

metoda / Ml_ITIn_2013
.pdf231
Задание 5. Использование псевдонимов имен таблиц (AS)
Часто бывает очень удобно, а порой и необходимо обращаться к таблицам под другими именами. Такие имена называются псевдонимами (aliase). Их можно создать в самом начале запроса, а потом пользоваться по мере необходимости. Псевдонимы очень удобны, все равно, что ярлык на рабочем столе. Если запрос, показанный на рис. 3.245 переписать с использованием псевдонимов (рис. 3.2460), то его объем становится меньше.
select customers . name
from customers, orders, order_items, books where customers.customerid = orders.customerid and orders.orderid = order_items.orderid
and order_items.isbn = books.isbn and books.title like '%Java%';
Рис. 3.245. Запрос без использования псевдонимов.
Указывая таблицы, в фразе FROM, мы за именем таблицы вставляем конструкцию as, присваивая таблице псевдоним (короткое имя).
select с.name
from customers as с, orders as о, order_iterns as oi, books as b where с.customerid = о.customerid
and о.orderid = oi.orderid and oi.isbn = b.isbn
and b.title like '%Java%' ;
Рис. 3.246. Запрос с использованием псевдонимов.
Кроме того, псевдонимы можно давать столбцам, однако к этому мы вернемся после того, как рассмотрим обобщенные функции.
Табличные псевдонимы необходимы в случае соединения таблицы с самой собой. А такой подход очень удобен для поиска строк в той же таблице, в которой есть одинаковые значения. Если требуется найти клиентов, живущих в одном городе, скажем, с целью создания читательского клуба, можно присвоить одной и той же таблице Customers два разных псевдонима:
select sl.name, s2.name, sl.city
from customers as sl, customers as s2 where sl.city = s2.city
and sl.name != s2.name;
Рис. 3.247. Запрос с использованием 2-х псевдонимов на одной таблице.
Чтобы раскрыть суть соединения таблицы самой с собой, добавим в таблицу Customers (Клиенты) еще одну запись (рис. 3.248).

232
Рис. 3.248. Запрос на добавление нового клиента.
Далее исполним запрос на самосоединение таблиц:
Рис. 3.249. Список клиентов из одного города.
Мы делаем вид, что таблица Customers — это на самом деле две разные таблицы, sl и s2, и выполняем соединение по столбцу City. Второе условие, sl.name != s2.name, необходимо для того, чтобы в результате запроса не выдавалось соответствие клиента самому себе.
Резюме по типам соединениий
Мы рассмотрели только самые основные, хотя существуют еще несколько соединений, представленных в таблице на рис. 3.250.
Название |
Описание |
Декартово |
Все комбинации всех строк во всех таблицах. В случае |
произведение |
применения между именами таблиц ставят запятые и не |
|
употребляют конструкцию WHERE. |
Полное |
Аналогично предыдущему. |
соединение |
|
Перекрестное |
Аналогично предыдущему. Также может использоваться с |
соединение |
указанием ключевых слов CROSS JOIN между названиями |
|
объединяемых таблиц. |
Внутреннее |
Семантически эквивалентно запятой. Может использоваться |
соединение |
с указанием ключевых слов INNER JOIN. Без условия |

|
233 |
|
|
|
WHERE эквивалентно полному объединению. Обычно при |
|
истинно внутреннемобъединении задается условие WHERE. |
Соединение |
Использует условное выражение со знаком = для |
по равенству |
Соответствия в объединении строк из разных таблиц. В SQL |
|
в этом объединении применяется конструкция WHERE. |
Соединение |
Старается уравнивать строки в таблицах и выискивает |
по |
несовпадающие строки со значениями NULL. В SQL |
остатку |
используется с ключевыми словами LEFT JOIN. |
|
Предназначено для поиска отсутствующих значений. |
|
Аналогично можно употреблять RIGHT JOIN. |
|
Рис. 3.250. Типы соединеий в MySQL. |
Задание 6. Извлечение данных в определенном порядке
Если строки, извлеченные по запросу, должны перечисляться в определенном порядке, для этого используется конструкция ORDER BY оператора SELECT. Эта особенность удобна для представления результатов запроса в удобочитабельном формате.
Конструкция ORDER BY применяется для сортировки строк в столбцах, указанных в конструкции SELECT. Например,
select name, address from customers order by name ;
Рис. 3.251. Сортировка результата с помощью ORDER BY в MySQL.
Рис. 3.252. Результат сортировки результата с помощью ORDER BY.
Такой запрос представит имена клиентов в алфавитном порядке по именам name.
Примечание. Обратите внимание, что в таком случае, поскольку имена состоят из имени и фамилии, отсортированы они будут по имени. Если вы хотите сортировки по фамилии (которая стоит второй), нужно, чтобы имя и фамилия хранились в двух разных полях.

