

Shpori_na_ekzamen_OS
.pdf121
две проблемы.
Во-первых, что если на узле одновременно работает несколько процессов, которым нужен доступ к сети для отправки пакетов? Какой из них получит интерфейсную карту в свое адресное пространство?
Одно решение заключается в том, чтобы отобразить интерфейсную карту на все процессы, которым она нужна, но тогда потребуется специальный механизм предотвращения конфликтов.
Вторая проблема состоит в том, что ядру также может потребоваться доступ к интерфейсной карте, например, для доступа к файловой системе на удаленном узле. Совместное использование интерфейсной карты ядром и пользователями представляет собой неудачную идею даже на основе разделения времени.
Связь между узлом и сетевым интерфейсом
Другой вопрос заключается в том, как пакеты попадают в интерфейсную карту. Самый быстрый способ состоит в использовании микросхемы DMA, размещенной на интерфейсной плате, чтобы просто копировать пакеты в ОЗУ. Недостаток этого метода заключается в том, что контроллер DMA использует не
виртуальное, а физическое адресное пространство и работает независимо от центрального процессора.
Кроме того, если операционная система решает заменить страницу памяти в то время, как контроллер DMA копирует в нее пришедший пакет, то это приведет не только к потере пакета, но и повреждению данных в памяти. Этих проблем можно избежать, фиксируя и освобождая страницы в памяти с помощью системных вызовов, запрещая таким образом на время их свопинг.
В теории та же проблема возникает при работе контроллера DMA диска или другого устройства, но поскольку для них ОС назначает свои буферы, избежать замещения страниц в системных буферах несложно. В данном случае проблема возникает, потому что пользователь настраивает контроллер DMA и управляет им, а операционная система не догадывается, что подмена страницы может оказаться фатальной.
Проблемы DMA можно избежать, если пользовательский процесс сначала зафиксирует одну страницу в начале работы и спросит у системы ее физический адрес. Исходящие пакеты могут сначала копироваться туда, а затем на сетевую интерфейсную плату, но такая излишняя операция копирования почти так же нежелательна, как копирование в ядро.
Если у сетевых карт есть свой собственный процессор, то эти процессоры на плате могут использоваться для ускорения ввода-вывода. Однако следует избегать конфликтов между процессором на плате и центральным процессором.
Коммуникационное программное обеспечение уровня пользователя
Процессы на разных центральных процессорах многомашинной системы общаются, отправляя друг другу сообщения. В своем простейшем виде этим обменом сообщениями явно занимаются процессы пользователя. Другими словами, операционная система предоставляет способ отправки и получения сообщения, а библиотечные процедуры обеспечивают доступность этих системных вызовов для пользовательских процессов.
122
Библиотечные вызовы send и receive
Служба связи может быть минимизирована до двух (библиотечных) вызовов, один для отправки сообщений и один для их получения.
Senc(dest. &mptr): receive(addr. &mptr):
Первая процедура посылает сообщение, на которое указывает указатель tnptr, процессу dest (идентификатор процесса) и блокирует вызывающий ее процесс до тех пор, пока сообщение не будет отправлено. Вторая процедура вызывает блокировку процесса вплоть до получения сообщения. Когда сообщение приходит, оно копируется в буфер, на который указывает mptr, и процесс
разблокируется. Параметр addr указывает адрес, от которого вызывающий процесс ожидает прихода сообщения.
Блокирующие и неблокирующие вызовы
Описанные выше вызовы представляют собой блокирующие вызовы (синхронные), т.к процесс блокируеться до тех пор, пока сообщение не передасться.
Альтернативу блокирующим вызовам составляют неблокирующие вызовы (асинхронные). Если процедура send является неблокирующей, то она возвращает управление вызывающему ее процессу практически немедленно, прежде чем сообщение будет отправлено. Преимущество этой схемы состоит в том, что отправляющий процесс может продолжать вычисления параллельно с передачей сообщения, что позволяет избежать простоя центрального процессора.
Проблема: нельзя изменять содержимое буфера сообщения до тех пор, пока это сообщение не будет полностью отправлено. Решение:
1. копирование ядром сообщения в свой буфер 2. прерывание отправителя, когда сообщение будет отправлено, чтобы известить его об этом факте.
3. копировать содержимое буфера при записи.
