

Введение
История семейства форматов MPEG, к которому собственно и принадлежит стремительно набирающий в последнее время популярность формат MPEG-4, началась в далеком 1988 году. Именно в этом году был основан комитет Moving Pictures Expert Group, что на русский переводится как экспертная группы кинематографии (движущихся изображений), аббревиатура которого - MPEG известна теперь любому, кто имел дело с мультимедиа - компьютерами или с цифровым телевидением. В этом же году была начата разработка формата MPEG-1, который в окончательном виде был выпущен в 1993 году. Несмотря на все очевидные недостатки этого формата, MPEG-1 по-прежнему является одним из наиболее массовых форматов видеосжатия, лишь в последнее время, начиная постепенно сдавать позиции под натиском более новых и совершенных форматов видеокомпрессии, по большей части из этого же семейства.
Надо сказать, что практически все новаторские по тем временам разработки легшие в основу формата MPEG-1, в том или ином виде встречаются и более совершенных форматах данного ряда, поэтому, рассмотрев в подробностях первого представителя этого семейства форматов видеосжатия можно получить общее представление о том, как же работают алгоритмы MPEG.
3
Классификация алгоритмов сжатия
Алгоритмы сжатия в первую очередь разделяют на потоковые и статические, то есть работающие с последовательностями кадров или с каждым из кадров отдельно.
Встатических алгоритмах сжатие достигается с помощью методов обработки изображений, при этом может обрабатываться либо все изображение целиком, либо разбиваться на отдельные блоки. Одними из самых распространенных на сегодняшний момент являются алгоритмы группы Wavelet и Jpeg.
Впотоковых алгоритмах учитывается тот факт, что, как правило, близкорасположенные кадры не сильно отличаются друг от друга и сжатие достигается также за счет кодирования лишь разницы между кадрами (избыточность во времени), а также за счет работы с отдельными объектами, присутствующими в нескольких кадрах, причем положение объекта в каждом из кадров - разное. Работа с отдельными объектами внутри кадра усложняет алгоритм, но и позволяет добиться значительного сжатия потокового видео.
Одними из самых распространенных в потоковых алгоритмах являются алгоритмы групп MPEG и MJPEG.
Кроме того, алгоритмы сжатия делят по признаку отличия декомпрессованного видеоизображения от оригинала на следующие:
Сжатие без потерь данных
Полученное после декомпрессии изображение будет в точности (побитно) совпадать с оригиналом. Примером такого сжатия может служить формат GIF для статической графики а для видео Alpary, ArithYuv, AVIzlib, CamStudio GZIP, CorePNG, FastCodec, FFV1, Huffyuv, Lagarith, LOCO, LZO, MSU Lab, PICVideo, Snow,x264,YULS.
Сжатие с потерями качества
Большинство алгоритмов работают так, что два оцифрованных изображения от оригинала и от сжатого и восстановленного с использованием того или иного декомпрессора файла - побитно не совпадают. Так, например, работают JPEG для сжатия статической графики и алгоритмы для сжатия видео H.261, H.263, H.264/MPEG-4 AVC, MNG, Motion JPEG,MPEG-1,MPEG-2, MPEG-4.
Сжатие без заметных потерь с точки зрения восприятия
Данные после декомпрессии побитно не совпадают с исходными, однако из-за особенностей восприятия (слабая восприимчивость к мелким деталям, более низкие требования к разрешению цветоразностного сигнала по сравнению с яркостным и т.п.), человек не способен или почти не способен отличить разницу на статическом и, тем более, на "живом" изображении. Для субъективной характеристики качества сжатого видео применяют так называемый фактор качества сжатия, характеризующий именно качество восприятия и варьирующийся в пределах от 0 до 100. При факторе качества сжатия, равном 100, характеристики восприятия качества декомпрессированного видео по восприятию почти неотличимы от оригинала.
Сжатие с естественной потерей качества
JPEG, MPEG и другие технологии сжатия с потерей качества иногда сжимают,
4
переступая за грань сжатия без потерь с точки зрения восприятия видеоинформации. Тем не менее сжатые видео- и статические изображения вполне приемлемы для адекватного восприятия их человеком.
