

It_Kompyuterny_Praktikum
.Pdf
|
|
Любое |
|
разбиение |
множества X (xT , xT ,...xT )T |
на |
нечеткие |
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
2 |
|
n |
|
|
|
|
|
подмножества Si |
( i 1.c ) |
может |
быть полностью |
|
|
описано |
функцией |
|||||||||||||||
принадлежности S |
i |
|
: X [0,1]. |
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Обозначим |
|
через |
ik – |
степень |
принадлежности |
объекта |
||||||||||||||
x |
k |
(x |
, x |
|
,..., x |
|
|
)T , к подмножеству Si, т.е. |
ik |
|
S |
|
(x |
k |
) , а через V |
– |
||||||
|
k |
k |
2 |
k |
p |
|
|
|
|
|
|
|
i |
|
|
cn |
||||||
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
множество всех действительных матриц размером c n. Тогда нечетким с- разбиением (или матрицей степеней принадлежности) называется матрица M [ ik ] Vcn при выполнении следующих условий:
|
|
|
|
|
|
|
|
|
|
ik [0,1], i 1.c, k 1.n ; |
(4.1) |
||||||||
c |
|
|
|
|
|
||||
ik 1, k 1.n; |
(4.2) |
||||||||
i 1 |
|
||||||||
n |
|
|
|
||||||
ik (0, n), i 1.c. |
(4.3) |
||||||||
k 1 |
|
||||||||
В отличие от четкого, при нечетком c-разбиении любой объект одновременно принадлежит к различным кластерам, но с разной степенью. Условия (4.2) и (4.3) требует только, чтобы сумма степеней принадлежности объекта ко всем кластерам была нормализована к 1, а также чтобы количество кластеров, к которым принадлежит объект не превышало c.
Обозначим центры кластеров, т.е. точки в р-мерном пространстве, вокруг которых сконцентрированы соответствующие объекты, через
vi (vi1, vi2 ,..., vip ) , i 1.c
При использовании евклидового расстояния задача нечеткой кластеризации состоит в нахождении такой матрицы степеней принадлежности M и таких координат центров кластеров V (v1 , v 2 ,..., vc ) ,
которые обеспечивают минимум следующего критерия:
|
|
c |
n |
|
2 min , |
||||||||
|
( ik )m |
|
|
|
xk vi |
|
|
|
|||||
|
|
|
|
||||||||||
|
i 1k 1 |
|
|
|
|
||||||||
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
( ik )m xk |
|
|
|
|
|
|
|
|
|
|
|
|
где vi |
k 1 |
|
|
|
|
||||||||
|
– центр i-го кластера, i 1.c , m – так называемый |
||||||||||||
n |
|||||||||||||
|
ik |
|
|
|
|
|
|
|
|
|
|
|
|
k 1
экспоненциальный вес ( m 1). В математике под обозначением 


 обычно
обычно
понимают норму, т.е. функцию, заданную на векторном пространстве и обобщающая понятие длины вектора.
61
Значение экспоненциального веса устанавливается до начала кластеризации. Экспоненциальный вес m влияет на матрицу степеней принадлежности M. Чем больше m, тем конечная матрица c-разбиения становится более «размазанной», а при m все объекты принадлежат всем кластерам с одинаковой степенью принадлежности, что является очень плохим решением. Экспоненциальный вес позволяет также при формировании координат центров кластеров усилить влияние объектов с большими значениями степеней принадлежности и уменьшить влияние объектов с малыми значениями степеней принадлежности. На настоящий момент не существует теоретически обоснованного правила выбора значения m. Обычно устанавливают m=2.
Аналитического решения задачи нахождения оптимальных координат центров кластеров и матрицы степеней принадлежности не существует, поэтому она решается численно. В среде MATLAB алгоритм нечетких центров реализован в функции fcm.
Функция fcm может иметь три входных аргумента:
1)Х – матрица, представляющая данные, подлежащие кластеризации. Каждая строка матрицы соответствует одному объекту (образу);
2)с – количество кластеров, которое должно быть получено в результате выполнения функции fcm. Количество кластеров должно быть больше 1 и меньше числа образов, заданных матрицей Х.