Как и send, операция receive также может быть блокирующей и неблокирующей. Блокирующий вызов просто приостанавливает процесс до прибытия сообщения. Если на центральном процессоре одновременно работают несколько пототов, то такой подход является наиболее простым. Неблокирующий вызов receive лишь сообщает ядру, где расположен буфер, и почти сразу же возвращает управление.
Вызов удаленной процедуры
Хотя модель передачи сообщений предоставляет удобный способ структурирования операционной системы многомашинной системы, у нее есть один существенный недостаток: связь между процессами построена на парадигме ввода-вывода. Процедуры send и receive занимаются вводом-выводом, а многие программисты считают ввод-вывод неверной моделью программирования.
Когда процесс на машине 1 вызывает процедуру на машине 2, вызывающий процесс на машине 1 приостанавливается, а на машине 2 выполняется вызванная процедура. Инфа между вызывающим процессом и вызываемой процедурой может передаваться через параметры, или возвращаться в результате процедуры.
123
Распределенная память совместного доступа
При отсутствии общей памяти можно сохранить иллюзию ее наличия при помощи техники, называемой DSM (Distributed Shared Memory — распределенная совместно используемая память). В DSM каждая страница находится в одном из блоков памяти. В DSM адресное пространство разделяется на страницы, которые
распределены между всеми узлами системы. Когда центральный процессор обращается к адресу, не являющемуся локальным, происходит прерывание и программное обеспечение DSM добывает страницу, содержащую данный адрес, и перезапускает команду, вызвавшую страничное прерывание, которая во второй раз завершается успешно.
Ложное совместное использование памяти
Системы DSM во многом напоминают многомашинные системы. В обеих системах при обращении к слову нелокальной памяти блок памяти, содержащий это слово, берется с текущего местоположения и помещается на машину, с которой было произведено обращение. Важный вопрос заключается в том, насколько большим должен быть этот блок памяти? В системах DSM размер передаваемого по сети блока памяти должен быть кратен размеру страницы (так как диспетчер памяти работает со страницами). Подобная работа имитирует страницы большего размера.
У большего размера страниц в системе DSM есть как преимущества: время, требуемое для переноса по сети 4096 байт, не намного больше, чем для переноса 1024 байт, так как существенное время тратится на подготовку этого процесса. Увеличивая передаваемые по сети блоки, часто можно уменьшить количество передаваемых блоков.
Недостаток: ложное совместное использован.Пример: на одной странице содержатся две не имеющие друг к другу отношения переменные, А и В. Процессор 1 пользуется переменной А, читая и записывая ее. А процессор 2 использует переменную В. В такой ситуации страница, содержащая обе переменные, будет постоянно путешествовать от одной машины к другой. Данная проблема заключается в том, что хотя эти переменные и не связаны друг с другом, они оказались на одной странице, поэтому когда какой-либо про-цесс использует одну из этих переменных, он вместе с ней получает и другую.
Планирование многомашинных систем
Вмногомашинной системе у каждого узла есть своя собственная память и свой собственный набор процессов. Центральный процессор 1 не может внезапно решить запустить процесс, расположенный на узле 4.
Вэтом основное отличие многомашинных систем от мультипроцессоров, в которых все процессы работают в одной памяти и могут переключаться на любой центральный процессор уже во время исполнения. Соответственно, следует определить, как назначать процессы узлам, чтобы при этом повысить эффективность системы.
Детерминистический графовый алгоритм
Если известны требования к центральному процессору и памяти, а также матрицей известных объемов обмена данными между каждой парой процессов. Если количество процессов больше количества центральных процессоров, то некоторые процессы должны быть назначены каждому процессору. Идея заключается в том, чтобы минимизировать сетевой трафик.
Система может быть представлена в виде взвешенного графа, каждая вершина которого
124
представляет собой процесс, а каждая дуга — поток сообщений между двумя процессами. Проблема сводится к тому, чтобы найти способ разбиения графа на k непересекающихся подграфов при определенных ограничениях, накладываемых на подграфы. Дуги, идущие от одного подграфа к другому, представляют сетевой трафик. Цель состоит в том, чтобы найти такой вариант разбиения графа на подграфы, который минимизирует сетевой трафик при выполнении всех требований.
Для оптимального разбиения графа на отдельные части следует, видимо, искать группы тесно связанных процессов (с высоким уровнем внутригруппового трафика), но мало взаимодействующие с другими группами (низкий межгрупповой трафик).