Иными словами, в данном случае наблюдается так называемая естественная деградация изображения, при которой теряются некоторые мелкие детали сцены. Похожее может происходить и в естественных условиях, например при дожде или тумане. Изображение в таких условиях, как правило, различимо, однако уменьшается его детализация.
Сжатие с неестественными потерями качества
Низкое качество сжатия, в значительной степени искажающее изображение и вносящее в него искусственные (не существующие в оригинале) детали сцены, называется неестественным сжатием с потерей качества. Примером тому может служить некоторая "блочность" в сильно сжатом MJPEG и в других компрессорах, использующих технологию блочного дискретно-косинусного преобразования.
Неестественность заключается в первую очередь в нарушении самых важных с точки зрения восприятия человеком характеристик изображения - контуров. Опыт показывает, что именно контуры позволяют человеку правильно идентифицировать тот или иной визуальный объект.
Отметим также, что все широко используемые видеокомпрессоры применяют технологии сжатия с потерями качества. При различных значениях качества сжатия - на выходе может быть как видео без потерь с точки зрения восприятия, так и с неестественными потерями.
Сжатие Wavelet
В данном типе сжатия изображение представляется как дискретизованная функция яркостного и цветоразностного сигнала от координаты, далее эта функция раскладывается по специфическим функциям, получившим название wavelet. При этом часть коэффициентов разложения отбрасывается, а остальные кодируются (В основном отбрасывается по следующему принципу: мы сохраняем в файл разницу - число между средними значениями соседних блоков в изображении, которая обычно принимает значения, близкие к 0.) Количество учитываемых и отбрасываемых коэффициентов и определяет качество сжатой картинки.
Для работы с видео в реальном времени иногда также используют разновидность данного метода - delta-wavelet.
Отказоустойчивость алгоритма, возможность хорошего сжатия, при относительно высоком качестве изображения позволили использовать данный алгоритм во многих задачах.
Сжатие JPEG
Основная идея данного алгоритма сжатия разбить изображение на блоки 8*8 пикселей и применить к каждому из блоков отдельно дискретное косинусное преобразование, коэффициенты разложения функции контрастного и цветоразностного сигнала далее кодируются по Хаффману. Основной недостаток данного алгоритма заметная блочность изображения при высоких коэффициентах сжатия. Степень сжатия данного алгоритма при равном визуальном качестве изображения в 1,5 2 раза хуже, чем у wavelet. При работе с видео в реальном времени используется разновидность этого алгоритма MJpeg.
Motion JPEG или M-JPEG (MJPG)
Большинство настольных систем видеозаписи (video capture) и видеоредактирования (video editing) используют именно этот метод при записи видео в AVI-файлы. В Motion
5
JPEG каждый видеокадр изображения сжимается отдельно с использованием стандарта JPEG. Никаких других дополнительных алгоритмов при этом не используется. Безусловным достоинством этого метода является возможность редактирования видео без потерь качества, так как кадры являются независимыми. Этим, по сути дела, и определяется использование данного метода именно как механизма хранения видео, служащего для его редактирования, а не для распространения. Motion JPEG использует алгоритм блокового ДКП (Block Discrete Cosine Transform (DCT) для сжатия изображений.
MPEG-4
Данный алгоритм создавался так, чтобы сжатое с его помощью видео имело минимальную ширину полосы оцифровки, при этом визуальное качество картинки не должно было ухудшаться по сравнению с MPEG-2. Алгоритм был призван, в том числе, решать задачи трансляции видео по локальным и глобальным вычислительным сетям, в различных условиях пропускной способности сетей передачи данных.
Данный алгоритм получил широкое распространение также благодаря тому, что с его помощью фильм DVDкачества, умещавшийся ранее на 1,3 Гбайт (два cd-диска), можно было записать без визуального ухудшения на 700 Мбайт (один cd-диск.). Ширина полосы оцифровки данного алгоритма в два раза меньше, чем у ближайшего конкурента MPEG-2! В основу функций видеосоставляющей стандарта MPEG-4 была положена технология применения целого арсенала алгоритмов сжатия, применяемых как в зависимости от исходного качества и природы сжимаемого видеофрагмента, так и в совокупности и (или) последовательно обрабатывающих исходное видео с помощью различных по природе алгоритмов сжатия. Это методы прогрессивного и словарного кодирования, кодирования с использованием чересстрочного сканирования, технологии RLE (Run Length Encoding), технологии векторной квантизации (Vector Quantization), а также всевозможные преобразования (Фурье, Дискретное Косинусное, Wavelet).