3)options – необязательный аргумент, устанавливающий параметры
алгоритма кластеризации:
options(1) – значение экспоненциального веса (по умолчанию – 2.0);
options(2) – максимальное количество итераций алгоритма кластеризации (значение по умолчанию - 100);
options(3) – минимально допустимое значение улучшения целевой функции за одну итерацию алгоритма (значение по умолчанию –
0.000001);
options(4) – вывод промежуточных результатов во время работы
функции fcm (значение по умолчанию – 1).
Для использования значений по умолчанию можно ввести NaN в качестве значения соответствующей координаты вектора options.
Алгоритм кластеризации останавливается, когда выполнено максимальное количество итераций или когда улучшение целевой функции за одну итерацию меньше указанного минимально допустимого значения.
Функция fcm имеет три выходных аргумента:
1)V – матрица координат центров кластеров, полученных в результате кластеризации. Каждая строка матрицы соответствует центру одного кластера;
2)M – матрица степеней принадлежности образов к кластерам. Каждая строка матрицы соответствует функции принадлежности одного кластера;
62
3)obj_fcn – вектор значений целевой функции на каждой итерации алгоритма кластеризации.
Модуль графического интерфейса Findcluster:
GUI-модуль (Модуль графического интерфейса) Findcluster позволяет автоматически находить центры кластеров многомерных данных с помощью нечеткого c-means алгоритма и алгоритма вычитающей кластеризации (subtractive clustering). Загрузка модуля Findcluster осуществляется по команде findcluster. Основное графическое окно модуля Findcluster с указанием назначения функциональных областей приведено на рис. 4.24.
Модуль Findcluster содержит 7 верхних типовых меню графического окна (File (Файл), Edit (Редактирование), View (Обзор), Insert (Вставка),
Tools (Инструменты), Windows (Окна) и Help (Помощь)), область визуализации, область загрузки данных, область кластеризации, область вывода текущей информации а также кнопки Info (Информация) и Close (Закрыть), которые позволяют вызвать окно справки и закрыть модуль, соответственно.
Область визуализации
В этой области в двумерном пространстве выводятся экспериментальные данные (образы) и найденные центры кластеров. Для образов используется маркер в виде красной окружности (o), а для центров кластеров – маркер в виде черной точки (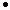 ).
).
Вобласти также расположены меню выбора координатных осей X-axis
иY-axis, позволяющие ассоциировать признаки образов с осями абсцисс и ординат.
Область загрузки данных
В этой области, которая расположена в правом верхнем углу окна, находится кнопка Load Data (Загрузка данных). Нажатие этой кнопки позволяет загрузить данные для кластеризации, хранящиеся на диске. После нажатия кнопки Load Data… открывается типовое окно открытия файла. В файле данные должны быть записаны построчно, т. е. каждому образу должна соответствовать одна строка файла данных.
Область вывода текущей информации
В этой области, которая расположена внизу графического окна, выводится наиболее важная текущая информация, например, состояние модуля, номер итерации алгоритма кластеризации, значение целевой функции и т.п.
Область кластеризации
В этой области пользователь может выбрать алгоритм кластеризации, установить параметры алгоритма кластеризации, провести кластеризацию и сохранить координаты центров кластеров в виде файла. В области расположены следующие меню и кнопки.
63
Меню Method (Метод) позволяет выбрать один из двух алгоритмов кластеризации: subtractiv – алгоритм вычитающей кластеризации; fcm - нечеткий c-means алгоритм. При выборе алгоритма вычитающей кластеризации графическое окно модуля Findcluster имеет вид, показанный на рис. 4.24. В этом случае пользователь имеет возможность установить значения следующих параметров алгоритма Influence Range (Диапозон влияния), Squash (Давка), Accept Ratio (Принимаемый коэффициент) и Reject Ratio (Отклоненный коэффициент), смысл которых объяснен в описании функции subclust. При выборе нечеткого c-means алгоритма область кластеризации принимает вид, изображенный на рис. 4.25. В этом случае пользователь имеет возможность установить значения следующих параметров: Cluster Num. – количество кластеров; Max Iteration # - максимальное количество итераций алгоритма; Min – минимально допустимое значение улучшения целевой функции за одну итерацию алгоритма; Exponent – значения экспоненциального веса.