Распределенный эвристический алгоритм, инициируемый отправителем
Рассмотрим теперь некоторые распределенные алгоритмы. При использовании одного алгоритма процесс работает на узле, который его создал, если только этот узел не перегружен. Если узел перегружен, он выбирает случайным образом другой узел и запрашивает у него данные о его загрузке. Если загрузка данного узла оказывается ниже определенного уровня, новый процесс отправляется туда. Если данный узел также уже достаточно загружен, выбирается другая машина. Смысл в том, чтобы перегруженные узлы могли попытаться избавится от лишней нагрузки.
В условиях сильной загруженности все машины будут постоянно посылать другим машинам запросы об их загрузке в тщетной попытке найти кого-нибудь, кто согласится взять у них часть работы. Мало кому из процессов удастся уменьшить свою нагрузку, но сами попытки поиска помощников могут оказать существенную дополнительную нагрузку на сеть.
Распределенный эвристический алгоритм, инициируемый получателем
Передача процесса менее загруженной машине инициируется получателем, то есть менее загруженной машиной. Когда завершается очередной процесс, при таком алгоритме система проверяет, достаточно ли у нее работы. Если нет, она случайным образом выбирает машину и просит у нее работу. Если этой машине нечего предложить, проверяется другая машина. Если за n попыток работу найти не удалось, узел временно прекращает поиск, выполняет любую работу, которая у него есть, после чего весь цикл повторяется после завершения очередного процесса. Если работы у узла не остается совсем, он простаивает некоторое время, а спустя определенный интервал времени снова принимается искать работу.
Преимущество: он не оказывает дополнительной нагрузки на сеть в критический период. В данной схеме вероятность появления незагруженной машины в перегруженной системе мала. Однако если такое вдруг случается, простаивающая машина легко найдет себе работу в такой ситуации.
Возможна комбинация обоих алгоритмов, в которой машины будут пытаться избавиться от лишней работы и получить работу, когда ее не хватает.
Алгоритм торгов
Подобие миниатюрной экономики, с продавцами и покупателями услуг и ценами, устанавливаемыми спросом и предложением. Процессы должны покупать процессорное время для выполнения своей работы, и узлы, продающие свои циклы процессоров на
125
аукционе тому, кто предложит наивысшую цену.
Каждый узел рекламирует свою приблизительную цену, публикуя ее в файле, доступном для чтения всем процессам. Эта цена не является фиксированной, но она дает представление об уровне предоставляемых услуг (в действительности это цена, которую заплатил предыдущий покупатель). У разных узлов цены могут различаться в зависимости от их быстродействия, объема оперативной памяти, наличия быстрого аппаратного обеспечения для обработки операций с плавающей точкой и других свойств.
Когда процесс хочет запустить дочерний процесс, он ищет узел, предлагающий требующиеся ему в данный момент услуги. Затем он определяет набор узлов, услугами которых он может воспользоваться. Из этого набора процесс выбирает лучшего кандидата, где слово «лучший» может означать самого дешевого, быстро-го или с наилучшим соотношением производительность/цена. Процесс формирует заявку с предложением цены и посылает ее первому кандидату. Процессоры собирают все
заявки, посланные им, и делают свой выбор, как правило, останавливаясь на заявке с самой высокой ценой. Победители и проигравшие информируются о сделанном выборе. Победивший процесс исполняется. Затем обновляется опубликованная цена сервера.
126
19. Распределенные системы
Понятие распределенной системы
По утверждению известного специалиста в области информатики Э. Таненбаума, не существует общепринятого и в то же время строгого определения распределенной системы. Некоторые остряки утверждают, что распределенной является такая вычислительная система, в которой неисправность компьютера, о существовании которого пользователи ранее даже не подозревали, приводит к остановке всей их работы. Значительная часть распределенных вычислительных систем, к сожалению, удовлетворяют такому определению, однако формально оно относится только к системам с уникальной точкой уязвимости ( single point of failure ).
Часто при определении распределенной системы во главу угла ставят разделение ее функций между несколькими компьютерами. При таком подходе распределенной является любая вычислительная система, где обработка данныхразделена между двумя и более компьютерами. Основываясь на определении Э. Таненбаума, несколько более узко распределенную систему можно определить как набор соединенных каналами связи независимых компьютеров, которые с точки зрения пользователя некоторого программного обеспечения выглядят единым целым.