Первоначальное кодирование видео в MPEG-4 осуществляется аналогично MPEG-1 и MPEG-2. В этом смысле основа кодирования у группы алгоритмов MPEG общая, однако MPEG-4, кроме рассмотренного традиционного MPEG-кодирования, основанного на прямоугольных кадрах, использует технологию контурно-основанного кодирования изображений. Контур - это линия, очерчивающая границу фигуры на плоскости. Текстура представление структуры поверхности изображения. Контурно-основанное кодирование изображений представляет изображения как контуры, огибающие текстурные области (области, заполненные текстурами). А так как контуры, как правило, совпадают с границами изображаемых объектов сцены, то задача контурно-основанного кодирования сводится к задаче объектно-основанного кодирования изображений, а именно: изображение представляется набором составляющих его объектов. MPEG-4 обеспечивает возможность индивидуально кодировать специфические элементы в рамках видеосюжета. Поскольку разные объекты, используемые в видеосюжете, как правило, имеют различную природу (текстурный фон, персонажи переднего плана, мелкие детали сцены), то совокупность различных по природе способов сжатия, используемых для разных типов данных, в зависимости от их природы, позволяет добиться наиболее высокой степени сжатия
6
MPEG-1
Формат MPEG-1 начал разрабатываться в те трудно вообразимые времена, когда не было широкодоступных носителей большого объема, в то время, как видеоданные, даже и сжатые, занимали совершенно колоссальные для конца 80-х объемы - средней продолжительности фильм имел размер больше гигабайта. Если кто не помнит, то это была эпоха 286 и 386 процессоров, 4 Мб оперативной памяти и 250 Мб винчестер считались роскошью, а не убогостью, как сейчас, Windows была примочкой для DOS, а не наоборот, а в качестве легко переносимых носителей информации доминировали 5 дюймовые дискеты и только-только появившиеся 3,5" дискеты от фирмы SONY. В таких условиях необходимо было найти носитель, на который можно было бы записать гигабайт информации, при этом этот носитель должен был быть недорогим, иначе ни о какой массовости не могло быть и речи.
И такой носитель был найден. Как раз в эти годы впервые на платформе PC появился такой новый тип носителей информации как CD-ROM диски, которые смогли обеспечить необходимый объем информации. Правда, на один диск фильм в формате MPEG-1 всетаки не вмещался, но что мешало записать его на 2 CD, тем более, что новинка стоила очень недорого? Разумеется, первые CD-ROM проигрыватели были односкоростными, поэтому не стоит удивляться, что максимальная скорость пересылки потока данных (bitstream) в формате MPEG-1 ограничена 150 Кб/сек., что соответствует одной скорости
CD-ROM.
Надо сказать, что возможности MPEG-1 не ограничены тем низким разрешением, которое мы все видели при просмотре VIDEO-CD. В самом формате была заложена возможность сжатия и воспроизведения видеоинформации с разрешением вплоть до 4095х4095 и частотой смены кадров до 60 Гц. Но из-за того, что поток передачи данных был ограничен 150 Кб/сек., то есть так называемый Constrained Parameters Bitstream (CPB)
- зафиксированная ширина потока передачи данных, разработчики формата, а в дальнейшем и создатели кодеков на его основе, были вынуждены использовать разрешения кадра, оптимизированные под данный CPB. Наиболее широко распространенными являются два таких оптимизированных формата - это формат SIF 352х240, 30 кадров в секунду и урезанный формат PAL/SECAM 352х288, 25 кадров в секунду.
Теперь можно рассмотреть принципы сжатия информации в MPEG-1.В качестве примера рассмотрим урезанный формат PAL/SECAM, который более распространен, чем SIF, хотя оба эти формата за исключением разрешения и частоты смены кадров ничем друг от друга не отличаются.
Урезанная версия формата PAL/SECAM содержит 352 ppl (point per line - точек на линию), 288 lpf (line per frame - линий на кадр) и 25 fps (frame per second - кадров в секунду). Надо сказать, что полноценный стандарт PAL/SECAM имеет параметры в 4 раза большие, чем аналогичные у MPEG-1 (кроме fps). Поэтому принято говорить, что VIDEOCD имеет четкость в четыре раза хуже, по сравнению с обычным видео.