234
По умолчанию порядок сортировки идет по возрастанию (от а до z или по возрастанию числовых значений). Это можно указать ключевым словом
ASC (от англ, ascending):
select customerid,address, name from customers
order by address asc;
Рис. 3.253. Результат сортировки результата с помощью ORDER BY ASC.
Изменить порядок сортировки на обратный можно с помощью другого ключевого слова — DESC (от англ, descending):
select address, name from customers
order by address desc;
Рис. 3.254 13.27. Результат сортировки результата с помощью ORDER BY DESC.
Сортировать можно и по нескольким столбцам. Вместо названий можно использовать псевдонимы столбцов, и даже их порядковые номера (например, 3 — для третьего столбца в таблице) см. [7].

235
Задание 7. Группировка и агрегирование данных
Нередко необходимо подсчитать, сколько строк присутствует в определенном наборе, или каково среднее значение какого-нибудь столбца
— скажем, средняя цена каждого заказа. В MySQL имеется набор функций агрегирования, которые неплохо подходят для выполнения задач подобного рода.
Эти функции агрегирования можно применять как для таблицы в целом, так и для групп данных внутри таблицы.
Наиболее часто используемые функции перечислены в таблице показанной на рис. 3.255.
Название |
Описание |
AVG (столбец) |
Средняя величина значений в определенном столбце. |
COUNT |
При указании столбца выдается количество числовых |
(элементы) |
ненулевых) значений в этом столбце. Если перед |
|
названием столбца вставить слово DISTINCT, выдается |
|
только количество конкретных значений в столбце. |
|
Если указать COUNT (*) — подсчет строк будет |
|
производиться независимо от нулевых значений. |
MIN (столбец) |
Минимальное значение в столбце. |
МАХ (столбец) |
Максимальное значение в столбце. |
STD (столбец) |
Стандартное отклонение значений в столбце. |
SUM (столбец) |
Сумма значений в столбце. |
Рис. 3.255. Функции агрегирования в MySQL.
Взглянем на несколько примеров, начиная с AVG. Среднюю величину всех заказов можно высчитать так:
select avg (amount) from orders;
Рис. 3.256. Результат AVG по столбцу amount таблицы orders.
Чтобы получить более детальную информацию, можно воспользоваться конструкцией GROUP BY. Это позволит посмотреть среднюю величину заказа по группам, например, по номеру клиента, что даст информацию о том, кто из клиентов делает самые крупные заказы:

236
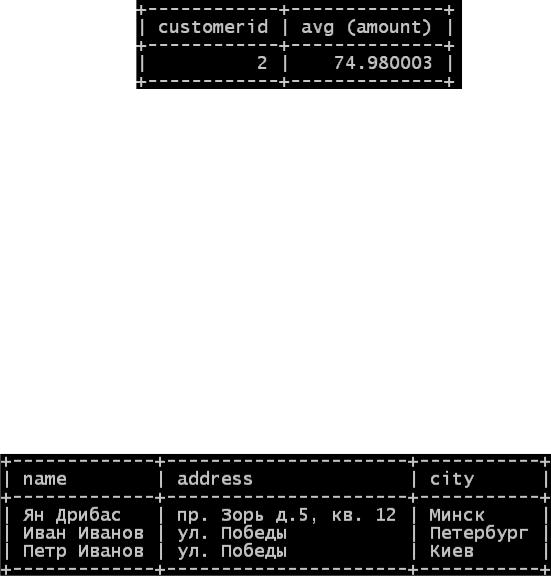
select customerid, avg (amount) from orders
group by customerid;
При использовании конструкции GROUP BY с функцией агрегирования это фактически меняет поведение функции. Вместо того чтобы выдавать среднюю величину заказов в таблице, такой запрос даст информацию по средней величине заказа каждого клиента (а если точнее,
каждого customerid)
Рис. 3.257. Результат AVG с группировкой по Клиентам.
Единственное, что стоит отметить при использовании функций группировки и агрегирования: если используется функция агрегирования или конструкция GROUP BY в ANSI SQL, в конструкции SELECT будут присутствовать только функции агрегирования и столбцы, указанные в конструкции GROUP BY. Если требуется использовать столбец в конструкции GROUP BY, он должен быть указан в конструкции SELECT.
На самом деле MySQL обеспечивает гораздо большую свободу действий, поддерживая расширенный синтаксис, который дает возможность убирать ненужные элементы из конструкции SELECT.
Вдобавок к группировке и агрегированию данных есть все шансы проверить результат агрегирования с использованием конструкции HAVING. Она следует сразу после конструкции GROUP BY и похожа на WHERE, но только применяется к группам и множествам.
Чтобы расширить предыдущий пример, скажем, получением информации, кто из клиентов произвел заказ в среднем больше чем на $50, можем воспользоваться следующим запросом:
select customerid, avg (amount) from orders
group by customerid having avg (amount) > 50;
237
Заметьте, конструкция HAVING обращается к группам. Такой запрос выдаст следующий результат:
Рис. 3.258. Результат AVG с группировкой по HAVING.
Выбор количества отображаемый строк
Одна конструкция оператора SELECT, которая может оказаться особенно полезной в Web-приложениях — это конструкция LIMIT. Ее используют для указания, сколько строк результата следует отображать. Необходимы два параметра: номер строки, с которой следует начать, и количество строк.
Следующий запрос иллюстрирует применение LIMIT: select name, address, city
from customers limit 2, 3;
Запрос можно интерпретировать так: "Выбрать имена среди клиентов, в результате отобразить три строки, начиная со строки 2". Не забывайте, что нумерация строк начинается с нуля.
Рис. 3.259. Результат применения LIMIT.
Это очень удобная конструкция для Web-приложений. Ее принцип точно такой же, как и в случае, когда покупатель листает каталог и хочет видеть на одной странице только 10 пунктов.
Примечание. Обратите внимание, что LIMIT в стандарте ANSI SQL отсутствует, потому его использование приводит к несовместимости кода со многими реляционными СУБД.