Такой подход к определению распределенной системы имеет свои недостатки. Например, все используемое в такой распределенной системе программное обеспечение могло бы работать и на одном единственном компьютере, однако с точки зрения приведенного выше определения такая система уже перестанет быть распределенной. Поэтому понятие распределенной системы, вероятно, должно основываться на анализе образующего такую систему программного обеспечения.
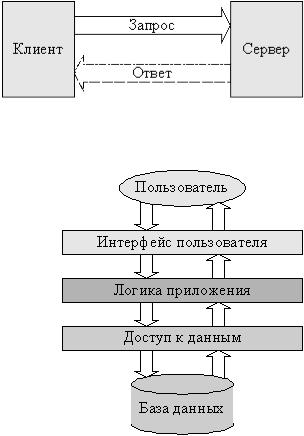
Как основу описания взаимодействия двух сущностей рассмотрим общую модель взаимодействия клиент-сервер, в которой одна из сторон (клиент) инициирует обмен данными, посылая запрос другой стороне (серверу). Сервер обрабатывает запрос и при необходимости посылает ответ клиенту
(рис. |
1.1). |
||
|
|
|
|
Рис. 1.1. |
Модель взаимодействия клиент сервер |
||
Взаимодействие в рамках модели клиент сервер может быть как синхронным, когда клиент ожидает завершения обработки своего запроса сервером, так и асинхронным, при котором клиент посылает серверу запрос и продолжает свое выполнение без ожидания ответа сервера. Модель клиента и сервера может использоваться как основа описания различных взаимодействий.
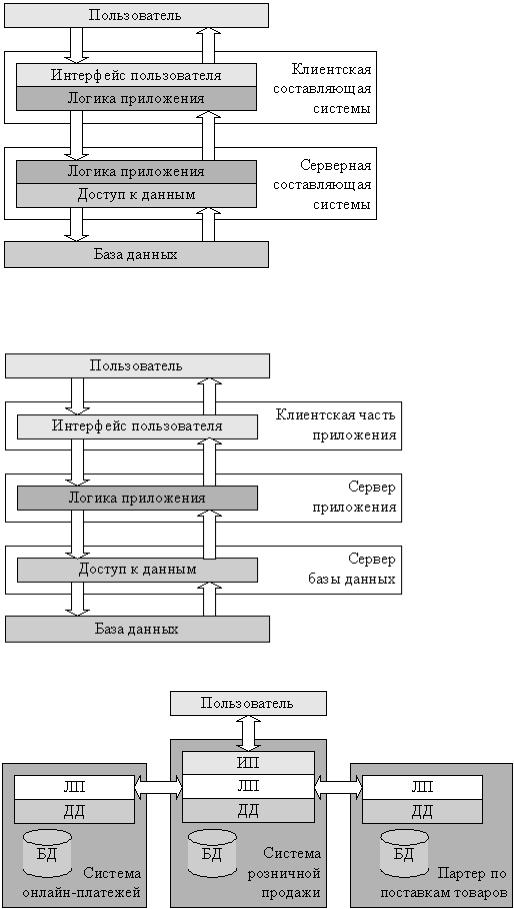
Для данного курса важно взаимодействие составных частей программного обеспечения, образующего распределенную систему. Рис. 1.2. Логические уровни приложения
Рассмотрим некое типичное приложение, которое в соответствии с современными представлениями может быть разделено на следующие логические уровни (рис. 1.2): пользовательский интерфейс (ИП),
логика приложения (ЛП) и доступ к данным (ДД), работающий с базой данных (БД). Пользователь системы взаимодействует с ней через интерфейс пользователя, база данных
127
хранит данные, описывающие предметную область приложения, а уровень логики приложения реализует все алгоритмы, относящиеся к предметной области.
Поскольку на практике разных пользователей системы обычно интересует доступ к одним и тем же данным, наиболее простым разнесением функций такой системы между несколькими компьютерами будет разделение логических уровней приложения между одной серверной частью приложения, отвечающим за доступ к данным, и находящимися на нескольких компьютерах клиентскими частями, реализующими интерфейс пользователя. Логика приложения может быть отнесена к серверу, клиентам, или разделена между ними (рис. 1.3).