Что касается глубины цвета, то тут не все так просто, как в компьютерной графике, где на каждый пиксел отводится определенное фиксированное число бит. Любой цвет может быть получен из комбинации красного зеленого и синего цветов (RGB,RED, GREEN, BLUE), смешанных в определенной пропорции (на самом деле для человеческого глаза достаточно и двух цветов). Поэтому, именно эти три цвета используются для формирования изображения в телевидении. По нескольким причинам напрямую схема RGB не используется для кодирования в телевидении (и наоборот используется в компьютерной технике). Одна из этих причин – совместимость с черно-белыми телевизорами. Сам телевизионный сигнал является составным (композитным) – то есть представляет собой смесь нескольких сигналов. В него входит 3 составляющих:
Y (luma) – сигнал яркости
7
U – 1 цветоразностный сигнал
V – 2 цветоразностный сигнал
Y – определяет яркость точки, которая может изменяться в диапазоне от чёрной до белой. Таким образом, сигнал яркости полностью формирует чёрно-белое изображение (наследие 50-х годов). Сигнал яркости Y в сочетании с цветоразрастными сигналами U и V формирует цветное изображение.
Сигнал яркости Y формируется из RGB сигнала по следующей формуле:
Y = 0.299R + 0.587G + 0.114B
U сигнал формируются по формуле:
U = R - Y
V сигнал формируются по формуле:
V = B - Y
Для получения RGB представления изображения из YUV воспользуемся следующими формулами:
R = Y + U
B = Y + V
G = Y - 0.509U - 0.194V
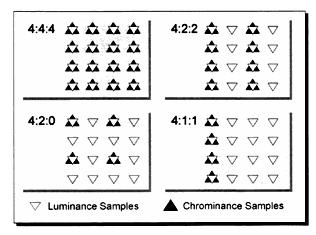
Человеческий глаз менее чувствителен к изменению цвета, чем к изменению яркости. Поэтому разработчики телевизионных стандартов решили сэкономить на полосе пропускания и цветоразностные сигналы передаются в меньшем разрешении, чем сам сигнал яркости. Как обычно – имеем несколько вариантов экономии на цветоразностных сигналов, которые обозначаются тремя цифрами, разделенными двоеточием – 4:2:2, 4:1:1 и т.п. Как расшифровать данные цифры? Обратимся к нижеприведенной иллюстрации:
Светлыми треугольниками на рисунке обозначены точки, в которых происходит изменение яркости изображения, а чёрными треугольниками на рисунке обозначены точки, в которых происходит изменение цветности. Как видно из схемы, существуют варианты представления видеоизображения 4:4:4, 4:2:2, 4:2:0 и 4:1:1. Давайте разберемся, что обозначают эти цифры. Первая цифра относится к яркостному сигналу,а каждая следующая цифра отвечает за две строчки, 1 и 3, или 2 и 4. (нечетные и четные строки). Значение этой цифры определяет, сколько точек в каждой из линии меняют своё значение. Чаще всего используется схема 4:2:2, поскольку при ее использовании почти незаметно различие между картинкой, закодированной в схеме 4:4:4. В основу MPEG-1положено использование цветовой схемы YСbCr – 4:2:2.
Перед началом кодирования происходит анализ видеоинформации, выбираются ключевые кадры, которые не будут изменяться при сжатии, а так же кадры, при кодировании которых часть информации будет удаляться. Всего выделяется три типа кадров:
Кадры типа I - Intra frame. Ключевые кадры, которые сжимаются без изменений.
8

Кадры типа P - Predirected frame. При кодировании этих кадров часть информации удаляется. При воспроизведении P кадра используется информация от предыдущих I или P кадров.
Кадры типа В - Bidirectional frame. При кодировании этих кадров потери информации еще более значительны. При воспроизведении В кадра используется информация уже от двух предыдущих I или P кадров (один предшествующий данному и один следующий за ним, хотя может и не непосредственно). Наличие В кадров в видеоролике - тот самый фактор, благодаря которому MPEG-1 имеет высокий коэффициент сжатия (но и не очень высокое качество).
