему слову, которых, в силу
корректности, не может быть больше чем
общее число слов длины ![]() :
:

![]()
Достаточность.
Пусть числа ![]() удовлетворяют соотношению
удовлетворяют соотношению ![]() .
Построим префиксное кодирование типа
.
Построим префиксное кодирование типа
![]() .
.
Перепишем
сумму ![]() по слагаемым:
по слагаемым:
![]()
Наша задача – построить кодовые слова такие, что никакое кодовое слово не начиналось на другое слово. Построим в начале кодовые слова единичной длины, а потом длины 2 и т.д.
Из
неравенства ![]() следует, что
следует, что ![]() ,
т.е.
,
т.е. ![]() .
В кодирующем алфавите есть
.
В кодирующем алфавите есть ![]() букв и мы должны выбрать
букв и мы должны выбрать
![]() различных кодовых слов единичной длины,
а из неравенства
различных кодовых слов единичной длины,
а из неравенства![]() следует, что это действительно можно
сделать.
следует, что это действительно можно
сделать.
Далее
построим кодовые слова длины 2. Тогда
выполняется неравенство ![]() ,
из которого следует, что
,
из которого следует, что ![]() ,
где
,
где ![]() – общее число слов длины 2 в кодовом
алфавите, а
– общее число слов длины 2 в кодовом
алфавите, а ![]() – число слов длины 2, которые начинаются
на кодовые слова единичной длины. Таким
образом, число допустимых слов длины 2
равно
– число слов длины 2, которые начинаются
на кодовые слова единичной длины. Таким
образом, число допустимых слов длины 2
равно ![]() .
Из полученного неравенства следует,
что мы действительно можем выбрать
кодовые слова длины 2, чтобы выполнялись
условия префиксности.
.
Из полученного неравенства следует,
что мы действительно можем выбрать
кодовые слова длины 2, чтобы выполнялись
условия префиксности.
Допустим,
что уже выбраны кодовые слова длины
меньшей ![]() ,
причем соблюдая условия префиксности.
Покажем, что можно выбрать кодовые слова
длины
,
причем соблюдая условия префиксности.
Покажем, что можно выбрать кодовые слова
длины ![]() .
.
Из
неравенства ![]() следует, что
следует, что
![]() ,
где
,
где ![]() – общее число слов длины
– общее число слов длины ![]() в кодирующем алфавите,
в кодирующем алфавите, ![]() – число слов длины
– число слов длины ![]() ,
которые начинаются на кодовые слова
длины
,
которые начинаются на кодовые слова
длины ![]() и т. д.,
и т. д.,
![]() число
слов длины
число
слов длины![]() ,
которые начинаются на кодовые слова
длины 1. Таким образом, мы построили
префиксное кодирование типа
,
которые начинаются на кодовые слова
длины 1. Таким образом, мы построили
префиксное кодирование типа![]() .
.
Теория кодирования имеет применение в задачах устойчивой пердачи информации.