Рис. 1.3. Двухзвенная архитектура Архитектуру построенных по такому принципу приложений называют клиент
серверной или двухзвенной. На практике подобные системы часто не относят к классу распределенных, но формально они могут считаться простейшими представителями распределенных систем.
Развитием архитектуры клиентсервер является трехзвенная архитектура, в которой интерфейс пользователя, логика приложения и доступ к данным выделены в самостоятельные составляющие системы, которые могут работать на независимых компьютерах (рис. 1.4).
Рис. 1.4. Трехзвенная архитектура Запрос пользователя в подобных системах последовательно обрабатывается
клиентской частью системы, сервером логики приложения и сервером баз данных. Однако обычно под
распределенной системой понимают системы с более сложной архитектурой, чем трехзвенная.
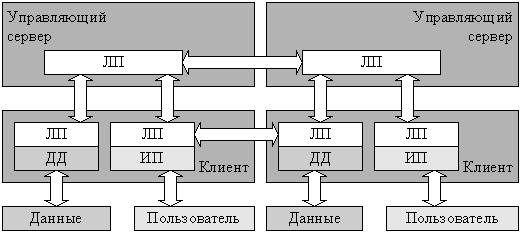
Рис. 1.5. Распределенная система розничных продаж
128
Применительно к приложениям автоматизации деятельности предприятия, распределенными обычно называют системы с логикой приложения, распределенной между несколькими компонентами системы, каждая из которых может выполняться на отдельном компьютере. Например, реализация логики приложения системы розничных продаж должна использовать запросы к логике приложения третьих фирм, таких как поставщики товаров, системы электронных платежей или банки, предоставляющие потребительские кредиты (рис. 1.5).
Таким образом, в обиходе под распределенной системой часто подразумевают рост многозвенной архитектуры "в ширину", когда запросы пользователя не проходят последовательно от интерфейса пользователя до единственного сервера баз данных.
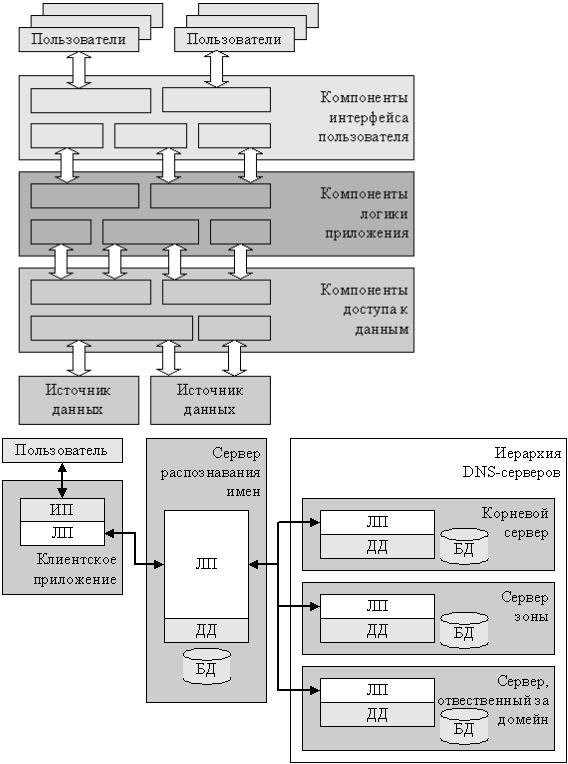
В качестве другого примера распределенной системы можно привести сети прямого обмена данными между клиентами ( peer-to-peer networks ). Если предыдущий пример имел "древовидную" архитектуру, то сети прямого обмена организованы более сложным образом, рис. 1.6.
Подобные системы являются в настоящий момент, вероятно, одними из крупнейших существующих распределенных систем, объединяющие миллионы компьютеров.
Рис. 1.6. Система прямого обмена данными между клиентами пределение распределенной системы. Программные компоненты
В распределенных системах функции одного уровня приложения могут быть разнесены между несколькими компьютерами. С другой стороны, программное обеспечение, установленное на одном компьютере, может отвечать за выполнение функций, относящихся к разным уровням. Поэтому подход к определению распределенной системы, считающей ее совокупностью компьютеров, условен. Для описания и реализации распределенных систем было введено понятие программной компоненты.