При кодировании формируется цепочка кадров разных типов. Наиболее типичная последовательность может выглядеть следующим образом: IBBPBBPBBIBBPBBPBB...
Соответственно очередь воспроизведения по номерам кадров будет выглядеть так: 1423765... Нужно заметить, что прежде чем декодировать B кадр требуется декодировать два I или P кадра. Существуют разные стандарты на частоту, с которой должны следовать I кадры, приблизительно 1-2 в секунду, соответствуюшие стандарты есть и для P кадров (каждый 3 кадр должен быть P кадром).
По окончании разбивки кадров на разные типы начинается процесс подготовки к кодированию.
С I кадрами процесс подготовки к кодированию происходит достаточно просто - кадр разбивается на блоки. В MPEG-1 блоки имеют размер 8х8 пикселов. А вот для кадров типа P и B подготовка происходит гораздо сложнее. Для того, чтобы сильнее сжать кадры указанных типов используется алгоритм предсказания движения.
В качестве входной информации алгоритм предсказания движения получает блок 8х8 пикселов текущего кадра и аналогичные блоки от предыдущих кадров (I или P типа). На выходе данного алгоритма имеем следующую информацию о вышеуказанном блоке:
Вектор движения текущего блока относительно предыдущих Разницу между текущим и предыдущими блоками, которая собственно и будет подвергаться дальнейшему кодированию.
Вся избыточная информация подлежит удалению, благодаря чему и достигается столь высокий коэффициент сжатия, невозможный при сжатии без потерь.
Но у алгоритма предсказания движения есть ограничения. Зачастую в фильмах бывают статические сцены, в которых движения нет или оно незначительно и возникают блоки
9
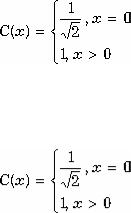
или целые кадры, в которых невозможно использовать алгоритм предсказания движения. Думаю, вы замечали, что у видеороликов сжатых MPEG-1 качество сцен с небольшим количеством двигающихся объектов заметно выше, чем в сценах с интенсивным движением. Это объясняется тем, что в статических сценах P и B кадры, по сути, представляют собой копии I кадров, потерь практически нет, но и сжатие информации незначительно.
В случае же корректного срабатывания алгоритма предсказания движения, объемы кадров разного типа в байтах соотносятся друг с другом примерно следующим образом - I:P:B как 15:5:2. Как вы видите из данного соотношения, уменьшение объема видеоинформации налицо уже на стадии подготовки к кодированию.
По окончании этой стадии начинается собственно само кодирование. Процесс кодирования содержит в себе 3 стадии:
Discrete Cosine Transformation - DTC, дискретное преобразование косинусов, преобразование Фурье.
Quantization - квантование. Перевод данных из непрерывной формы в прерывистую, дискретную.
Преобразование полученных блоков данных в последовательность, то есть преобразование из матричной формы в линейную.
При кодировании блоки пикселов или вычисленная разница между блоками обрабатывается первым из преобразующих алгоритмов - DTC (дискретное преобразование косинусов). Дискретное косинусное преобразование представляет собой разновидность преобразования Фурье и, так же как и оно, имеет обратное преобразование. Графическое изображение можно рассматривать как совокупность пространственных волн, причем оси X и Y совпадают с шириной и высотой картинки, а по оси Z откладывается значение цвета соответствующего пикселя изображения. Дискретное косинусное преобразование позволяет переходить от пространственного представления картинки к ее спектральному представлению и обратно. Воздействуя на спектральное представление картинки, состоящее из “гармоник”, то есть, отбрасывая наименее значимые из них, можно балансировать между качеством воспроизведения и степенью сжатия.
Формулы прямого и обратного дискретного косинусного преобразования представлены ниже. Дискретное косинусное преобразование преобразует матрицу пикселов размером NxN в матрицу частотных коэффициентов соответствующего размера. Несмотря на видимую сложность, закодировать эти формулы достаточно просто.
ДКП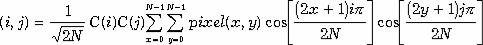
Формула дискретного косинусного преобразования.
ДКП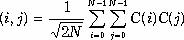 ДКП
ДКП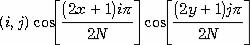
Формула обратного дискретного косинусного преобразования.