238
Задание 8. Обновление записей в базе данных (UPDATE)
Помимо того, что данные необходимо извлекать из базы данных, их еще необходимо периодически обновлять. Например, иногда требуется повысить цены на книги в базе данных. Это можно сделать, используя оператор UPDATE.
Типовая форма этого оператора выглядит так:
UPDATE tablename
SET columnl=expressionl, column2=expression2, [WHERE condition]
[LIMIT number]
Основная идея заключается в обновлении таблицы с именем tablename, изменяя каждый указанный столбец column соответствующим выражением expression. Конструкцией WHERE UPDATE можно ограничить до работы с определенными строками, а конструкцией LIMIT обозначить количество строк, которые нужно обновить.
Давайте рассмотрим несколько примеров.
Если мы хотим повысить цену всех книг на 10%, можно воспользоваться оператором UPDATE без конструкции WHERE:
Исходное состояние таблицы BOOKS приведено ниже.
Рис. 3.260. Состояние таблицы BOOKS до модификации данных.
update books
set price=price * 1.1;
Рис. 3.261. Состояние таблицы BOOKS после модификации данных.

239
Если же требуется изменить одну строку, скажем, адрес некоторого клиента, можно поступить таким образом:
update customers
set address = 'ул. Победы д.7, кв.7' where customerid = 4;
Так, например, состояние таблицы показанное на рис. 3.248 будет приведено к виду представленному на рис 3.262.
Рис. 3.262. Результат модификации данных в таблице Customers.
240
Задание 9. Изменение таблиц после создания (ALTER TABLE)
Кроме обновления данных в строках, может потребоваться изменить структуру самой таблицы в базе данных. Для этого применяется очень гибкий оператор ALTER TABLE. Базовая его форма такова:
ALTER TABLE tablename alteration [, alteration ...]
В ANSI SQL один оператор ALTER TABLE может осуществить только одно преобразование, а вот в MySQL подобных ограничений нет. Разные конструкции преобразования могут изменять разные аспекты таблицы.
Типы преобразования, осуществляемые оператором ALTER TABLE, перечислены в таблице на рис. 3.263.
Синтаксис |
Описание |
|
|
|
ADD [COLUMN] column_description |
Добавить столбец в указанное место |
|||
[FIRST | AFTER column ] |
(если место не указано, столбец |
|||
|
добавляется в конец). Обратите |
|||
|
внимание, |
column_description |
||
|
требует имени и типа, точно так же, |
|||
|
как при работе с оператором |
|||
|
CREATE. |
|
|
|
ADD [COLUMN] |
Добавить |
один |
или |
несколько |
(column_description,column_description, |
столбцов в конец таблицы. |
|||
...) |
|
|
|
|
ADD INDEX [index] (column, |
Добавить |
индекс |
в |
указанный |
...)(столбцы) таблицы. |
столбец |
|
|
|
ADD PRIMARY KEY (column, ...) |
Сделать указанный столбец (ы) |
|||
|
первичным ключом таблицы. |
|||
ADD UNIQUE [index] (column, ...) |
Добавить |
уникальный |
индекс в |
|
(столбцы) таблицы. |
указанный столбец |
|
|
|
ALTER [COLUMN] column {SET |
Добавить или удалить значение по |
|||
DEFAULT value \ DROP DEFAULT} |
умолчанию определенного столбца. |
|||
CHANGE [COLUMN] column |
Изменить столбец с именем column |
|||
new_column_description |
так, чтобы он получил указанное |
|||
|
описание. Это можно использовать |
|||
|
для изменения имени столбца, |
|||
|
поскольку |
column_description |
||
|
включает в себя имя. |
|
||
MODIFY [COLUMN] |
Похоже на CHANGE. Используется |
|||
column_description |
для изменения типов столбцов, но |
|||
|
не имен. |
|
|
|
DROP [COLUMN] column |
Удалить указанный столбец. |
|||
DROP PRIMARY KEY |
Удалить первичный индекс (не |
|||
|
столбец!). |
|
|
|