Программная компонента – это единица программного обеспечения, исполняемая на одном компьютере в пределах одного процесса, и предоставляющая некоторый набор сервисов, которые используются через ее внешний интерфейс другими компонентами, как выполняющимися на этом же компьютере, так и на удаленных компьютерах. Ряд компонент пользовательского интерфейса предоставляют свой сервис конечному пользователю. Набор требований, которым в наилучшем случае должна удовлетворять распределенная вычислительная система.
|
|
|
129 |
Открытость. |
|
|
|
Масштабируемость. |
|
||
Поддержание |
логической |
||
целостности данных. |
|
||
Устойчивость. |
|
||
Безопасность. |
|
||
Эффективность. |
|
||
Система |
|
имен |
– |
организованная |
|
иерархически |
|
распределенная |
|
система, |
с |
дублированием |
|
всех функций |
|
между двумя и более серверами. |
|||
Рис. 1.8. Система DNS |
|
||
Запрос |
пользователя |
на |
|
преобразование |
|
|
имени |
(например, w3c.org ) в сетевой адрес передается серверу распознавания имен поставщика услуг интернета.
Сервер
распознавания имен по очереди опрашивает серверы из иерархии службы имен. Опрос начинается с корневых серверов, который возвращает адреса серверов,
ответственных за зону домена. Затем опрашивается сервер, ответственный за зону (в данном случае – .org ), возвращающий адреса серверов, ответственных за домен второго уровня, и так далее. Серверы имен кешируют информацию о соответствии имен и адресов для уменьшения нагрузки на систему. Программное обеспечение на компьютере пользователя обычно имеет возможность соединиться с как минимум двумя различными серверами распознавания имен.
Тем не менее, и в системе распознавания имен не все требования к распределенным системам выполнены. В частности, она не содержит каких-либо явных механизмов обеспечения безопасности. Это приводит к регулярным атакам на серверы имен в надежде вывести их из строя, например, большим количеством запросов.
Давайте очень кратко опишем, какие функции выполняют различные уровни модели
OSI/ISO:
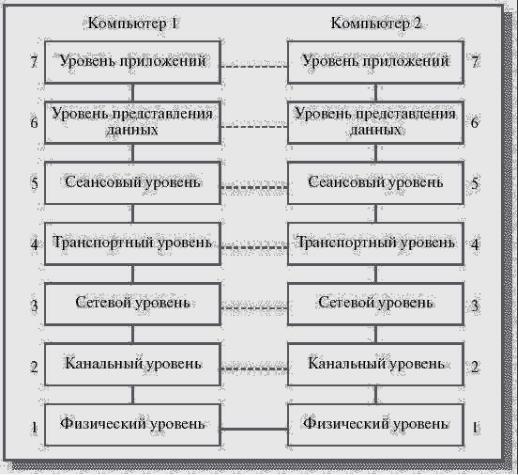
130
·Уровень 1 – физический.
·Уровень 2 – канальный.
·Уровень 3 – сетевой
·Уровень 4 – транспортный
·Уровень 5 – сеансов
·Уровень 6 – уровень представления данных.
·Уровень 7 – прикладной.
·
Рис. 14.1. Семиуровневая эталонная модель OSI/ISO
Сетевые протоколы
Набор правил, с помощью которых общаются компьютеры, называется протоколом. Существует множество протоколов, включая протоколы для общения маршрутизатора с маршрутизатором, хоста с хостом и т. д.
Все современные сети используют то, что называется стеком протоколов, то есть разные протоколы на разных уровнях. На разных уровнях протоколы занимаются различными вопросами. Так, на нижнем уровне протоколы описывают, как определить, где в битовом потоке начинается и заканчивается пакет данных. На более высоком уровне протоколы занимаются выбором маршрута пакета по сложным сетям от отправителя до получателя. А на еще более высоком уровне они гарантируют, что все пакеты сообщения прибыли правильно и в нужном порядке.
Так как большинство распределенных систем используют в качестве основы Интернет, ключевыми протоколами этих систем являются два главных протокола Интернета: IP и TCP. Протокол IP (Internet Protocol — Интернет-протокол) представляет собой дейтаграммный протокол, в котором отправитель вбрасывает
всеть дейтаграмму размером до 64 Кбайт и надеется, что она достигнет получателя. Никаких гарантий не предоставляется. Дейтаграмма может фрагментироваться по пути на пакеты меньшего размера. Эти пакеты перемещаются по Интернету независимо друг от