Рис. 2.24. Основное окно модуля Findcluster
64

Рис. 2.26. Окно выполнения алгоритма
вычитающей кластеризации
Рис. 2.25. Область
кластеризации
Кнопка Start – запускает кластеризацию. При использовании алгоритма fcm значения координат центров кластеров выводятся в окне визуализации после каждой итерации. При использовании вычитающего алгоритма открывается дополнительное окно (рис. 2.26), показывающее динамику процесс кластеризации. Координаты центров кластеров выводятся по окончанию выполнения алгоритма.
Кнопка Clear Plot позволяет очистить поле вывода данных.
Для выявления центров кластеров (точек в многомерном пространстве данных) откроем файл clusterdemo.dat для просмотра его структуры (рис. 2.27). Файл представляет собой массив цифр (экспериментальных данных), сгруппированных в три столбца (многомерный массив).
Рис. 2.27. Файл clusterdemo.dat
Пример выполнения:
1)загрузим файл данных MATLAB\toolbox\fuzzy\fuzdemos\ clusterdemo.dat с помощью кнопки «Load Data»;
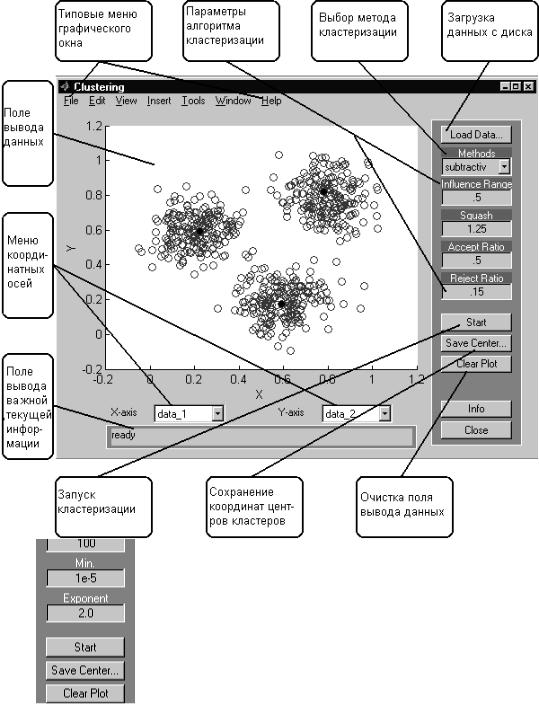
2)выберем алгоритм кластеризации Fuzzy c-means (fcm), с помощью кнопки «Method»;
3)зададим число кластеров равное 3, с помощью кнопки опции
«Cluster num»;
65
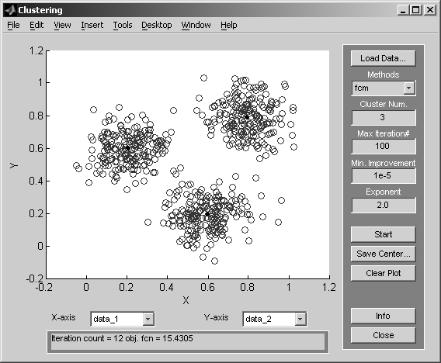
4)зададим число итераций равное 100, с помощью кнопки опции
«Max Iteration#»;
5)нажимаем кнопку Start и получаем результат (рис. 2.28).
Рис. 2.28. Результат работы программы Clustering (центры кластеров окрашены в черный цвет).
При увеличении количества кластеров до 30 получим результат, представленный на рис. 2.29.
66
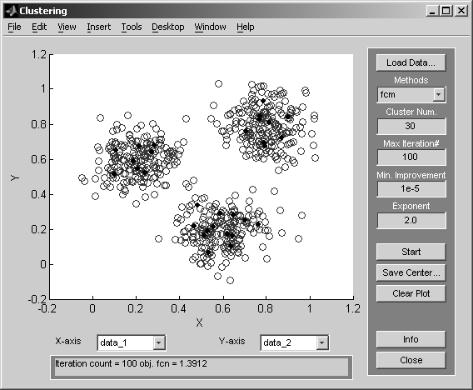
Рис. 2.29. Результат работы программы Clustering
(центры кластеров окрашены в черный цвет).
