

Преобразователи (reducers)…
Преобразователь (reducer) – это переменная, которая может быть безопасно использована несколькими нитями, запущенными параллельно в разных обработчиках.
Свойства преобразователей:
–Обеспечивают надежный доступ к нелокальным переменным без «гонок» данных.
–Не требуют явного применения примитивов взаимной блокировки разделяемых переменных.
–Сохраняется последовательная семантика кода.
Нижний Новгород, 2015 |
Элементы оптимизации прикладных программ для Intel Xeon Phi. Intel Compiler |
31 |

Преобразователи (reducers)…
#include <cilk/cilk.h> #include <cilk/reducer_opadd.h>
cilk::reducer_opadd<unsigned int> n(1); void compute() {
n++;
} |
|
int main(int argc, char* argv[]) { |
|
int k = 0; // нить 1 |
|
cilk_spawn compute(); // нить 2 |
|
n++; // нить 3 – продолжение 1 |
|
cilk_sync; |
|
return 0; // нить 4 |
1 |
} |
|
2
4
3
Нижний Новгород, 2015 |
Элементы оптимизации прикладных программ для Intel Xeon Phi. Intel Compiler |
32 |

Преобразователи (reducers)
Преобразователи математических операций и операций работы со строками:
reducer_opadd / reducer_string / …
Преобразователи выбора минимума и максимума: reducer_max / reducer_max_index / …
Преобразователи для логических операций: reducer_opor / reducer_opand / reducer_opxor
Преобразователи для работы со списками: reducer_list_append / reducer_list_prepend
Запись в выходной поток: reducer_ostream
Нижний Новгород, 2015 |
Элементы оптимизации прикладных программ для Intel Xeon Phi. Intel Compiler |
33 |

3. Неявная схема работы с памятью
Нижний Новгород, 2015 |
Элементы оптимизации прикладных программ для Intel Xeon Phi. Intel Compiler |
34 |
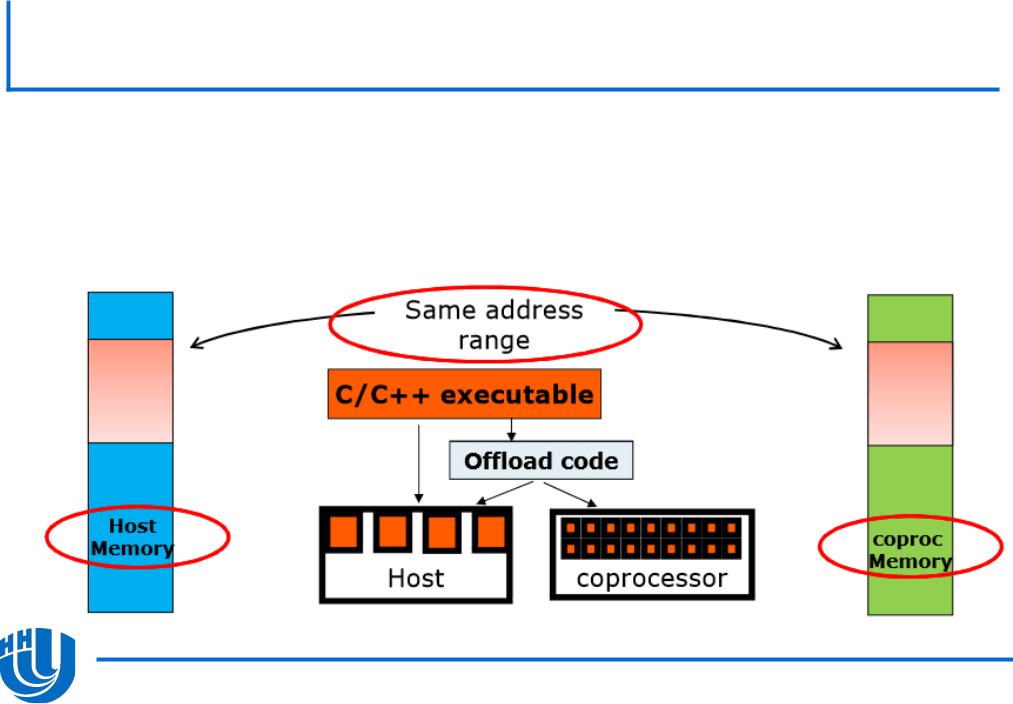
Неявная схема работы с памятью…
Основана на использовании ключевых слов
Позволяет работать со сложными типами данных
Поддерживается только в языках C/C++
Нижний Новгород, 2015 |
Элементы оптимизации прикладных программ для Intel Xeon Phi. Intel Compiler |
35 |