10
В получившейся матрице коэффициентов низкочастотные компоненты расположены ближе к левому верхнему углу, а высокочастотные - справа и внизу. Это важно потому, что большинство графических образов на экране компьютера состоит из низкочастотной информации. Высокочастотные компоненты не так важны для передачи изображения.
Таким образом, дискретное косинусное преобразование позволяет определить, какую часть информации можно безболезненно выбросить, не внося серьезных искажений в картинку.
Время, необходимое для вычисления каждого элемента матрицы дискретного косинусного преобразования, сильно зависит от ее размера. Так как используются два вложенных цикла, время вычислений составляет О (NxN). Одной из особенностей является то, что практически невозможно выполнить дискретное косинусное преобразование для всего изображения сразу. В качестве решения этой проблемы группа разработчиков MPEG предложила разбивать изображение на блоки размером 8x8 точек. Увеличивая размеры блока дискретного косинусного преобразования, можно добиться некоторого увеличения результатов сжатия. Ограничения в коэффициенте сжатия объясняются малой вероятностью того, что удаленные на значительное расстояние точки изображения имеют одинаковые атрибуты. Обычно пиксела в блоке и сами блоки изображения каким-то образом связаны между собой - например однотонный фон, равномерный градиент освещения, повторяющийся узор и т.д. Такая связь называется корреляцией. Алгоритм DTC, используя коррелирующие эффекты, производит преобразование блоков в частотные фурье-компоненты. При этом часть информации теряется за счет выравнивания сильно выделяющихся участков, которые не подчиняются корреляции. После этой процедуры в действие вступает алгоритм Quantization -
квантование, который формирует Quantization matrix. Quantization matrix - это матрица квантования, элементами которой являются преобразованные из непрерывной в дискретную форму данные, то есть числа, которые представляют собой значения амплитуды частотных фурье-компонентов. После формирования quantization matrix происходит разбивка частотных коэффициентов на конкретное число значений. Точность частотных коэффициентов фиксирована и составляет 8 бит. После квантования многие коэффициенты в матрице обнуляются. И в качестве завершающей стадии происходит преобразование матрицы в линейную форму.
Все эти преобразования касаются только изображения. Но кроме изображения в практически любом видеофрагменте присутствует так же и звук. Кодирование звука осуществляется отдельным звуковым кодером. По мере развития формата MPEG, звуковые кодеры неоднократно переделывались, становясь все эффективнее. К моменту окончательной стандартизации формата MPEG-1 было создано три звуковых кодера этого семейства - MPEG-1 Layer I, Layer II и Layer 3 (тот самый знаменитый MP3). Принципы кодирования всех этих кодеков основаны на психоакустической модели, которая становилась все более и более совершенной и достигла своего апофеоза для семейства MPEG-1 в алгоритмах Layer-3.
Синхронизация аудио- и видеоданных осуществляется с помощью специально выделенного потока данных под названием System stream. Этот поток содержит встроенный таймер, который работает со скоростью 90 КГц и содержит 2 слоя - системный слой с таймером и служебной информацией для синхронизации кадров с аудиотреком и компрессионный слой с видео- и аудиопотоками.
11
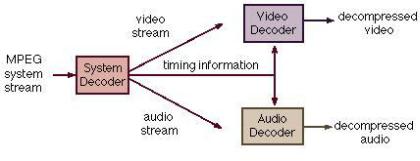
Под служебной информацией понимаются несколько видов меток, наиболее важными из которых являются метки SCR (System Clock Reference) - инкремент увеличения временного счетчика кодека и PDS (Presentation Data Stamp) - метка начала воспроизведения видеокадра или аудиофрейма.
Качество аудиотреков в MPEG-1 может варьироваться в очень больших пределах - от высококачественных до безобразных. Окончательно все форматы сжатия аудиоданных были стандартизированы в 1992 году европейской комиссией по стандартам ISO.
В зависимости от используемого кодера и степени сжатия аудиоинформация видеоролика может быть представлена в следующем виде: моно, dual mono, стерео, интенсивное стерео (стереосигналы, чьи частоты превышают 2 КГц объединяются в моно), m/s стерео (один канал - сумма сигналов, другой - разница) и по частоте дискретизации могут быть: 48, 44.1и 32 КГц.
12