Выводы (пример):
В результате выполнения лабораторной работы мы ознакомились с графической средой программы кластеризации – Clustering, пакета Fuzzy Logic Toolbox, которая выявляет центры кластеров. Мы убедились, что с помощью этой программы можно быстро найти центры кластеров.
С использованием демонстрационного примера было произведено сравнение работы двух алгоритмов нахождения центров кластеров (алгоритм вычитающей кластеризации и алгоритм нечетких центров). В результате сравнения было выявлено, что алгоритм вычитающей кластеризации менее точен и подойдет, если не нужна высокая точность кластеризации данных, а алгоритм нечетких центров более точен, его нужно применять, если требуется высокая точность результата. Таким образом, точность решения зависит от выбора алгоритма кластеризации и от формы представления входных данных.
Контрольные вопросы:
1.Какая программа использовалась для выявления центров кластеров?
2.Дайте определение кластеризации.
3.Для каких задач может быть использована кластеризация?
4.Как может быть определено расстояние между кластерами?
5.Назовите этапы алгоритма кластерного анализа.
67

6. Каким образом определяются центры кластеров?
3. Компьютерный практикум по нейронным сетям
3.1. Аппроксимация функции на основе нейронных сетей
Цель работы: научиться использовать нейронные сети для аппроксимации функции.
Задание: В среде MATLAB необходимо построить и обучить нейронную сеть для аппроксимации таблично заданной функции yi f (xi ) , i 1.20 .
Разработать программу, которая реализует нейросетевой алгоритм аппроксимации и выводит результаты аппроксимации в виде графиков. Варианты задания представлены в табл. 3.1.
Варианты заданий
Значения xi i 0.1, i 1,20 – одинаковые для всех вариантов.
Таблица 3.1
i |
|
|
|
Значение |
yi yi (xi ) |
|
|
|
|||
№1 |
№2 |
№3 |
№4 |
№5 |
|
№6 |
№7 |
№8 |
№9 |
№10 |
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
1 |
2.05 |
2.09 |
2.02 |
1.99 |
2.23 |
|
2.07 |
2.18 |
-0.10 |
-0.16 |
2.09 |
2 |
1.94 |
2.05 |
1.98 |
2.03 |
2.29 |
|
2.17 |
2.43 |
-0.21 |
0.01 |
2.31 |
3 |
1.92 |
2.19 |
1.67 |
2.20 |
2.27 |
|
2.21 |
2.40 |
0.01 |
0.10 |
2.72 |
4 |
1.87 |
2.18 |
1.65 |
2.39 |
2.62 |
|
2.31 |
2.43 |
0.05 |
0.16 |
2.77 |
5 |
1.77 |
2.17 |
1.57 |
2.19 |
2.72 |
|
2.10 |
2.65 |
-0.13 |
0.05 |
2.78 |
6 |
1.88 |
2.27 |
1.42 |
2.61 |
2.82 |
|
2.09 |
2.75 |
-0.23 |
0.35 |
2.97 |
7 |
1.71 |
2.58 |
1.37 |
2.35 |
3.13 |
|
2.12 |
2.67 |
-0.21 |
0.19 |
3.00 |
8 |
1.60 |
2.73 |
1.07 |
2.60 |
3.49 |
|
1.63 |
2.66 |
-0.43 |
0.50 |
3.51 |
9 |
1.56 |
2.82 |
0.85 |
2.55 |
3.82 |
|
1.78 |
2.63 |
-0.57 |
0.74 |
3.43 |
10 |
1.40 |
3.04 |
0.48 |
2.49 |
3.95 |
|
1.52 |
2.75 |
-0.44 |
1.03 |
3.58 |
11 |
1.50 |
3.03 |
0.35 |
2.50 |
4.22 |
|
1.16 |
2.41 |
-0.44 |
1.06 |
3.58 |