Неявная схема работы с памятью…
Для выделения участка разделяемой памяти динамически необходимо воспользоваться функциями:
void *_Offload_shared_malloc(size_t size);
void *_Offload_shared_aligned_malloc(size_t size, size_t alignment);
Удаление памяти выполняется соответственно с помощью функций:
void _Offload_shared_free(void *p);
void _Offload_shared_aligned_free(void *p);
Для использования данных функций необходимо подключить offload.h файл.
Нижний Новгород, 2015 |
Элементы оптимизации прикладных программ для Intel Xeon Phi. Intel Compiler |
36 |
Неявная схема работы с памятью: _Cilk_shared
Что |
Синтаксис |
Функции |
int _Cilk_shared f(int x) |
|
{ return x + 1; } |
Глобальные |
_Cilk_shared int x = 0; |
переменные |
|
Статические |
static _Cilk_shared int x; |
переменные |
|
Классы |
class _Cilk_shared x {…}; |
 Семантика
Семантика
Компиляция для CPU и MIC, функция может быть вызвана на любой стороне
Переменная доступна на обеих сторонах
Переменная доступна на обеих сторонах, видна только в рамках файла/функции
Поля, методы и операторы класса доступны на обеих сторонах
Указатели |
на |
int _Cilk_shared *p; |
Локальный |
указатель |
на |
|
разделяемые данные |
|
|
разделяемые данные |
|
||
Разделяемые |
|
int* _Cilk_shared p; |
Разделяемый |
указатель, |
должен |
|
указатели |
|
|
|
указывать на разделяемые данные |
||
Блоки кода |
|
#pragma |
offload_attribute(push, |
Аналог _Cilk_shared для целого |
||
|
|
target(mic)) |
|
блока кода |
|
|
…
#pragma offload_attribute(pop)
Нижний Новгород, 2015 |
Элементы оптимизации прикладных программ для Intel Xeon Phi. Intel Compiler |
37 |

Неявная схема работы с памятью: _Cilk_offload
Функциональность |
Пример |
|
Описание |
|
|
|||
Вызов |
функции |
на x = _Cilk_offload func(y); |
Функция выполняется |
на |
||||
сопроцессоре |
|
|
|
|
сопроцессоре, |
если |
это |
|
|
|
|
|
|
|
возможно |
|
|
|
|
|
x |
|
= |
Функция |
должна |
|
|
|
|
_Cilk_offload_to(card_num) |
выполниться на указанном |
||||
|
|
|
func(y); |
|
|
сопроцессоре |
|
|
Асинхронный |
вызов |
на x |
= |
_Cilk_spawn |
Неблокирующее |
|
||
сопроцессоре |
|
_Cilk_offload func(y); |
выполнение |
|
на |
|||
|
|
|
|
|
|
сопроцессоре |
|
|
Параллельный |
цикл |
for _Cilk_offload |
_Cilk_for(i=0; |
Цикл |
выполняется |
|||
на сопроцессоре |
i<N; ++i) |
|
параллельно |
|
на |
|||
{ a[i] = b[i] + c[i]; } |
сопроцессоре |
|
Нижний Новгород, 2015 |
Элементы оптимизации прикладных программ для Intel Xeon Phi. Intel Compiler |
38 |

Неявная схема работы с памятью
Нижний Новгород, 2015 |
Элементы оптимизации прикладных программ для Intel Xeon Phi. Intel Compiler |
39 |