12 |
1.26 |
3.45 |
-0.30 |
2.52 |
4.48 |
|
1.07 |
2.24 |
-0.83 |
1.49 |
3.54 |
13 |
0.99 |
3.62 |
-0.61 |
2.44 |
5.06 |
|
0.85 |
2.12 |
-0.78 |
1.79 |
3.82 |
14 |
0.97 |
3.85 |
-1.20 |
2.35 |
5.50 |
|
0.56 |
1.74 |
-0.81 |
2.03 |
3.90 |
15 |
0.91 |
4.19 |
-1.39 |
2.26 |
5.68 |
|
0.10 |
1.57 |
-1.06 |
2.22 |
3.77 |
16 |
0.71 |
4.45 |
-1.76 |
2.19 |
6.19 |
|
-0.25 |
1.17 |
-1.41 |
2.50 |
3.81 |
17 |
0.43 |
4.89 |
-2.28 |
2.24 |
6.42 |
|
-0.65 |
0.96 |
-1.40 |
2.88 |
4.00 |
18 |
0.54 |
5.06 |
-2.81 |
2.34 |
7.04 |
|
-1.06 |
0.63 |
-1.70 |
3.21 |
3.97 |
19 |
0.19 |
5.63 |
-3.57 |
1.96 |
7.57 |
|
-1.66 |
0.25 |
-1.96 |
3.63 |
4.08 |
|
|
|
|
|
|
|
|
|
|
|
68 |

20 |
0.01 |
5.91 -4.06 2.19 |
8.10 -2.01 -0.01 -1.91 3.90 |
4.08 |
Пример выполнения:
Задача. В среде MATLAB необходимо построить и обучить нейронную сеть для аппроксимации таблично заданной функции yi f (xi ) =[2.07 2.17 2.21 2.31 2.10 2.09 2.12 1.63 1.78 1.52 1.16 1.07 0.85 0.56 0.10 -0.25 -0.65 -1.06
-1.66 -2.01]T, i 1.20 .
В математической среде MATLAB создаем новый M-File, в котором записываем код программы создания и обучения нейронной сети с использованием встроенных функций пакета нейронных сетей Neural Networks Toolbox:
P = zeros(1,20); |
% создание массива |
|
for i = 1:20 |
|
|
P(i) = i*0.1; |
% входные данные (аргумент) |
|
end |
|
|
T=[2.07 2.17 2.21 2.31 2.10 2.09 2.12 1.63 1.78 1.52 |
1.16 1.07 0.85 0.56 |
|
0.10 -0.25 -0.65 -1.06 -1.66 -2.01] |
% входные данные (значение функции) |
|
net = newff([0.1 2],[5 1],{'tansig' 'purelin'}); % создание нейронной сети
net.trainParam.epochs = 100; |
% задание числа эпох обучения |
net = train(net,P,T); |
% обучение сети |
y = sim(net,P); |
% опрос обученной сети |
figure (1); |
|
hold on; |
|
xlabel ('P'); |
|
ylabel ('T');
% прорисовка графика исходных данных и функции сформированной нейронной сетью
plot(P,T,P,y,'o'),grid;
Результаты работы созданной нейронной сети представлены на рис. 6.1.
69
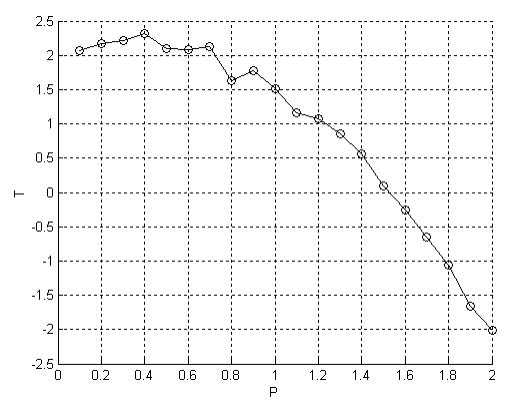
Рис. 6.1. Результат работы нейронной сети
Выводы (пример):
В результате выполнения лабораторной работы я ознакомился с основами теории искусственных нейронных сетей. В среде MATLAB был создан программный код, с помощью которого была построена и обучена нейронная сеть с одним скрытым слоем без обратных связей для аппроксимации таблично заданной функции. Я убедился, что нейронные сети являются одним из мощных математических аппаратов для решения задач аппроксимации функций.
Контрольные вопросы:
1.Дайте определение «нейрона».
2.Что Вы понимаете под обучением нейронной сети?
3.Что такое «Обучающее множество»?
4.Объясните смысл алгоритма обучения с учителем.
5.Что называют аппроксимацией функции?
6.Какие функции в среде MATLAB используются для создания нейронной сети?
70