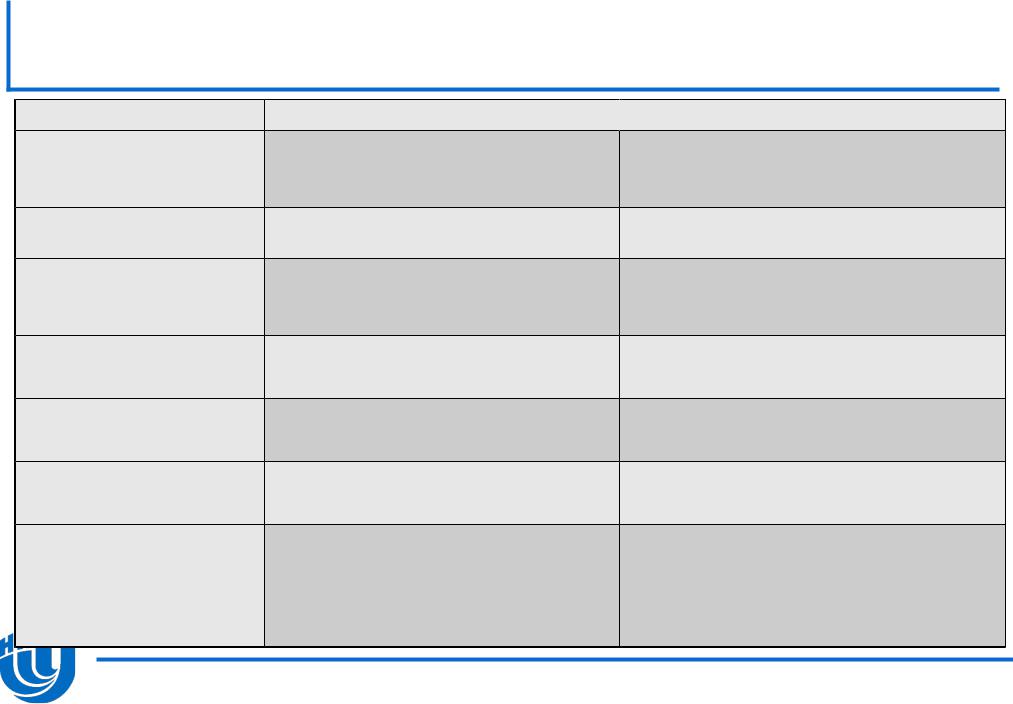
Сравнение явной и неявной схемы
|
|
|
Явная схема |
|
|
|
Неявная схема |
|
|
Типы данных, для |
которых |
Скаляры, массивы, структуры с |
Все типы данных |
|
|||||
возможно |
автоматическое |
возможностью |
побитового |
|
|
||||
копирование |
|
|
копирования |
|
|
|
|
|
|
Когда происходит |
передача |
Пользователь |
может |
явно |
Разделяемые |
данные |
|||
данных |
|
|
контролировать |
передачу |
синхронизируются в начале и в |
||||
|
|
|
данных для |
каждой |
Offload |
конце операторов _Cilk_offload |
|||
|
|
|
директивы |
|
|
|
|
|
|
Когда Offload код копируется |
При первом |
вызове |
#pragma |
В начале работы программы |
|||||
на сопроцессор |
|
offload |
|
|
|
|
|
|
|
Поддержка |
|
языков |
Fortran, |
C, |
C++ |
(без |
C, C++ |
|
|
программирования |
|
возможности |
|
передачи |
|
|
|||
|
|
|
объектов класса) |
|
|
|
|
||
Синтаксис |
|
|
Директивы |
#pragma |
|
offload |
Ключевые слова _Cilk_shared и |
||
|
|
|
(С/C++) и !dir$ offload (Fortran) |
_Cilk_offload |
|
||||
Используется для… |
|
Передачи непрерывных блоков |
Передачи сложных |
структур |
|||||
|
|
|
данных |
|
|
|
|
данных или многих маленьких |
|
|
|
|
|
|
|
|
|
участков данных |
|
Нижний Новгород, 2015 |
Элементы оптимизации прикладных программ для Intel Xeon Phi. Intel Compiler |
40 |